 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Neural Models with Stochastic Layers
Nov 13, 2016
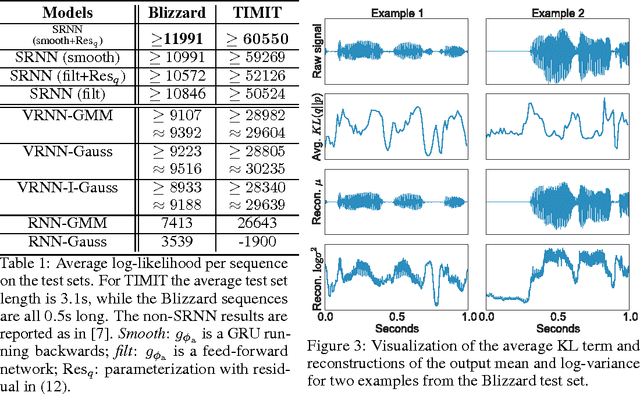
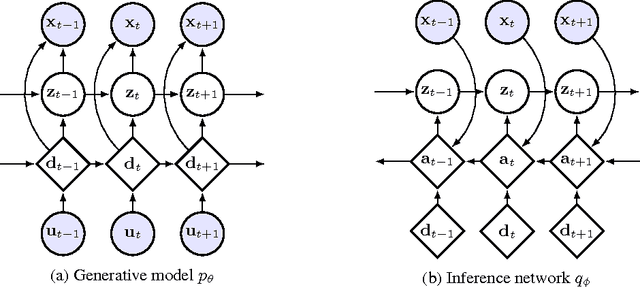

How can we efficiently propagate uncertainty in a latent state representation with recurrent neural networks? This paper introduces stochastic recurrent neural networks which glue a deterministic recurrent neural network and a state space model together to form a stochastic and sequential neural generative model. The clear separation of deterministic and stochastic layers allows a structured variational inference network to track the factorization of the model's posterior distribution. By retaining both the nonlinear recursive structure of a recurrent neural network and averaging over the uncertainty in a latent path, like a state space model, we improve the state of the art results on the Blizzard and TIMIT speech modeling data sets by a large margin, while achieving comparable performances to competing methods on polyphonic music modeling.
The Bayesian Low-Rank Determinantal Point Process Mixture Model
Aug 16, 2016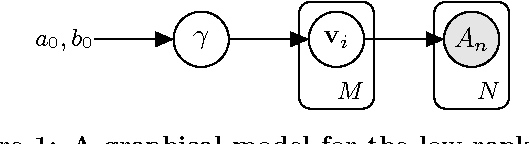
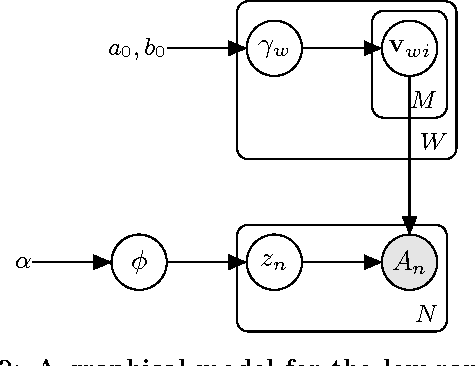
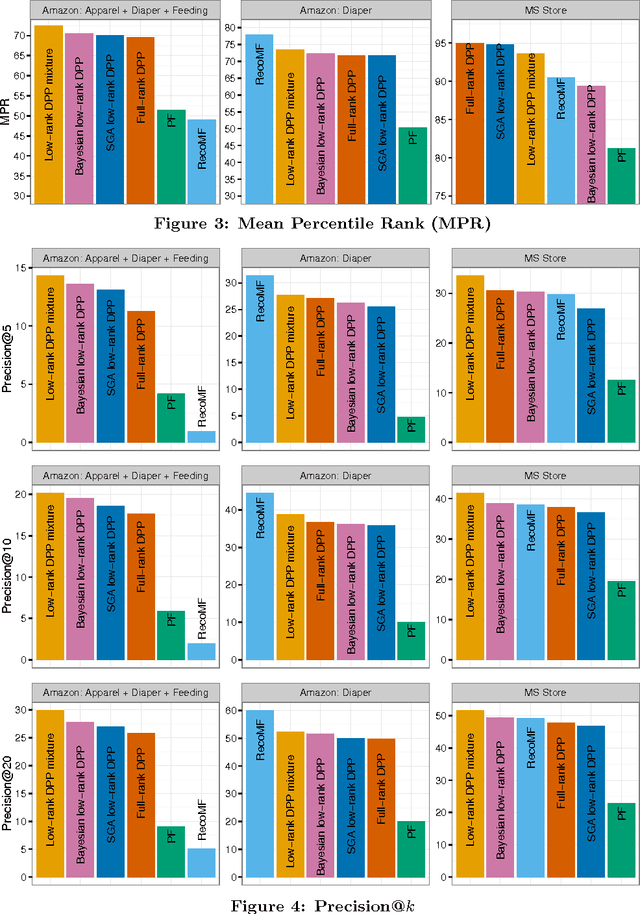
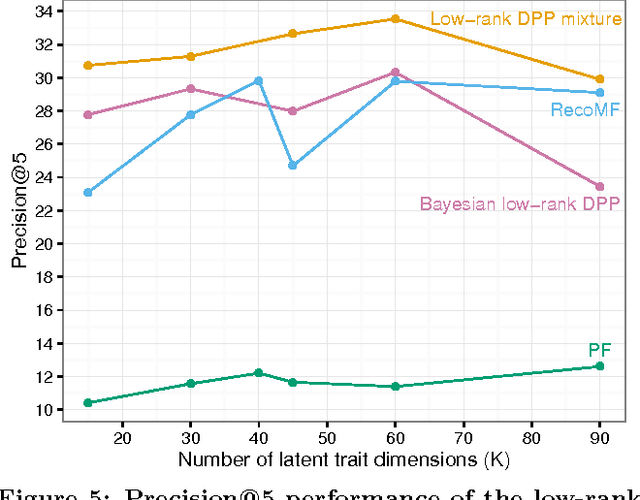
Determinantal point processes (DPPs) are an elegant model for encoding probabilities over subsets, such as shopping baskets, of a ground set, such as an item catalog. They are useful for a number of machine learning tasks, including product recommendation. DPPs are parametrized by a positive semi-definite kernel matrix. Recent work has shown that using a low-rank factorization of this kernel provides remarkable scalability improvements that open the door to training on large-scale datasets and computing online recommendations, both of which are infeasible with standard DPP models that use a full-rank kernel. In this paper we present a low-rank DPP mixture model that allows us to represent the latent structure present in observed subsets as a mixture of a number of component low-rank DPPs, where each component DPP is responsible for representing a portion of the observed data. The mixture model allows us to effectively address the capacity constraints of the low-rank DPP model. We present an efficient and scalable Markov Chain Monte Carlo (MCMC) learning algorithm for our model that uses Gibbs sampling and stochastic gradient Hamiltonian Monte Carlo (SGHMC). Using an evaluation on several real-world product recommendation datasets, we show that our low-rank DPP mixture model provides substantially better predictive performance than is possible with a single low-rank or full-rank DPP, and significantly better performance than several other competing recommendation methods in many cases.
