 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Effective Method of Cross-Lingual Plagiarism Detection
Apr 05, 2023We present a simple cross-lingual plagiarism detection method applicable to a large number of languages. The presented approach leverages open multilingual thesauri for candidate retrieval task and pre-trained multilingual BERT-based language models for detailed analysis. The method does not rely on machine translation and word sense disambiguation when in use, and therefore is suitable for a large number of languages, including under-resourced languages. The effectiveness of the proposed approach is demonstrated for several existing and new benchmarks, achieving state-of-the-art results for French, Russian, and Armenian languages.
ARPA: Armenian Paraphrase Detection Corpus and Models
Sep 26, 2020

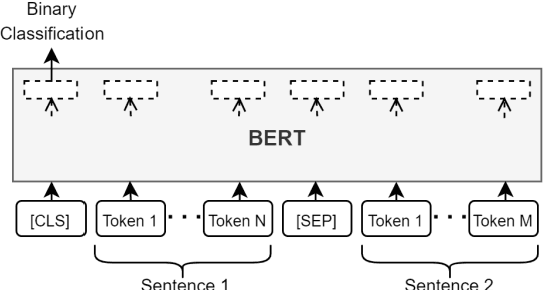
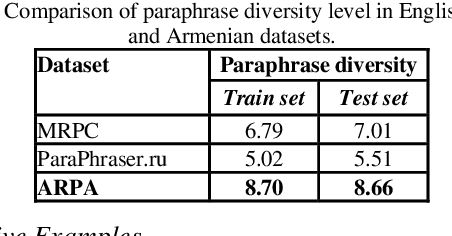
In this work, we employ a semi-automatic method based on back translation to generate a sentential paraphrase corpus for the Armenian language. The initial collection of sentences is translated from Armenian to English and back twice, resulting in pairs of lexically distant but semantically similar sentences. The generated paraphrases are then manually reviewed and annotated. Using the method train and test datasets are created, containing 2360 paraphrases in total. In addition, the datasets are used to train and evaluate BERTbased models for detecting paraphrase in Armenian, achieving results comparable to the state-of-the-art of other languages.