 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Agents Design and Implement Drug Discovery Pipelines?
Apr 28, 2025



The rapid advancement of artificial intelligence, particularly autonomous agentic systems based on Large Language Models (LLMs), presents new opportunities to accelerate drug discovery by improving in-silico modeling and reducing dependence on costly experimental trials. Current AI agent-based systems demonstrate proficiency in solving programming challenges and conducting research, indicating an emerging potential to develop software capable of addressing complex problems such as pharmaceutical design and drug discovery. This paper introduces DO Challenge, a benchmark designed to evaluate the decision-making abilities of AI agents in a single, complex problem resembling virtual screening scenarios. The benchmark challenges systems to independently develop, implement, and execute efficient strategies for identifying promising molecular structures from extensive datasets, while navigating chemical space, selecting models, and managing limited resources in a multi-objective context. We also discuss insights from the DO Challenge 2025, a competition based on the proposed benchmark, which showcased diverse strategies explored by human participants. Furthermore, we present the Deep Thought multi-agent system, which demonstrated strong performance on the benchmark, outperforming most human teams. Among the language models tested, Claude 3.7 Sonnet, Gemini 2.5 Pro and o3 performed best in primary agent roles, and GPT-4o, Gemini 2.0 Flash were effective in auxiliary roles. While promising, the system's performance still fell short of expert-designed solutions and showed high instability, highlighting both the potential and current limitations of AI-driven methodologies in transforming drug discovery and broader scientific research.
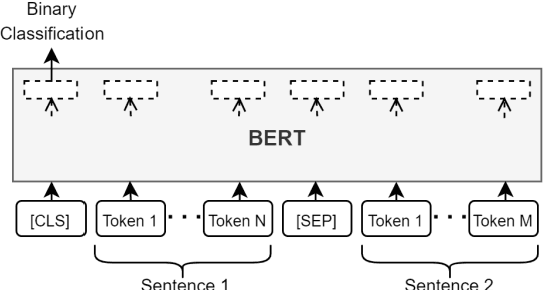
A Simple and Effective Method of Cross-Lingual Plagiarism Detection
Apr 05, 2023We present a simple cross-lingual plagiarism detection method applicable to a large number of languages. The presented approach leverages open multilingual thesauri for candidate retrieval task and pre-trained multilingual BERT-based language models for detailed analysis. The method does not rely on machine translation and word sense disambiguation when in use, and therefore is suitable for a large number of languages, including under-resourced languages. The effectiveness of the proposed approach is demonstrated for several existing and new benchmarks, achieving state-of-the-art results for French, Russian, and Armenian languages.
ARPA: Armenian Paraphrase Detection Corpus and Models
Sep 26, 2020

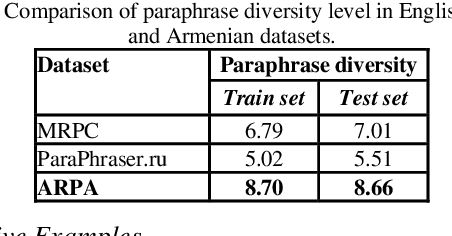
In this work, we employ a semi-automatic method based on back translation to generate a sentential paraphrase corpus for the Armenian language. The initial collection of sentences is translated from Armenian to English and back twice, resulting in pairs of lexically distant but semantically similar sentences. The generated paraphrases are then manually reviewed and annotated. Using the method train and test datasets are created, containing 2360 paraphrases in total. In addition, the datasets are used to train and evaluate BERTbased models for detecting paraphrase in Armenian, achieving results comparable to the state-of-the-art of other languages.
