 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attack in the Physical World
Apr 24, 2021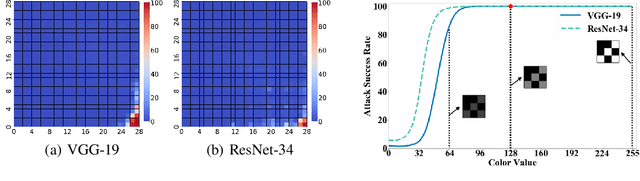
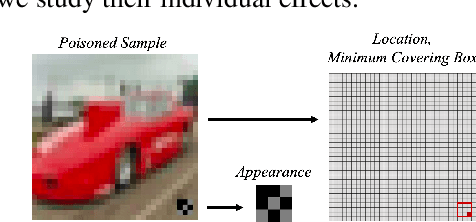

Backdoor attack intends to inject hidden backdoor into the deep neural networks (DNNs), such that the prediction of infected models will be maliciously changed if the hidden backdoor is activated by the attacker-defined trigger. Currently, most existing backdoor attacks adopted the setting of static trigger, $i.e.,$ triggers across the training and testing images follow the same appearance and are located in the same area. In this paper, we revisit this attack paradigm by analyzing trigger characteristics. We demonstrate that this attack paradigm is vulnerable when the trigger in testing images is not consistent with the one used for training. As such, those attacks are far less effective in the physical world, where the location and appearance of the trigger in the digitized image may be different from that of the one used for training. Moreover, we also discuss how to alleviate such vulnerability. We hope that this work could inspire more explorations on backdoor properties, to help the design of more advanced backdoor attack and defense methods.
Backdoor Attack against Speaker Verification
Oct 25, 2020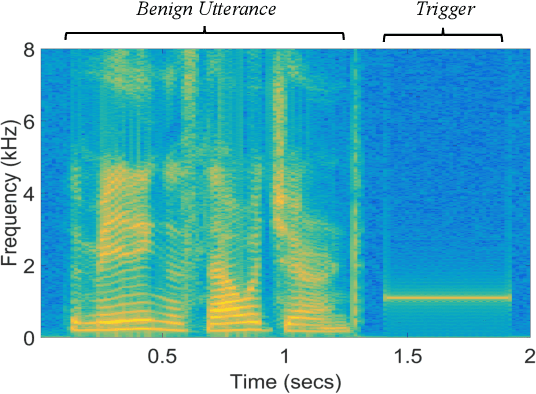
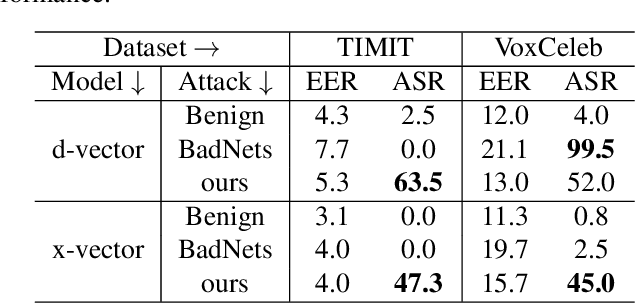
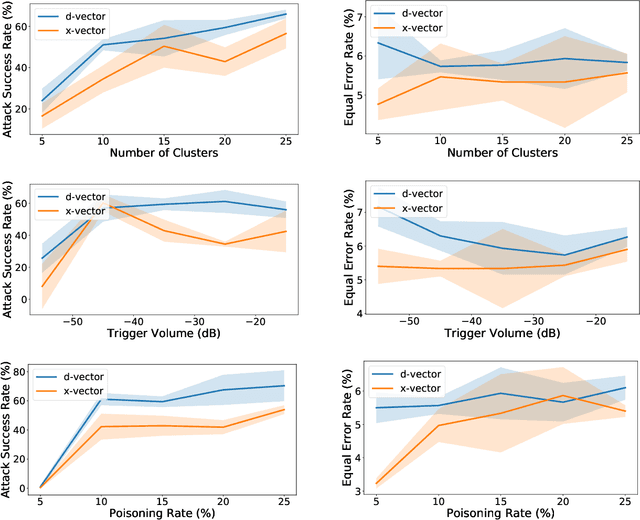
Speaker verification has been widely and successfully adopted in many mission-critical areas for user identification. The training of speaker verification requires a large amount of data, therefore users usually need to adopt third-party data ($e.g.$, data from the Internet or third-party data company). This raises the question of whether adopting untrusted third-party data can pose a security threat. In this paper, we demonstrate that it is possible to inject the hidden backdoor for infecting speaker verification models by poisoning the training data. Specifically, we design a clustering-based attack scheme where poisoned samples from different clusters will contain different triggers ($i.e.$, pre-defined utterances), based on our understanding of verification tasks. The infected models behave normally on benign samples, while attacker-specified unenrolled triggers will successfully pass the verification even if the attacker has no information about the enrolled speaker. We also demonstrate that existing backdoor attacks can not be directly adopted in attacking speaker verification. Our attack not only provides a new perspective for designing novel attacks, but also serves as a strong baseline for improving the robustness of verification methods.
