 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Unified Method for Detecting Text from Marathon Runners and Sports Players in Video
May 26, 2020
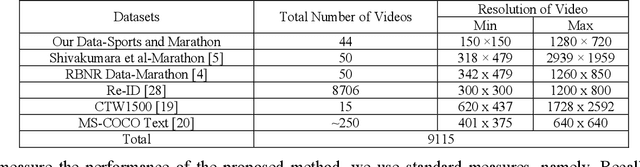


Detecting text located on the torsos of marathon runners and sports players in video is a challenging issue due to poor quality and adverse effects caused by flexible/colorful clothing, and different structures of human bodies or actions. This paper presents a new unified method for tackling the above challenges. The proposed method fuses gradient magnitude and direction coherence of text pixels in a new way for detecting candidate regions. Candidate regions are used for determining the number of temporal frame clusters obtained by K-means clustering on frame differences. This process in turn detects key frames. The proposed method explores Bayesian probability for skin portions using color values at both pixel and component levels of temporal frames, which provides fused images with skin components. Based on skin information, the proposed method then detects faces and torsos by finding structural and spatial coherences between them. We further propose adaptive pixels linking a deep learning model for text detection from torso regions. The proposed method is tested on our own dataset collected from marathon/sports video and three standard datasets, namely, RBNR, MMM and R-ID of marathon images, to evaluate the performance. In addition, the proposed method is also tested on the standard natural scene datasets, namely, CTW1500 and MS-COCO text datasets, to show the objectiveness of the proposed method. A comparative study with the state-of-the-art methods on bib number/text detection of different datasets shows that the proposed method outperforms the existing methods.
Modeling Extent-of-Texture Information for Ground Terrain Recognition
Apr 17, 2020
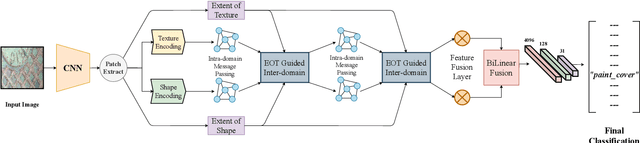
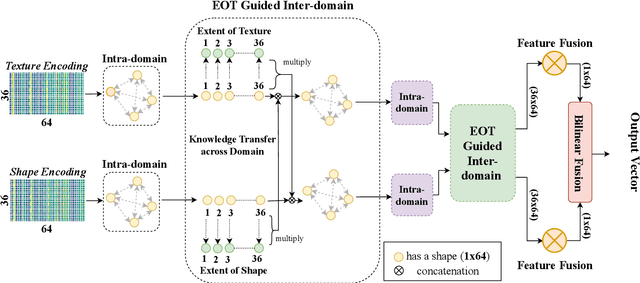
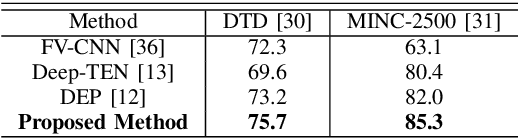
Ground Terrain Recognition is a difficult task as the context information varies significantly over the regions of a ground terrain image. In this paper, we propose a novel approach towards ground-terrain recognition via modeling the Extent-of-Texture information to establish a balance between the order-less texture component and ordered-spatial information locally. At first, the proposed method uses a CNN backbone feature extractor network to capture meaningful information of a ground terrain image, and model the extent of texture and shape information locally. Then, the order-less texture information and ordered shape information are encoded in a patch-wise manner, which is utilized by intra-domain message passing module to make every patch aware of each other for rich feature learning. Next, the Extent-of-Texture (EoT) Guided Inter-domain Message Passing module combines the extent of texture and shape information with the encoded texture and shape information in a patch-wise fashion for sharing knowledge to balance out the order-less texture information with ordered shape information. Further, Bilinear model generates a pairwise correlation between the order-less texture information and ordered shape information. Finally, the ground-terrain image classification is performed by a fully connected layer. The experimental results indicate superior performance of the proposed model over existing state-of-the-art techniques on publicly available datasets like DTD, MINC and GTOS-mobile.