An Adaptive Resample-Move Algorithm for Estimating Normalizing Constants
Aug 15, 2016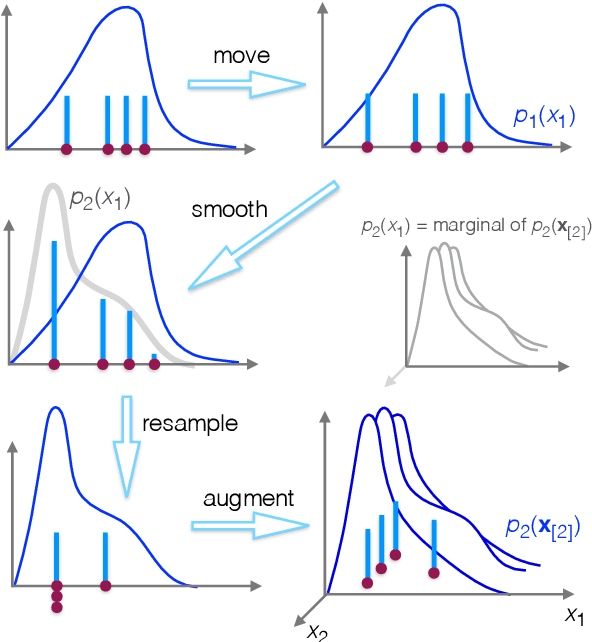
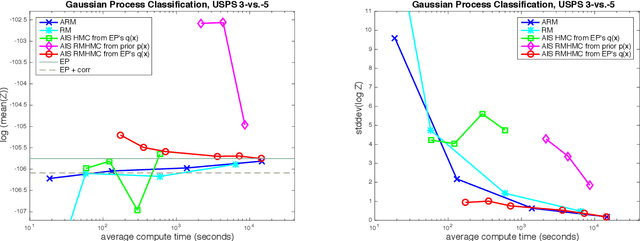
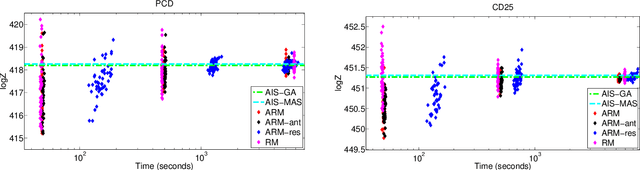
The estimation of normalizing constants is a fundamental step in probabilistic model comparison. Sequential Monte Carlo methods may be used for this task and have the advantage of being inherently parallelizable. However, the standard choice of using a fixed number of particles at each iteration is suboptimal because some steps will contribute disproportionately to the variance of the estimate. We introduce an adaptive version of the Resample-Move algorithm, in which the particle set is adaptively expanded whenever a better approximation of an intermediate distribution is needed. The algorithm builds on the expression for the optimal number of particles and the corresponding minimum variance found under ideal conditions. Benchmark results on challenging Gaussian Process Classification and Restricted Boltzmann Machine applications show that Adaptive Resample-Move (ARM) estimates the normalizing constant with a smaller variance, using less computational resources, than either Resample-Move with a fixed number of particles or Annealed Importance Sampling. A further advantage over Annealed Importance Sampling is that ARM is easier to tune.
