 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$C^*$-algebra Net: A New Approach Generalizing Neural Network Parameters to $C^*$-algebra
Jun 22, 2022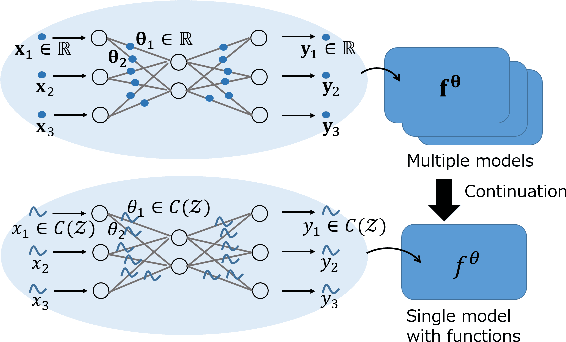

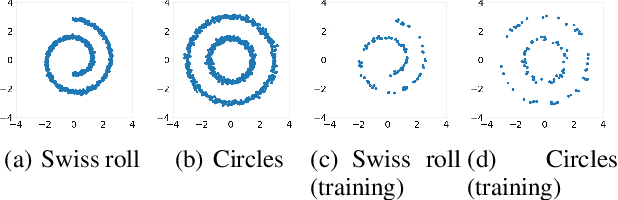
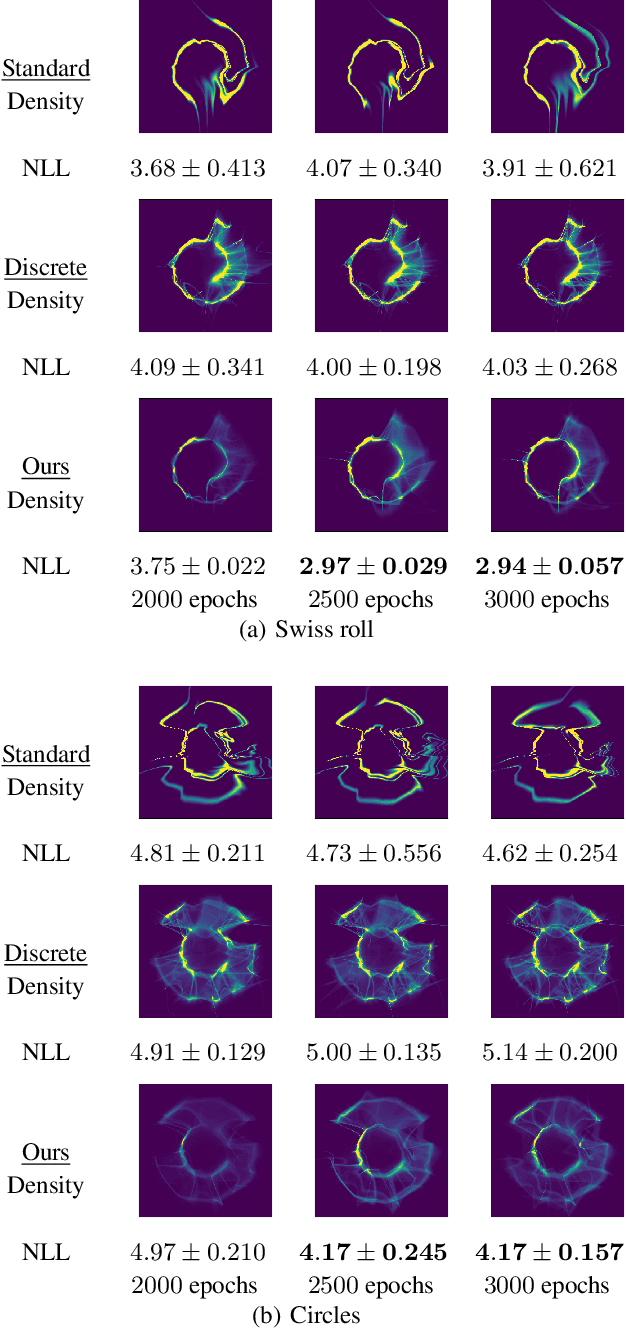
We propose a new framework that generalizes the parameters of neural network models to $C^*$-algebra-valued ones. $C^*$-algebra is a generalization of the space of complex numbers. A typical example is the space of continuous functions on a compact space. This generalization enables us to combine multiple models continuously and use tools for functions such as regression and integration. Consequently, we can learn features of data efficiently and adapt the models to problems continuously. We apply our framework to practical problems such as density estimation and few-shot learning and show that our framework enables us to learn features of data even with a limited number of samples. Our new framework highlights the potential possibility of applying the theory of $C^*$-algebra to general neural network models.
A kernel for time series based on global alignments
Oct 06, 2006
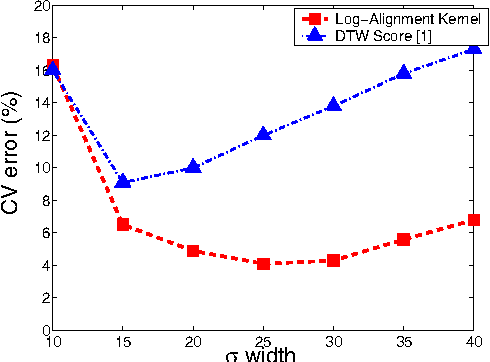
We propose in this paper a new family of kernels to handle times series, notably speech data, within the framework of kernel methods which includes popular algorithms such as the Support Vector Machine. These kernels elaborate on the well known Dynamic Time Warping (DTW) family of distances by considering the same set of elementary operations, namely substitutions and repetitions of tokens, to map a sequence onto another. Associating to each of these operations a given score, DTW algorithms use dynamic programming techniques to compute an optimal sequence of operations with high overall score. In this paper we consider instead the score spanned by all possible alignments, take a smoothed version of their maximum and derive a kernel out of this formulation. We prove that this kernel is positive definite under favorable conditions and show how it can be tuned effectively for practical applications as we report encouraging results on a speech recognition task.