DELP-DAR System for License Plate Detection and Recognition
Oct 04, 2019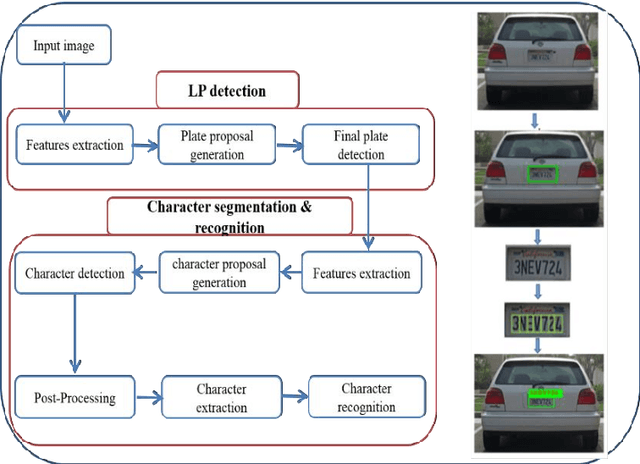
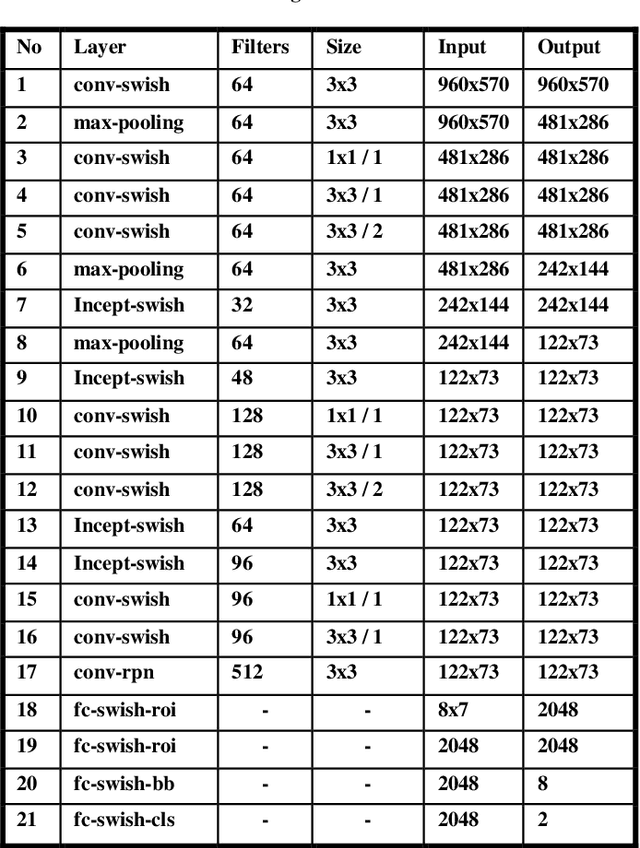
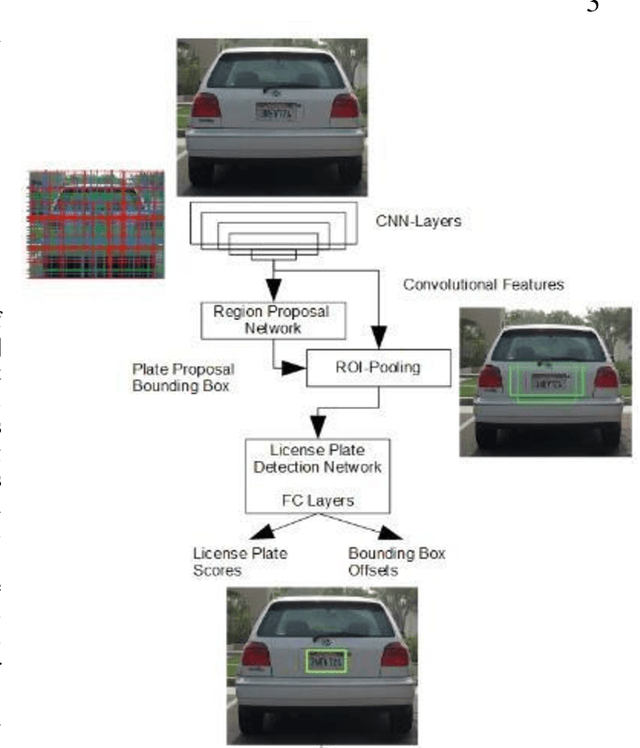
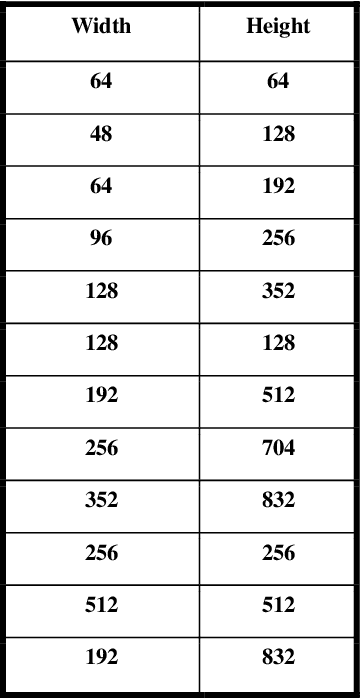
Automatic License Plate detection and Recognition (ALPR) is a quite popular and active research topic in the field of computer vision, image processing and intelligent transport systems. ALPR is used to make detection and recognition processes more robust and efficient in highly complicated environments and backgrounds. Several research investigations are still necessary due to some constraints such as: completeness of numbering systems of countries, different colors, various languages, multiple sizes and varied fonts. For this, we present in this paper an automatic framework for License Plate (LP) detection and recognition from complex scenes. Our framework is based on mask region convolutional neural networks used for LP detection, segmentation and recognition. Although some studies have focused on LP detection, LP recognition, LP segmentation or just two of them, our study uses the maskr-cnn in the three stages. The evaluation of our framework is enhanced by four datasets for different countries and consequently with various languages. In fact, it tested