 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Stage Residual-Aware Unsupervised Deep Learning Framework for Consistent Ultrasound Strain Elastography
Nov 19, 2025Ultrasound Strain Elastography (USE) is a powerful non-invasive imaging technique for assessing tissue mechanical properties, offering crucial diagnostic value across diverse clinical applications. However, its clinical application remains limited by tissue decorrelation noise, scarcity of ground truth, and inconsistent strain estimation under different deformation conditions. Overcoming these barriers, we propose MUSSE-Net, a residual-aware, multi-stage unsupervised sequential deep learning framework designed for robust and consistent strain estimation. At its backbone lies our proposed USSE-Net, an end-to-end multi-stream encoder-decoder architecture that parallelly processes pre- and post-deformation RF sequences to estimate displacement fields and axial strains. The novel architecture incorporates Context-Aware Complementary Feature Fusion (CACFF)-based encoder with Tri-Cross Attention (TCA) bottleneck with a Cross-Attentive Fusion (CAF)-based sequential decoder. To ensure temporal coherence and strain stability across varying deformation levels, this architecture leverages a tailored consistency loss. Finally, with the MUSSE-Net framework, a secondary residual refinement stage further enhances accuracy and suppresses noise. Extensive validation on simulation, in vivo, and private clinical datasets from Bangladesh University of Engineering and Technology (BUET) medical center, demonstrates MUSSE-Net's outperformed existing unsupervised approaches. On MUSSE-Net achieves state-of-the-art performance with a target SNR of 24.54, background SNR of 132.76, CNR of 59.81, and elastographic SNR of 9.73 on simulation data. In particular, on the BUET dataset, MUSSE-Net produces strain maps with enhanced lesion-to-background contrast and significant noise suppression yielding clinically interpretable strain patterns.
EXGnet: a single-lead explainable-AI guided multiresolution network with train-only quantitative features for trustworthy ECG arrhythmia classification
Jun 14, 2025



Background: Deep learning has significantly advanced ECG arrhythmia classification, enabling high accuracy in detecting various cardiac conditions. The use of single-lead ECG systems is crucial for portable devices, as they offer convenience and accessibility for continuous monitoring in diverse settings. However, the interpretability and reliability of deep learning models in clinical applications poses challenges due to their black-box nature. Methods: To address these challenges, we propose EXGnet, a single-lead, trustworthy ECG arrhythmia classification network that integrates multiresolution feature extraction with Explainable Artificial Intelligence (XAI) guidance and train only quantitative features. Results: Trained on two public datasets, including Chapman and Ningbo, EXGnet demonstrates superior performance through key metrics such as Accuracy, F1-score, Sensitivity, and Specificity. The proposed method achieved average five fold accuracy of 98.762%, and 96.932% and average F1-score of 97.910%, and 95.527% on the Chapman and Ningbo datasets, respectively. Conclusions: By employing XAI techniques, specifically Grad-CAM, the model provides visual insights into the relevant ECG segments it analyzes, thereby enhancing clinician trust in its predictions. While quantitative features further improve classification performance, they are not required during testing, making the model suitable for real-world applications. Overall, EXGnet not only achieves better classification accuracy but also addresses the critical need for interpretability in deep learning, facilitating broader adoption in portable ECG monitoring.
An Automatic Speech Recognition System for Bengali Language based on Wav2Vec2 and Transfer Learning
Sep 20, 2022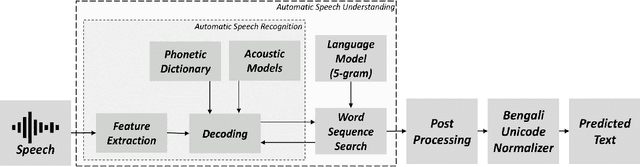
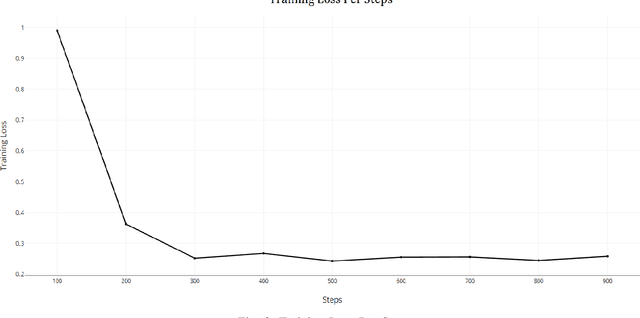
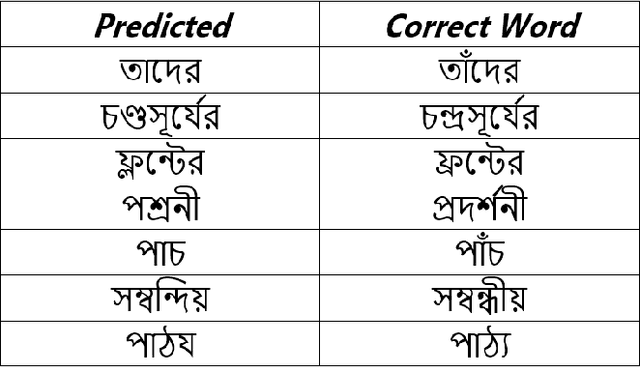
An independent, automated method of decoding and transcribing oral speech is known as automatic speech recognition (ASR). A typical ASR system extracts feature from audio recordings or streams and run one or more algorithms to map the features to corresponding texts. Numerous of research has been done in the field of speech signal processing in recent years. When given adequate resources, both conventional ASR and emerging end-to-end (E2E) speech recognition have produced promising results. However, for low-resource languages like Bengali, the current state of ASR lags behind, although the low resource state does not reflect upon the fact that this language is spoken by over 500 million people all over the world. Despite its popularity, there aren't many diverse open-source datasets available, which makes it difficult to conduct research on Bengali speech recognition systems. This paper is a part of the competition named `BUET CSE Fest DL Sprint'. The purpose of this paper is to improve the speech recognition performance of the Bengali language by adopting speech recognition technology on the E2E structure based on the transfer learning framework. The proposed method effectively models the Bengali language and achieves 3.819 score in `Levenshtein Mean Distance' on the test dataset of 7747 samples, when only 1000 samples of train dataset were used to train.