Low-Rank Factorization of Determinantal Point Processes for Recommendation
Feb 17, 2016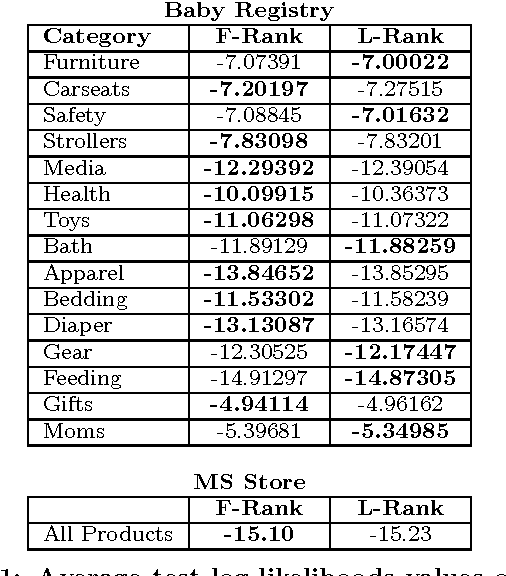
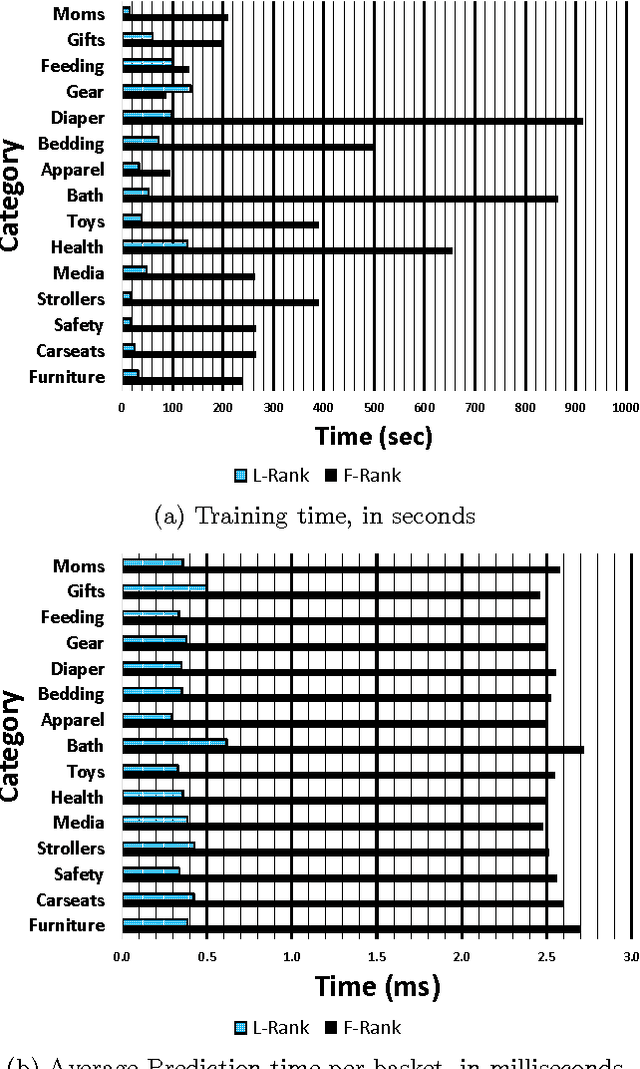
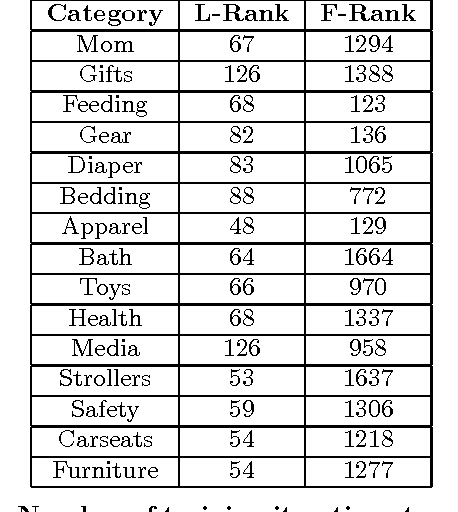
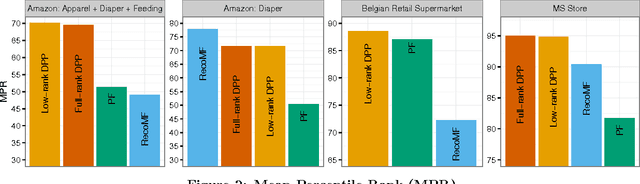
Determinantal point processes (DPPs) have garnered attention as an elegant probabilistic model of set diversity. They are useful for a number of subset selection tasks, including product recommendation. DPPs are parametrized by a positive semi-definite kernel matrix. In this work we present a new method for learning the DPP kernel from observed data using a low-rank factorization of this kernel. We show that this low-rank factorization enables a learning algorithm that is nearly an order of magnitude faster than previous approaches, while also providing for a method for computing product recommendation predictions that is far faster (up to 20x faster or more for large item catalogs) than previous techniques that involve a full-rank DPP kernel. Furthermore, we show that our method provides equivalent or sometimes better predictive performance than prior full-rank DPP approaches, and better performance than several other competing recommendation methods in many cases. We conduct an extensive experimental evaluation using several real-world datasets in the domain of product recommendation to demonstrate the utility of our method, along with its limitations.
