 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Active Search and Tracking by Multiple Agents in Untrusted, Dynamically Changing Environments
Feb 03, 2025



This paper addresses the problem of both actively searching and tracking multiple unknown dynamic objects in a known environment with multiple cooperative autonomous agents with partial observability. The tracking of a target ends when the uncertainty is below a threshold. Current methods typically assume homogeneous agents without access to external information and utilize short-horizon target predictive models. Such assumptions limit real-world applications. We propose a fully integrated pipeline where the main contributions are: (1) a time-varying weighted belief representation capable of handling knowledge that changes over time, which includes external reports of varying levels of trustworthiness in addition to the agents; (2) the integration of a Long Short Term Memory-based trajectory prediction within the optimization framework for long-horizon decision-making, which reasons in time-configuration space, thus increasing responsiveness; and (3) a comprehensive system that accounts for multiple agents and enables information-driven optimization. When communication is available, our strategy consolidates exploration results collected asynchronously by agents and external sources into a headquarters, who can allocate each agent to maximize the overall team's utility, using all available information. We tested our approach extensively in simulations against baselines, and in robustness and ablation studies. In addition, we performed experiments in a 3D physics based engine robot simulator to test the applicability in the real world, as well as with real-world trajectories obtained from an oceanography computational fluid dynamics simulator. Results show the effectiveness of our method, which achieves mission completion times 1.3 to 3.2 times faster in finding all targets, even under the most challenging scenarios where the number of targets is 5 times greater than that of the agents.
UAV-CROWD: Violent and non-violent crowd activity simulator from the perspective of UAV
Aug 13, 2022
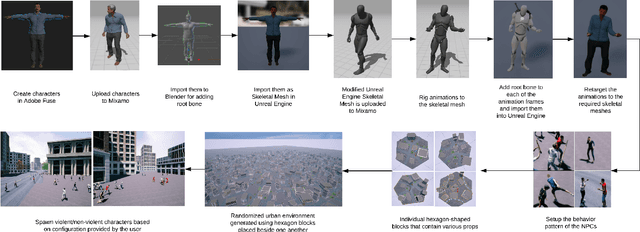
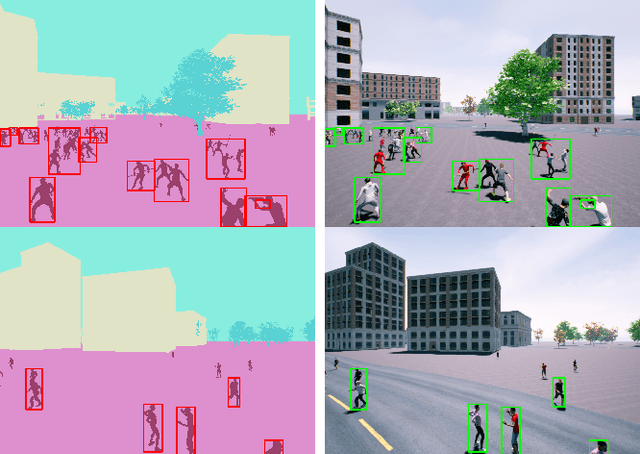
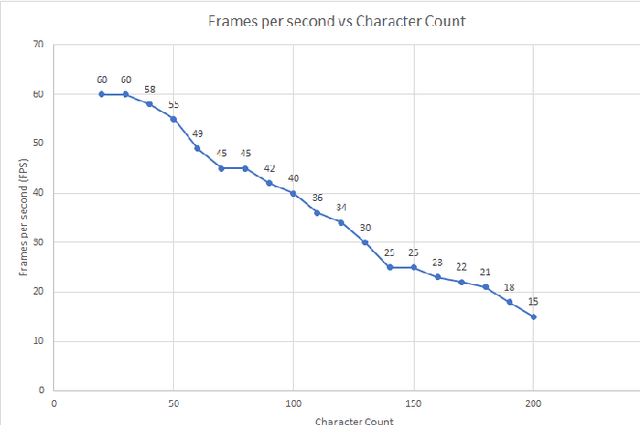
Unmanned Aerial Vehicle (UAV) has gained significant traction in the recent years, particularly the context of surveillance. However, video datasets that capture violent and non-violent human activity from aerial point-of-view is scarce. To address this issue, we propose a novel, baseline simulator which is capable of generating sequences of photo-realistic synthetic images of crowds engaging in various activities that can be categorized as violent or non-violent. The crowd groups are annotated with bounding boxes that are automatically computed using semantic segmentation. Our simulator is capable of generating large, randomized urban environments and is able to maintain an average of 25 frames per second on a mid-range computer with 150 concurrent crowd agents interacting with each other. We also show that when synthetic data from the proposed simulator is augmented with real world data, binary video classification accuracy is improved by 5% on average across two different models.
