 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Multiple Ticket Hypothesis: Random Sparse Subnetworks Suffice for RLVR
Feb 02, 2026The Lottery Ticket Hypothesis demonstrated that sparse subnetworks can match full-model performance, suggesting parameter redundancy. Meanwhile, in Reinforcement Learning with Verifiable Rewards (RLVR), recent work has shown that updates concentrate on a sparse subset of parameters, which further lends evidence to this underlying redundancy. We study the simplest possible way to exploit this redundancy: training only a randomly selected subset of parameters at extreme sparsities. Empirically, we find that training just 1\% of parameters matches or exceeds full-parameter RLVR finetuning across 3 models and 2 task domains. Moreover, different random masks show minimal overlap ($\leq 0.005$ Jaccard similarity) and yet all succeed, suggesting pretrained models contain many viable sparse subnetworks rather than one privileged set. We term this the Multiple Ticket Hypothesis. We explain this phenomenon through the implicit per-step KL constraint in RLVR, which restricts updates to a low-dimensional subspace, enabling arbitrary sparse masks to succeed.
YABLoCo: Yet Another Benchmark for Long Context Code Generation
May 07, 2025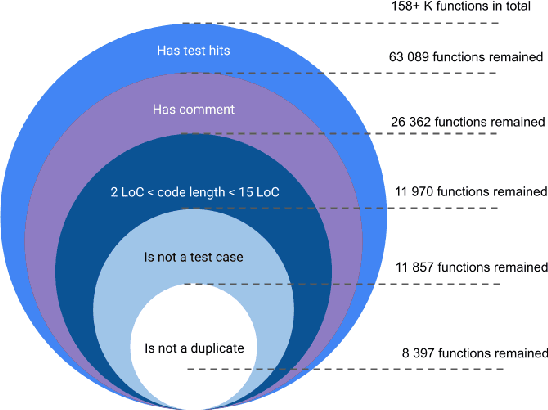
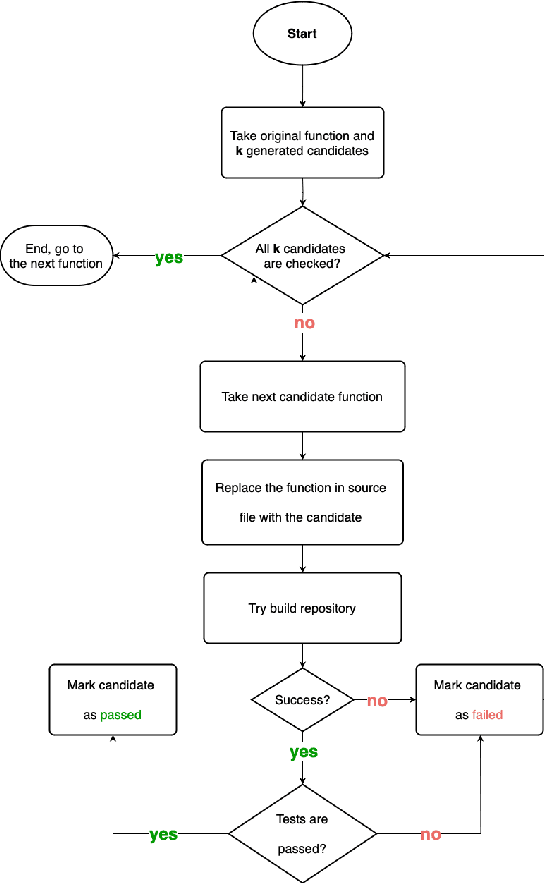
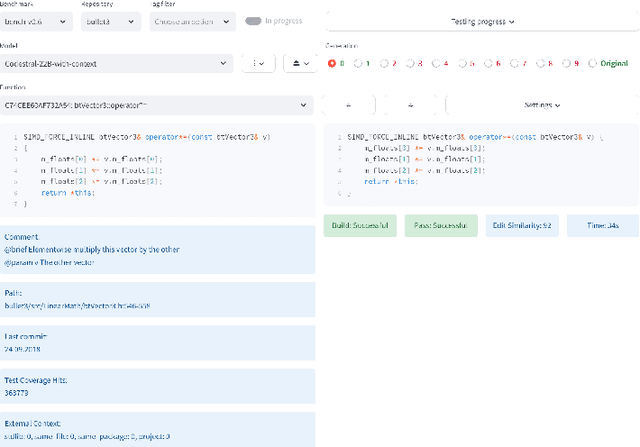
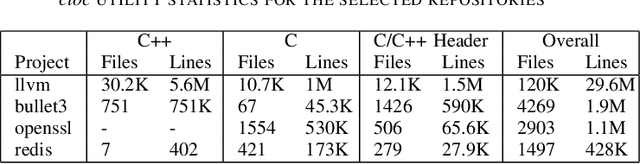
Large Language Models demonstrate the ability to solve various programming tasks, including code generation. Typically, the performance of LLMs is measured on benchmarks with small or medium-sized context windows of thousands of lines of code. At the same time, in real-world software projects, repositories can span up to millions of LoC. This paper closes this gap by contributing to the long context code generation benchmark (YABLoCo). The benchmark featured a test set of 215 functions selected from four large repositories with thousands of functions. The dataset contained metadata of functions, contexts of the functions with different levels of dependencies, docstrings, functions bodies, and call graphs for each repository. This paper presents three key aspects of the contribution. First, the benchmark aims at function body generation in large repositories in C and C++, two languages not covered by previous benchmarks. Second, the benchmark contains large repositories from 200K to 2,000K LoC. Third, we contribute a scalable evaluation pipeline for efficient computing of the target metrics and a tool for visual analysis of generated code. Overall, these three aspects allow for evaluating code generation in large repositories in C and C++.