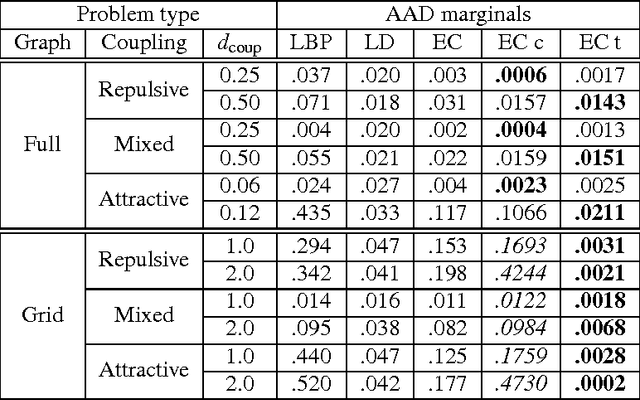
On the Convergence of Stochastic Variational Inference in Bayesian Networks
Jul 16, 2015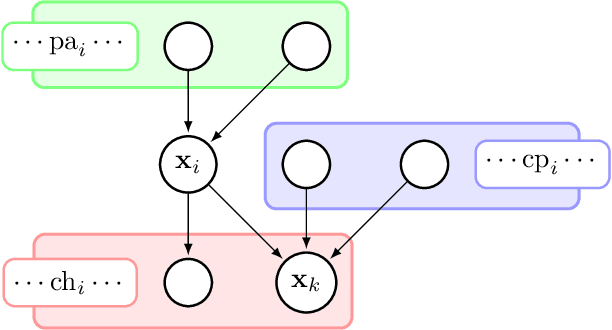
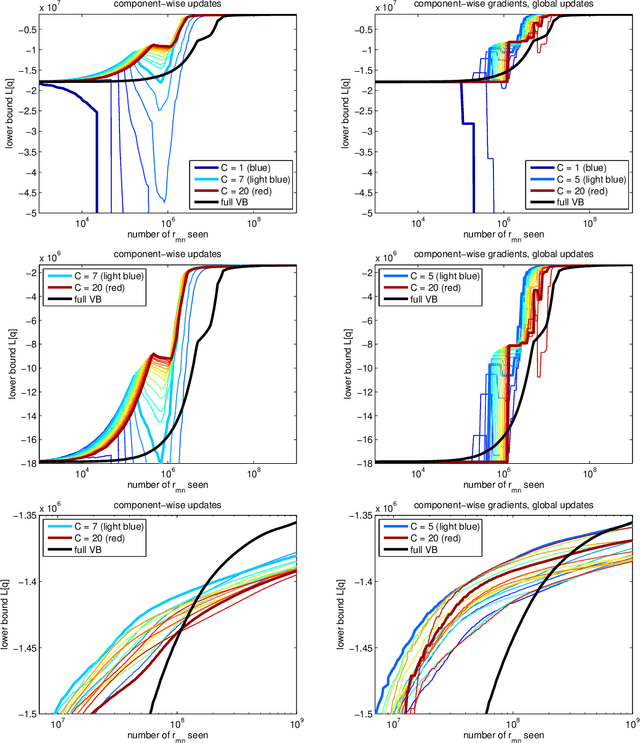
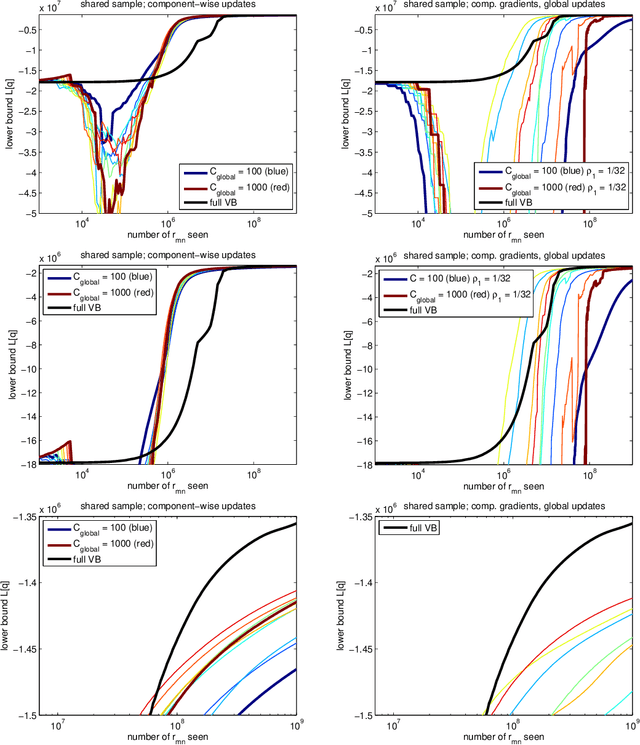
We highlight a pitfall when applying stochastic variational inference to general Bayesian networks. For global random variables approximated by an exponential family distribution, natural gradient steps, commonly starting from a unit length step size, are averaged to convergence. This useful insight into the scaling of initial step sizes is lost when the approximation factorizes across a general Bayesian network, and care must be taken to ensure practical convergence. We experimentally investigate how much of the baby (well-scaled steps) is thrown out with the bath water (exact gradients).