on four datasets including images captured from multiple scenes under numerous conditions such as varied orientation, poor quality images, blurred images and complex environmental backgrounds. Extensive experiments show the robustness and efficiency of our suggested framework in all datasets.
ICDAR2019 Robust Reading Challenge on Multi-lingual Scene Text Detection and Recognition -- RRC-MLT-2019
Jul 01, 2019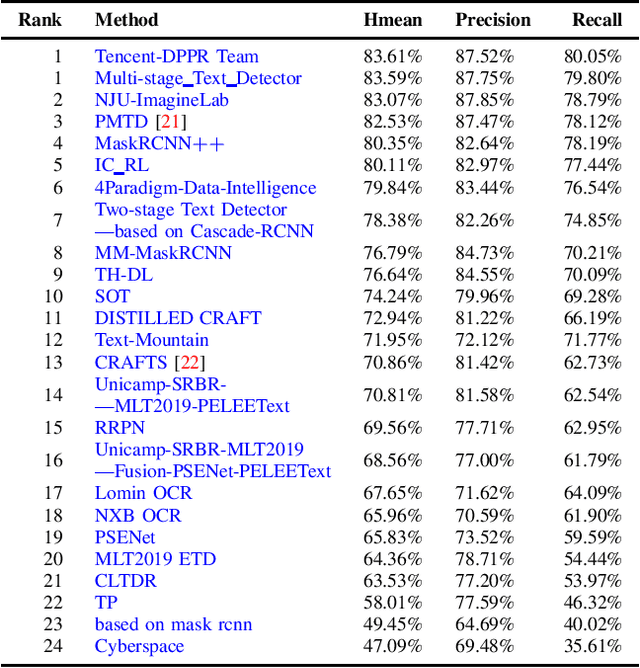
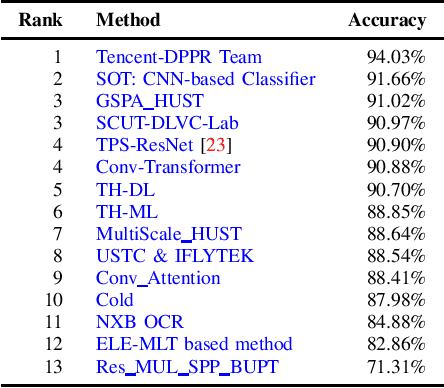
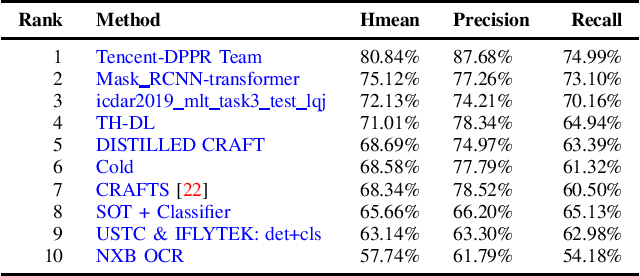
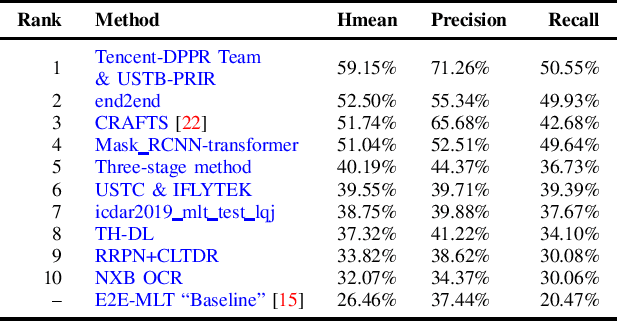
With the growing cosmopolitan culture of modern cities, the need of robust Multi-Lingual scene Text (MLT) detection and recognition systems has never been more immense. With the goal to systematically benchmark and push the state-of-the-art forward, the proposed competition builds on top of the RRC-MLT-2017 with an additional end-to-end task, an additional language in the real images dataset, a large scale multi-lingual synthetic dataset to assist the training, and a baseline End-to-End recognition method. The real dataset consists of 20,000 images containing text from 10 languages. The challenge has 4 tasks covering various aspects of multi-lingual scene text: (a) text detection, (b) cropped word script classification, (c) joint