 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-context learning to predict critical transitions in dynamical systems
May 12, 2026Critical transitions - abrupt, often irreversible changes in system dynamics - arise across human and natural systems, often with catastrophic consequences. Real-world observations of such shifts remain scarce, preventing the development of reliable early warning systems. Conventional statistical and spectral indicators, such as increasing variance, tend to fail under realistic conditions of limited data and correlated noise, whereas existing deep learning classifiers do not extrapolate beyond their training data distribution. In this work, we introduce TipPFN, an in-context learning (ICL) framework that uses a prior-data fitted network to infer a system's proximity to a critical transition. Trained on our novel synthetic data generator, which is based on canonical bifurcation scenarios coupled to diverse, randomized stochastic dynamics, TipPFN flexibly capitalizes on contexts of various sizes, complexity and dimensionalities. We demonstrate robust, state-of-the-art early detection of critical transitions in previously unseen tipping regimes, sim-to-real examples, and real-world observations in both ICL and zero-shot settings.
Generative Adversarial Learning of Sinkhorn Algorithm Initializations
Dec 06, 2022



The Sinkhorn algorithm (arXiv:1306.0895) is the state-of-the-art to compute approximations of optimal transport distances between discrete probability distributions, making use of an entropically regularized formulation of the problem. The algorithm is guaranteed to converge, no matter its initialization. This lead to little attention being paid to initializing it, and simple starting vectors like the n-dimensional one-vector are common choices. We train a neural network to compute initializations for the algorithm, which significantly outperform standard initializations. The network predicts a potential of the optimal transport dual problem, where training is conducted in an adversarial fashion using a second, generating network. The network is universal in the sense that it is able to generalize to any pair of distributions of fixed dimension after training, and we prove that the generating network is universal in the sense that it is capable of producing any pair of distributions during training. Furthermore, we show that for certain applications the network can be used independently.
Training Generative Networks with general Optimal Transport distances
Oct 01, 2019
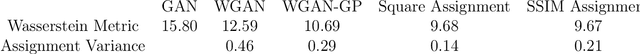
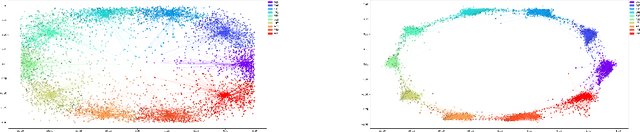
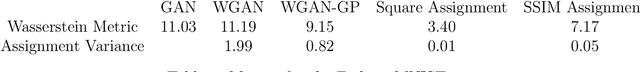
We propose a new algorithm that uses an auxiliary Neural Network to calculate the transport distance between two data distributions and export an optimal transport map. In the sequel we use the aforementioned map to train Generative Networks. Unlike WGANs, where the Euclidean distance is implicitly used, this new method allows to use any transportation cost function that can be chosen to match the problem at hand. More specifically, it allows to use the squared distance as a transportation cost function, giving rise to the Wasserstein-2 metric for probability distributions, which has rich geometric properties that result in fast and stable gradients descends. It also allows to use image centered distances, like the Structure Similarity index, with notable differences in the results.