Word Embeddings for the Armenian Language: Intrinsic and Extrinsic Evaluation
Jun 07, 2019
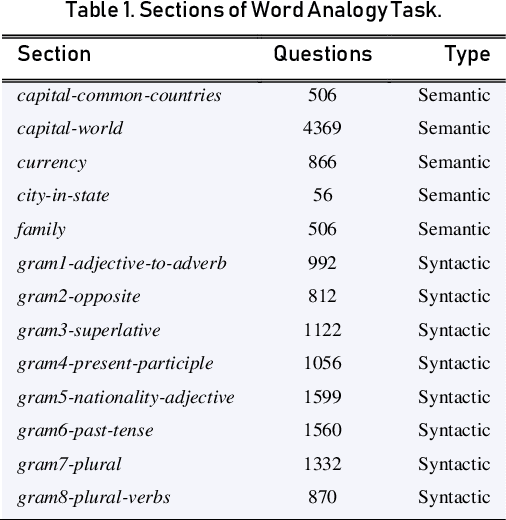
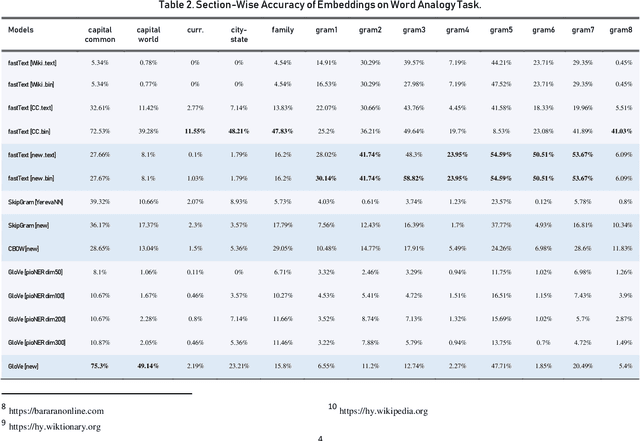
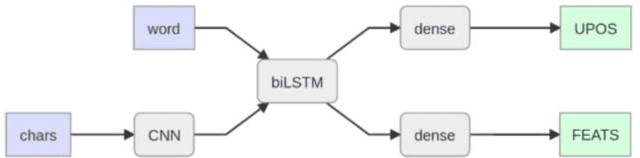
In this work, we intrinsically and extrinsically evaluate and compare existing word embedding models for the Armenian language. Alongside, new embeddings are presented, trained using GloVe, fastText, CBOW, SkipGram algorithms. We adapt and use the word analogy task in intrinsic evaluation of embeddings. For extrinsic evaluation, two tasks are employed: morphological tagging and text classification. Tagging is performed on a deep neural network, using ArmTDP v2.3 dataset. For text classification, we propose a corpus of news articles categorized into 7 classes. The datasets are made public to serve as benchmarks for future models.
pioNER: Datasets and Baselines for Armenian Named Entity Recognition
Oct 19, 2018
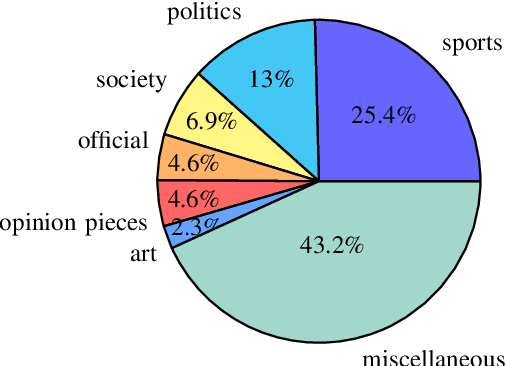
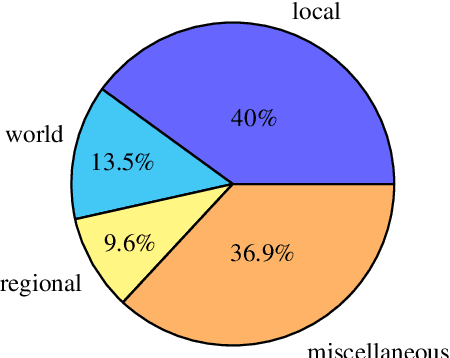
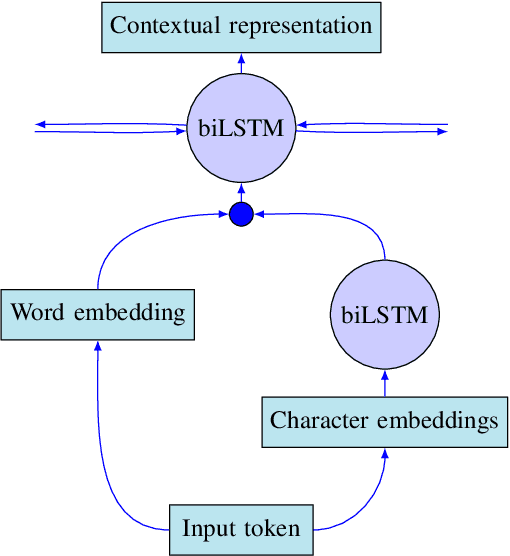
In this work, we tackle the problem of Armenian named entity recognition, providing silver- and gold-standard datasets as well as establishing baseline results on popular models. We present a 163000-token named entity corpus automatically generated and annotated from Wikipedia, and another 53400-token corpus of news sentences with manual annotation of people, organization and location named entities. The corpora were used to train and evaluate several popular named entity recognition models. Alongside the datasets, we release 50-, 100-, 200-, 300-dimensional GloVe word embeddings trained on a collection of Armenian texts from Wikipedia, news, blogs, and encyclopedia.