text detection and script classification and (d) end-to-end detection and recognition. In total, the competition received 60 submissions from the research and industrial communities. This paper presents the dataset, the tasks and the findings of the presented RRC-MLT-2019 challenge.
Distance Metric Learned Collaborative Representation Classifier
May 03, 2019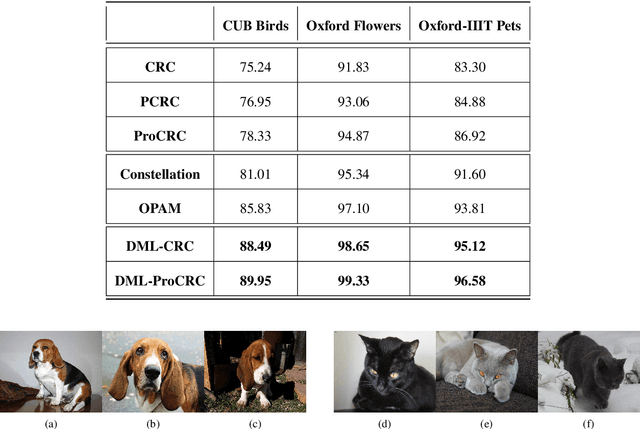
Any generic deep machine learning algorithm is essentially a function fitting exercise, where the network tunes its weights and parameters to learn discriminatory features by minimizing some cost function. Though the network tries to learn the optimal feature space, it seldom tries to learn an optimal distance metric in the cost function, and hence misses out on an additional layer of abstraction. We present a simple effective way of achieving this by learning a generic Mahalanabis distance in a collaborative loss function in an end-to-end fashion with any standard convolutional network as the feature learner. The proposed method DML-CRC gives state-of-the-art performance on benchmark fine-grained classification datasets CUB Birds, Oxford Flowers and Oxford-IIIT Pets using the VGG-19 deep network. The method is network agnostic and can be used for any similar classification tasks.