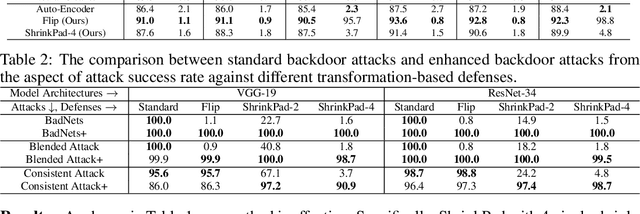
Rethinking the Trigger of Backdoor Attack
Apr 09, 2020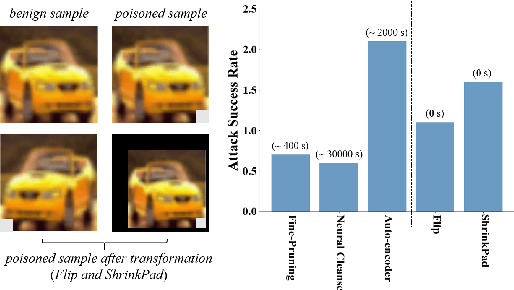
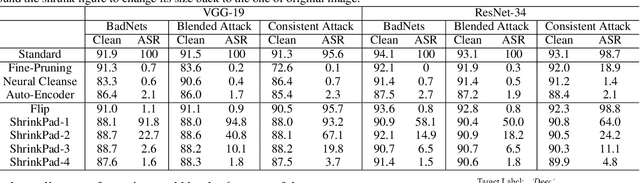
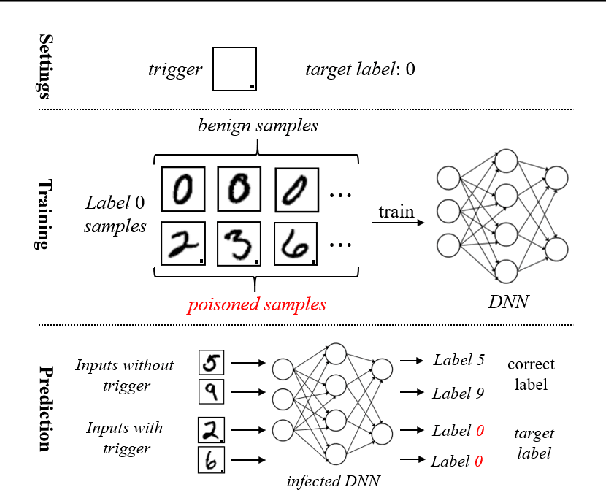
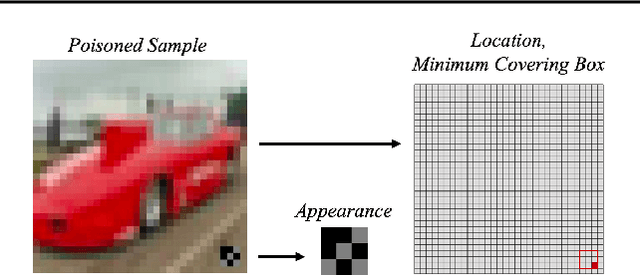
In this work, we study the problem of backdoor attacks, which add a specific trigger ($i.e.$, a local patch) onto some training images to enforce that the testing images with the same trigger are incorrectly predicted while the natural testing examples are correctly predicted by the trained model. Many existing works adopted the setting that the triggers across the training and testing images follow the same appearance and are located at the same area. However, we observe that if the appearance or location of the trigger is slightly changed, then the attack performance may degrade sharply. According to this observation, we propose to spatially transform ($e.g.$, flipping and scaling) the testing image, such that the appearance and location of the trigger (if exists) will be changed. This simple strategy is experimentally verified to be effective to defend many state-of-the-art backdoor attack methods. Furthermore, to enhance the robustness of the backdoor attacks, we propose to conduct the random spatial transformation on the training images with the trigger before feeding into the training process. Extensive experiments verify that the proposed backdoor attack is robust to spatial transformations.