Variational Stacked Local Attention Networks for Diverse Video Captioning
Jan 04, 2022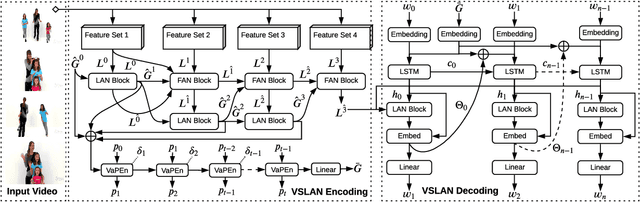

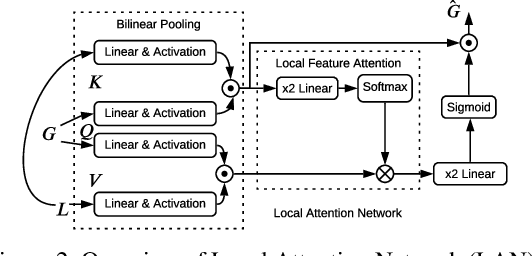
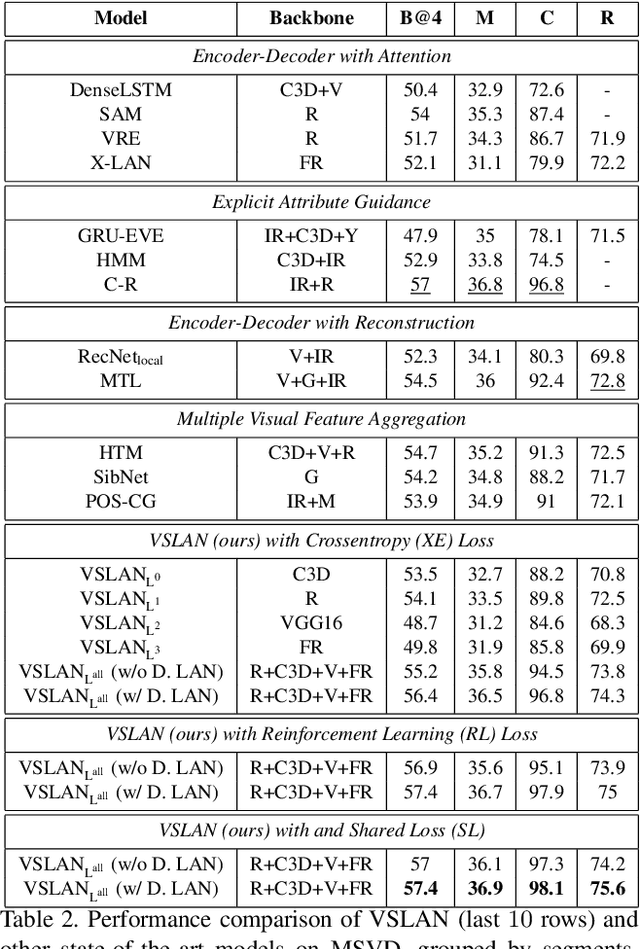
While describing Spatio-temporal events in natural language, video captioning models mostly rely on the encoder's latent visual representation. Recent progress on the encoder-decoder model attends encoder features mainly in linear interaction with the decoder. However, growing model complexity for visual data encourages more explicit feature interaction for fine-grained information, which is currently absent in the video captioning domain. Moreover, feature aggregations methods have been used to unveil richer visual representation, either by the concatenation or using a linear layer. Though feature sets for a video semantically overlap to some extent, these approaches result in objective mismatch and feature redundancy. In addition, diversity in captions is a fundamental component of expressing one event from several meaningful perspectives, currently missing in the temporal, i.e., video captioning domain. To this end, we propose Variational Stacked Local Attention Network (VSLAN), which exploits low-rank bilinear pooling for self-attentive feature interaction and stacking multiple video feature streams in a discount fashion. Each feature stack's learned attributes contribute to our proposed diversity encoding module, followed by the decoding query stage to facilitate end-to-end diverse and natural captions without any explicit supervision on attributes. We evaluate VSLAN on MSVD and MSR-VTT datasets in terms of syntax and diversity. The CIDEr score of VSLAN outperforms current off-the-shelf methods by $7.8\%$ on MSVD and $4.5\%$ on MSR-VTT, respectively. On the same datasets, VSLAN achieves competitive results in caption diversity metrics.