PProCRC: Probabilistic Collaboration of Image Patches
Mar 21, 2019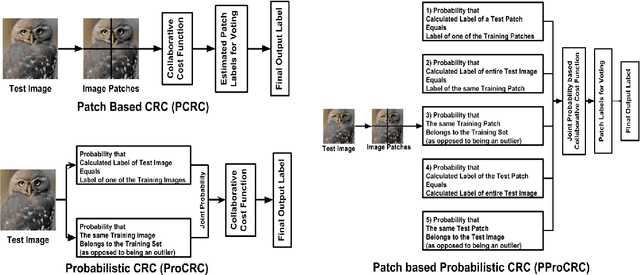
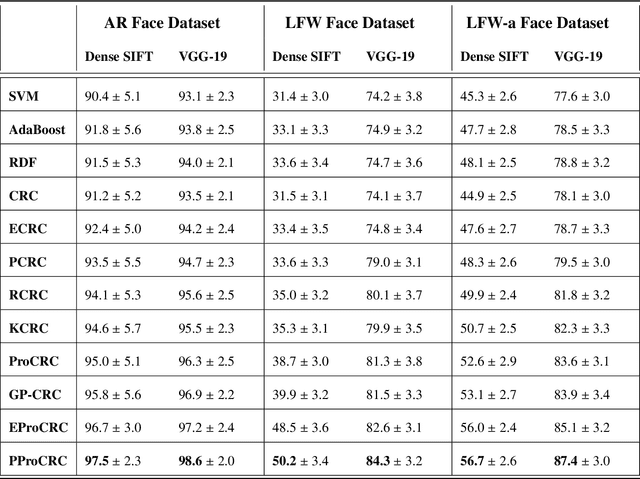

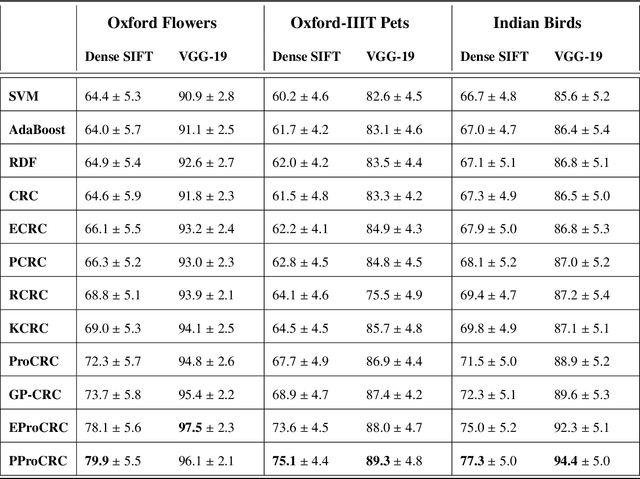
We present a conditional probabilistic framework for collaborative representation of image patches. It in-corporates background compensation and outlier patch suppression into the main formulation itself, thus doingaway with the need for pre-processing steps to handle the same. A closed form non-iterative solution of the costfunction is derived. The proposed method (PProCRC) outperforms earlier related patch based (PCRC, GP-CRC)as well as the state-of-the-art probabilistic (ProCRC and EProCRC) models on several fine-grained benchmarkimage datasets for face recognition (AR and LFW) and species recognition (Oxford Flowers and Pets) tasks.We also expand our recent endemic Indian birds (IndBirds) dataset and report results on it. The demo code andIndBirds dataset are available through lead author.
STEFANN: Scene Text Editor using Font Adaptive Neural Network
Mar 04, 2019


Textual information in a captured scene play important role in scene interpretation and decision making. Pieces of dedicated research work are going on to detect and recognize textual data accurately in images. Though there exist methods that can successfully detect complex text regions present in a scene, to the best of our knowledge there is no work to modify the textual information in an image. This paper deals with a simple text editor that can edit/modify the textual part in an image. Apart from error correction in the text part of the image, this work can directly increase the reusability of images drastically. In this work, at first, we focus on the problem to generate unobserved characters with the similar font and color of an observed text character present in a natural scene with minimum user intervention. To generate the characters, we propose a multi-input neural network that adapts the font-characteristics of a given characters (source), and generate desired characters (target) with similar font features. We also propose a network that transfers color from source to target character without any visible distortion. Next, we place the generated character in a word for its modification maintaining the visual consistency with the other characters in the word. The proposed method is a unified platform that can work like a simple text editor and edit texts in images. We tested our methodology on popular ICDAR 2011 and ICDAR 2013 datasets and results are reported here.