One-class Collaborative Filtering with Random Graphs: Annotated Version
Sep 24, 2014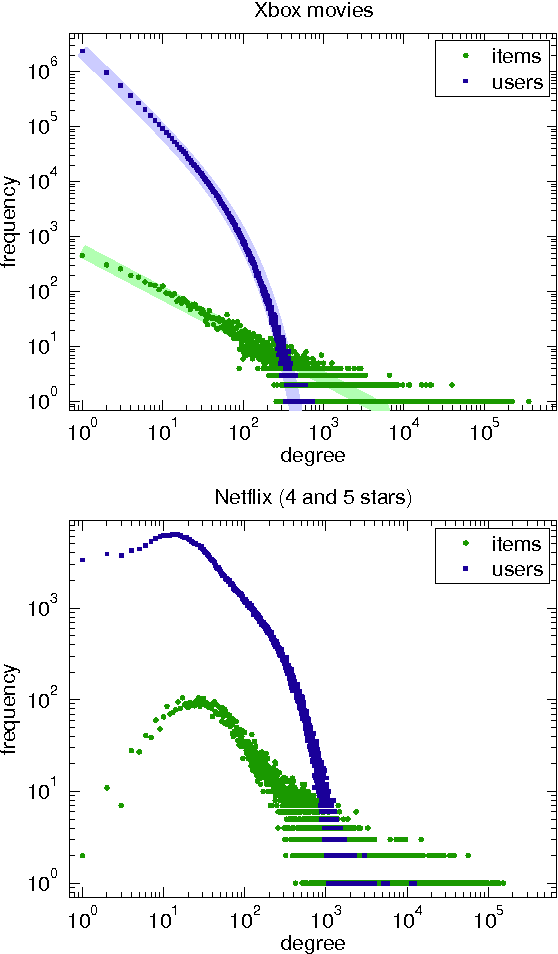
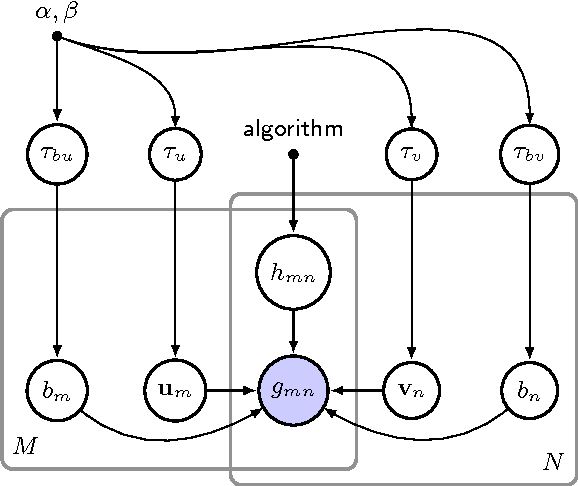
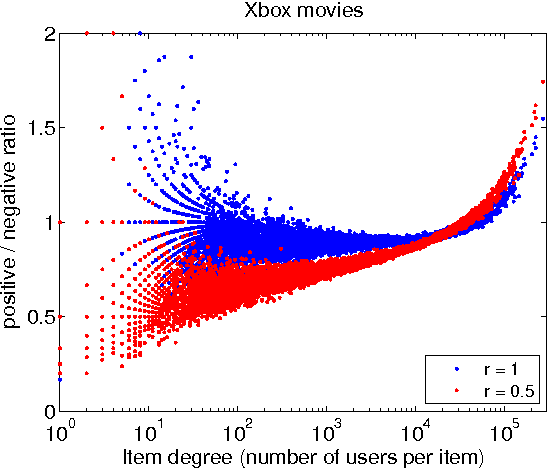
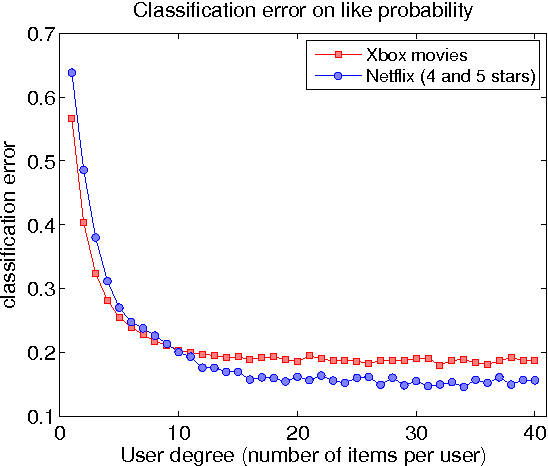
The bane of one-class collaborative filtering is interpreting and modelling the latent signal from the missing class. In this paper we present a novel Bayesian generative model for implicit collaborative filtering. It forms a core component of the Xbox Live architecture, and unlike previous approaches, delineates the odds of a user disliking an item from simply not considering it. The latent signal is treated as an unobserved random graph connecting users with items they might have encountered. We demonstrate how large-scale distributed learning can be achieved through a combination of stochastic gradient descent and mean field variational inference over random graph samples. A fine-grained comparison is done against a state of the art baseline on real world data.
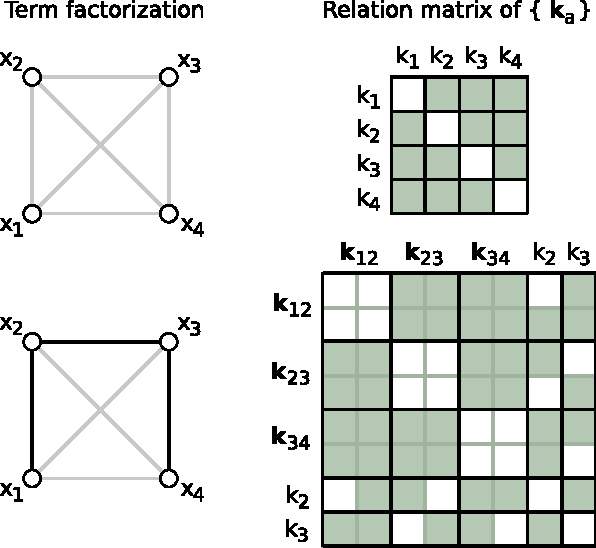
