 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Transformers Learn to Verify During Backtracking Search?
May 21, 2026Backtracking search underlies classical constraint solvers, planners, and theorem provers. Recent transformer-based reasoning systems explore search trees over their own intermediate steps. A common training recipe fits an autoregressive next-token loss on offline solver traces. The model's input at each step is a cumulative trace of all prior decisions. The optimal continue-or-backtrack predictor depends only on the current search state, since two trajectories reaching the same state admit the same viable continuations. We show that decoder-only transformers trained on cumulative traces fail this requirement in two ways: the trace can scatter state features across many positions (scattered retrieval), and the predictor can condition on the trajectory rather than the state (history entanglement). We address scattered retrieval with localization, a trace-level fix that rewrites each decision block to expose state features locally. We address history entanglement with Selective State Attention (SSA), a fixed attention mask that enforces state-based decisions structurally without modifying training data, objective, or parameters. We focus on reactive verification, after propagation has exposed a contradiction. We test SSA on 3-SAT, graph coloring, Blocks World, and backtracking parsing. On same-state pairs that differ only in prior history, SSA emits identical decisions while a cumulative-trained causal baseline does not. Our contribution is a diagnostic of transformer behavior on serialized trajectory data, paired with a structural fix. Pretrained language models that search over their own reasoning steps may face the same failure. Our analysis opens up inference-time context clearing as a candidate way to apply the same isolation without retraining.
Symbolic AI for XAI: Evaluating LFIT Inductive Programming for Fair and Explainable Automatic Recruitment
Dec 01, 2020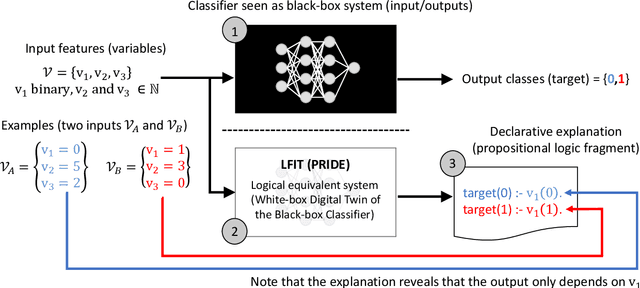
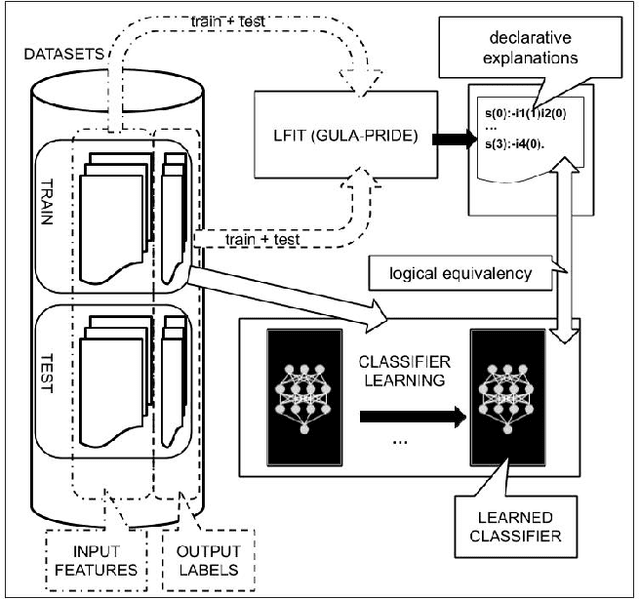
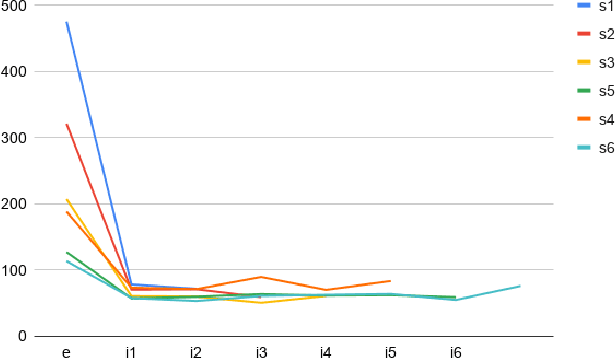
Machine learning methods are growing in relevance for biometrics and personal information processing in domains such as forensics, e-health, recruitment, and e-learning. In these domains, white-box (human-readable) explanations of systems built on machine learning methods can become crucial. Inductive Logic Programming (ILP) is a subfield of symbolic AI aimed to automatically learn declarative theories about the process of data. Learning from Interpretation Transition (LFIT) is an ILP technique that can learn a propositional logic theory equivalent to a given black-box system (under certain conditions). The present work takes a first step to a general methodology to incorporate accurate declarative explanations to classic machine learning by checking the viability of LFIT in a specific AI application scenario: fair recruitment based on an automatic tool generated with machine learning methods for ranking Curricula Vitae that incorporates soft biometric information (gender and ethnicity). We show the expressiveness of LFIT for this specific problem and propose a scheme that can be applicable to other domains.