CoCoNet: A Collaborative Convolutional Network
Jan 28, 2019
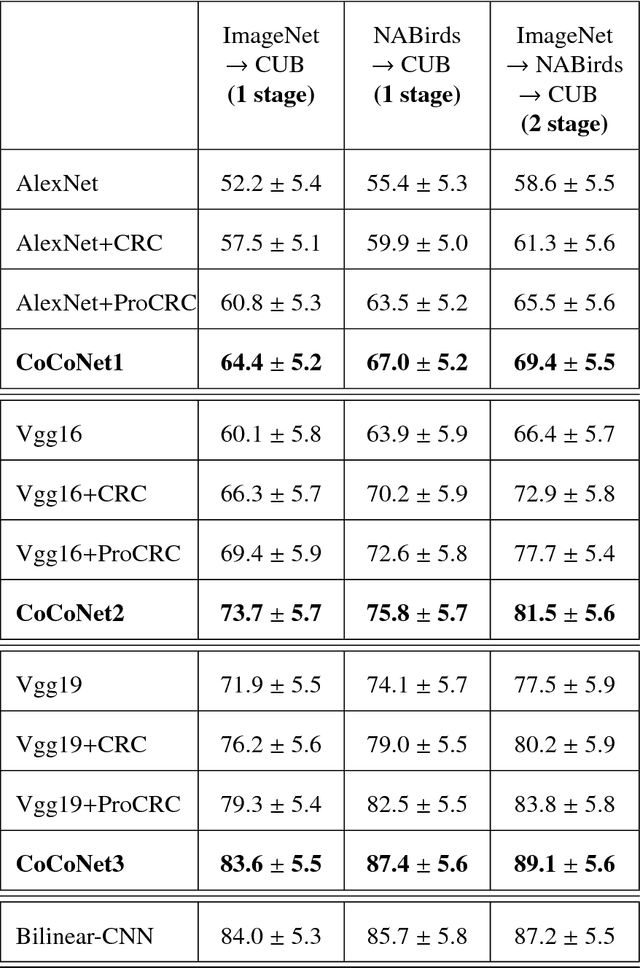
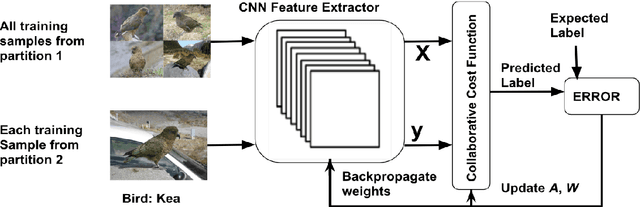
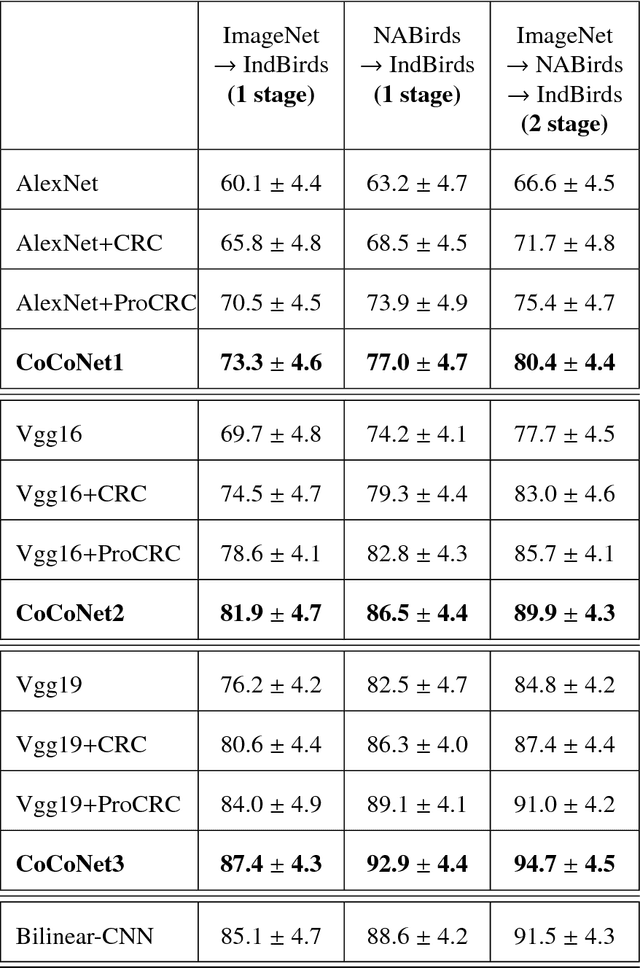
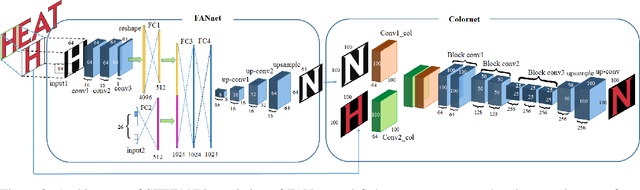
We present an end-to-end CNN architecture for fine-grained visual recognition called Collaborative Convolutional Network (CoCoNet). The network uses a collaborative filter after the convolutional layers to represent an image as an optimal weighted collaboration of features learned from training samples as a whole rather than one at a time. This gives CoCoNet more power to encode the fine-grained nature of the data with limited samples in an end-to-end fashion. We perform a detailed study of the performance with 1-stage and 2-stage transfer learning and different configurations with benchmark architectures like AlexNet and VggNet. The ablation study shows that the proposed method outperforms its constituent parts considerably and consistently. CoCoNet also outperforms the baseline popular deep learning based fine-grained recognition method, namely Bilinear-CNN (BCNN) with statistical significance. Experiments have been performed on the fine-grained species recognition problem, but the method is general enough to be applied to other similar tasks. Lastly, we also introduce a new public dataset for fine-grained species recognition, that of Indian endemic birds and have reported initial results on it. The training metadata and new dataset are available through the corresponding author.
