 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-context learning to predict critical transitions in dynamical systems
May 12, 2026Critical transitions - abrupt, often irreversible changes in system dynamics - arise across human and natural systems, often with catastrophic consequences. Real-world observations of such shifts remain scarce, preventing the development of reliable early warning systems. Conventional statistical and spectral indicators, such as increasing variance, tend to fail under realistic conditions of limited data and correlated noise, whereas existing deep learning classifiers do not extrapolate beyond their training data distribution. In this work, we introduce TipPFN, an in-context learning (ICL) framework that uses a prior-data fitted network to infer a system's proximity to a critical transition. Trained on our novel synthetic data generator, which is based on canonical bifurcation scenarios coupled to diverse, randomized stochastic dynamics, TipPFN flexibly capitalizes on contexts of various sizes, complexity and dimensionalities. We demonstrate robust, state-of-the-art early detection of critical transitions in previously unseen tipping regimes, sim-to-real examples, and real-world observations in both ICL and zero-shot settings.
CausalDynamics: A large-scale benchmark for structural discovery of dynamical causal models
May 22, 2025Causal discovery for dynamical systems poses a major challenge in fields where active interventions are infeasible. Most methods used to investigate these systems and their associated benchmarks are tailored to deterministic, low-dimensional and weakly nonlinear time-series data. To address these limitations, we present CausalDynamics, a large-scale benchmark and extensible data generation framework to advance the structural discovery of dynamical causal models. Our benchmark consists of true causal graphs derived from thousands of coupled ordinary and stochastic differential equations as well as two idealized climate models. We perform a comprehensive evaluation of state-of-the-art causal discovery algorithms for graph reconstruction on systems with noisy, confounded, and lagged dynamics. CausalDynamics consists of a plug-and-play, build-your-own coupling workflow that enables the construction of a hierarchy of physical systems. We anticipate that our framework will facilitate the development of robust causal discovery algorithms that are broadly applicable across domains while addressing their unique challenges. We provide a user-friendly implementation and documentation on https://kausable.github.io/CausalDynamics.
Unsupervised Robust Disentangling of Latent Characteristics for Image Synthesis
Oct 22, 2019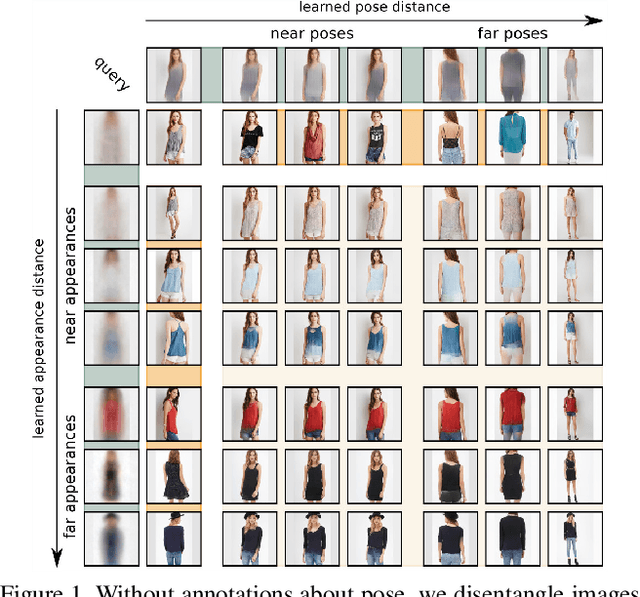



Deep generative models come with the promise to learn an explainable representation for visual objects that allows image sampling, synthesis, and selective modification. The main challenge is to learn to properly model the independent latent characteristics of an object, especially its appearance and pose. We present a novel approach that learns disentangled representations of these characteristics and explains them individually. Training requires only pairs of images depicting the same object appearance, but no pose annotations. We propose an additional classifier that estimates the minimal amount of regularization required to enforce disentanglement. Thus both representations together can completely explain an image while being independent of each other. Previous methods based on adversarial approaches fail to enforce this independence, while methods based on variational approaches lead to uninformative representations. In experiments on diverse object categories, the approach successfully recombines pose and appearance to reconstruct and retarget novel synthesized images. We achieve significant improvements over state-of-the-art methods which utilize the same level of supervision, and reach performances comparable to those of pose-supervised approaches. However, we can handle the vast body of articulated object classes for which no pose models/annotations are available.