Scalable Bayesian Modelling of Paired Symbols
Sep 10, 2014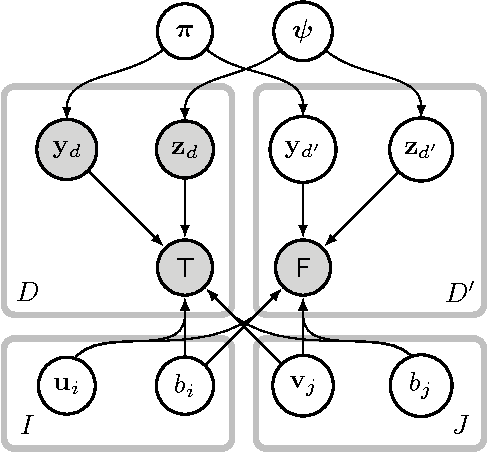
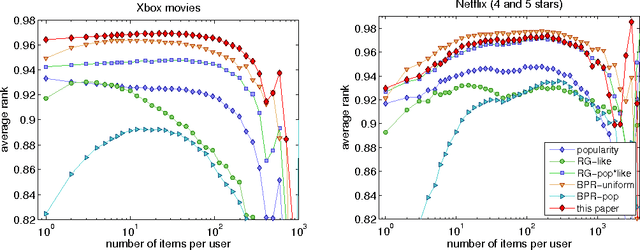
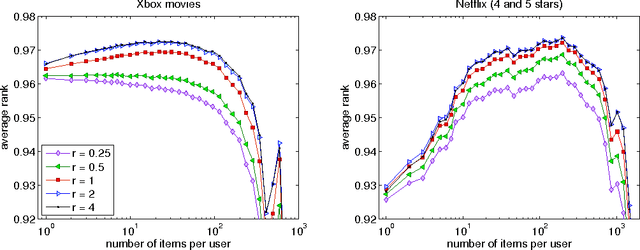
We present a novel, scalable and Bayesian approach to modelling the occurrence of pairs of symbols (i,j) drawn from a large vocabulary. Observed pairs are assumed to be generated by a simple popularity based selection process followed by censoring using a preference function. By basing inference on the well-founded principle of variational bounding, and using new site-independent bounds, we show how a scalable inference procedure can be obtained for large data sets. State of the art results are presented on real-world movie viewing data.
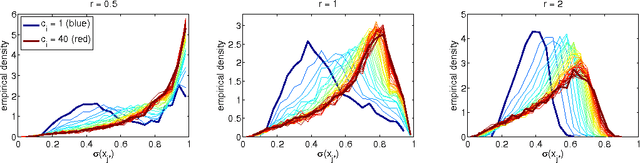
Perturbative Corrections for Approximate Inference in Gaussian Latent Variable Models
Oct 25, 2013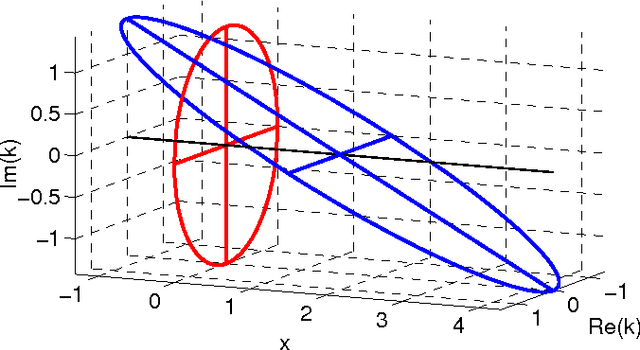
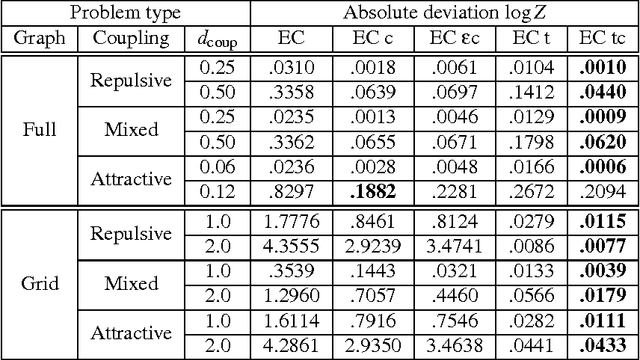
Expectation Propagation (EP) provides a framework for approximate inference. When the model under consideration is over a latent Gaussian field, with the approximation being Gaussian, we show how these approximations can systematically be corrected. A perturbative expansion is made of the exact but intractable correction, and can be applied to the model's partition function and other moments of interest. The correction is expressed over the higher-order cumulants which are neglected by EP's local matching of moments. Through the expansion, we see that EP is correct to first order. By considering higher orders, corrections of increasing polynomial complexity can be applied to the approximation. The second order provides a correction in quadratic time, which we apply to an array of Gaussian process and Ising models. The corrections generalize to arbitrarily complex approximating families, which we illustrate on tree-structured Ising model approximations. Furthermore, they provide a polynomial-time assessment of the approximation error. We also provide both theoretical and practical insights on the exactness of the EP solution.