Effects of Degradations on Deep Neural Network Architectures
Aug 12, 2018
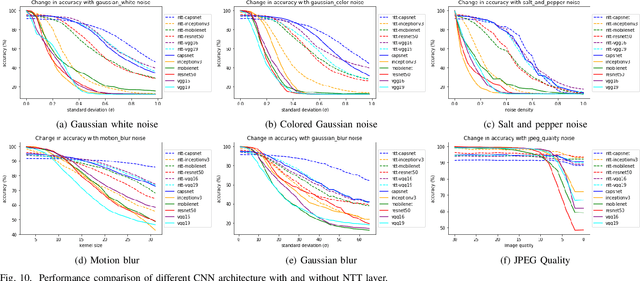
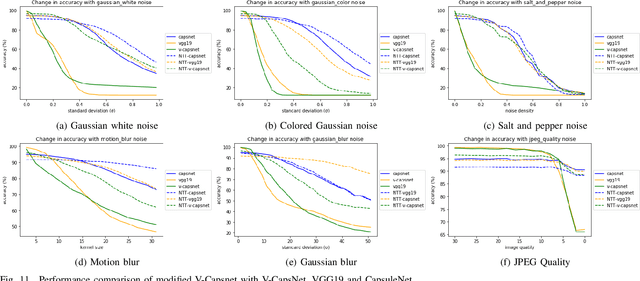
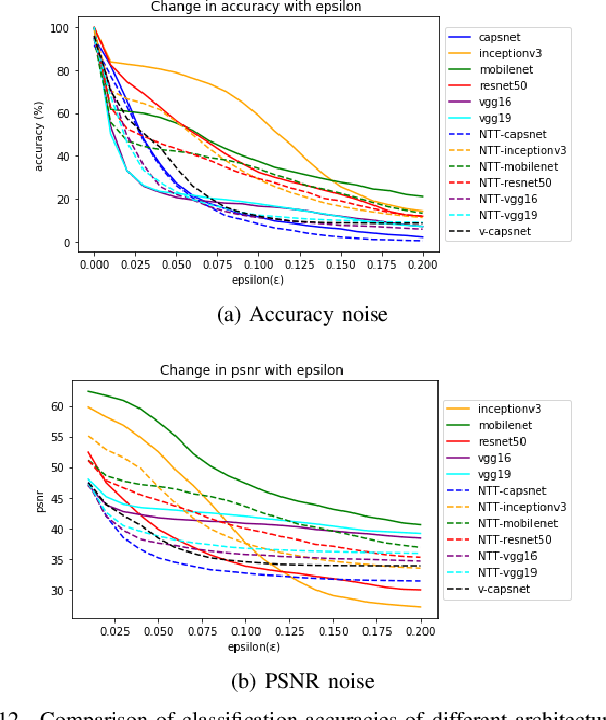
Deep convolutional neural networks (CNNs) have achieved many state-of-the-art results recently in different fields of computer vision. Different architectures are emerging almost everyday that produce fascinating results in machine vision tasks consisting million of images. Though CNN based models are able to detect and recognize large number of object classes, most of the times these models are trained with high quality images. Recently, an alternative architecture for image classification is proposed by Sabour et al. \cite{sabour2017dynamic} based on groups of neurons (capsules) and a novel dynamic routing protocol. The architecture has shown promising result by surpassing the performances of state-of-the-art CNN based models in some of the existing datasets. However, the behavior of capsule based models and CNN based models are largely unknown in presence of noise. As in most of the practical applications, it can not be guaranteed the input image is completely noise-free and does not contain any distortion, it is important to study the performance of these models under different noise conditions. In this paper, we select six widely used CNN architectures and consider their performances for image classification task for two different datasets under various image quality distortions. We show that the capsule network is more robust to several image degradations than the CNN based models. To the best of our knowledge, this is the first study on the performance of CapsuleNet (or CapsNet) and other state-of-the-art CNN architectures under different types of image degradations.
Script Identification in Natural Scene Image and Video Frame using Attention based Convolutional-LSTM Network
Aug 07, 2018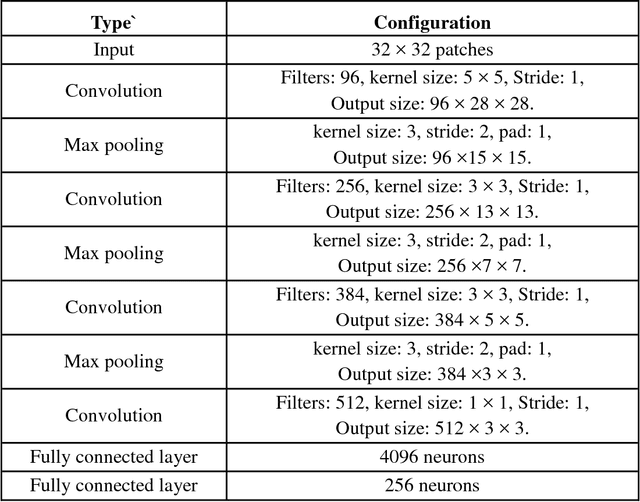
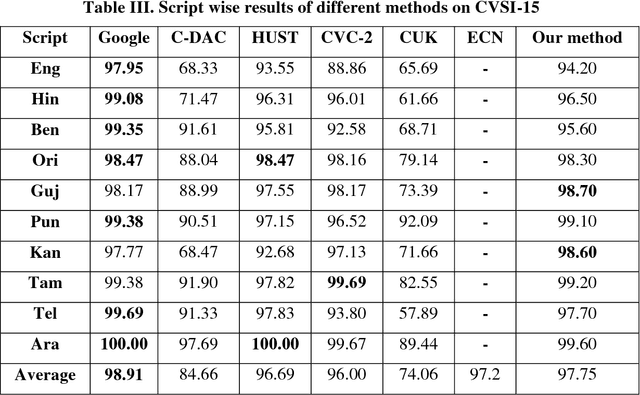
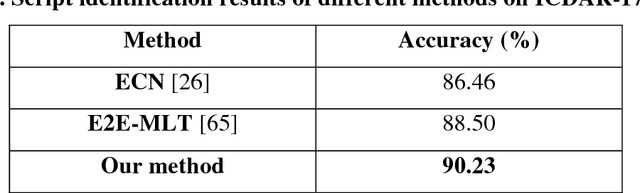
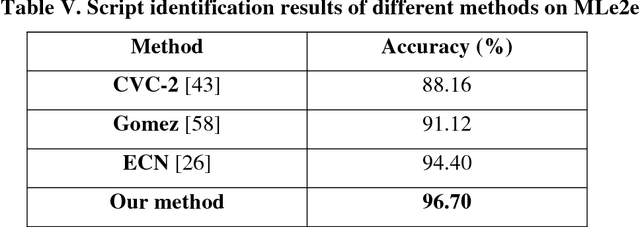
Script identification plays a significant role in analysing documents and videos. In this paper, we focus on the problem of script identification in scene text images and video scripts. Because of low image quality, complex background and similar layout of characters shared by some scripts like Greek, Latin, etc., text recognition in those cases become challenging. In this paper, we propose a novel method that involves extraction of local and global features using CNN-LSTM framework and weighting them dynamically for script identification. First, we convert the images into patches and feed them into a CNN-LSTM framework. Attention-based patch weights are calculated applying softmax layer after LSTM. Next, we do patch-wise multiplication of these weights with corresponding CNN to yield local features. Global features are also extracted from last cell state of LSTM. We employ a fusion technique which dynamically weights the local and global features for an individual patch. Experiments have been done in four public script identification datasets: SIW-13, CVSI2015, ICDAR-17 and MLe2e. The proposed framework achieves superior results in comparison to conventional methods.