 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Relative Density-Ratio Estimation
Jul 02, 2021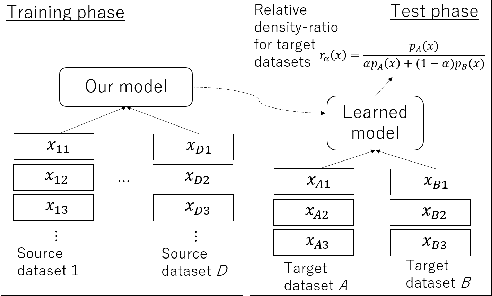
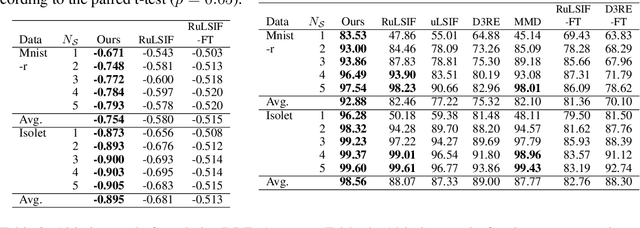

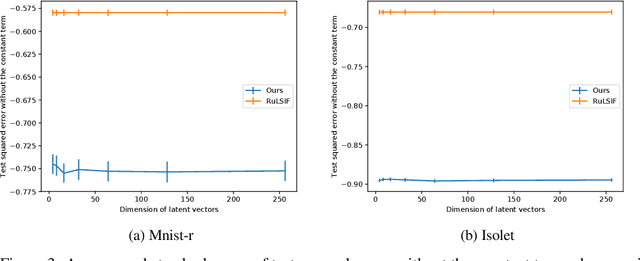
The ratio of two probability densities, called a density-ratio, is a vital quantity in machine learning. In particular, a relative density-ratio, which is a bounded extension of the density-ratio, has received much attention due to its stability and has been used in various applications such as outlier detection and dataset comparison. Existing methods for (relative) density-ratio estimation (DRE) require many instances from both densities. However, sufficient instances are often unavailable in practice. In this paper, we propose a meta-learning method for relative DRE, which estimates the relative density-ratio from a few instances by using knowledge in related datasets. Specifically, given two datasets that consist of a few instances, our model extracts the datasets' information by using neural networks and uses it to obtain instance embeddings appropriate for the relative DRE. We model the relative density-ratio by a linear model on the embedded space, whose global optimum solution can be obtained as a closed-form solution. The closed-form solution enables fast and effective adaptation to a few instances, and its differentiability enables us to train our model such that the expected test error for relative DRE can be explicitly minimized after adapting to a few instances. We empirically demonstrate the effectiveness of the proposed method by using three problems: relative DRE, dataset comparison, and outlier detection.
Meta-learning for Matrix Factorization without Shared Rows or Columns
Jun 29, 2021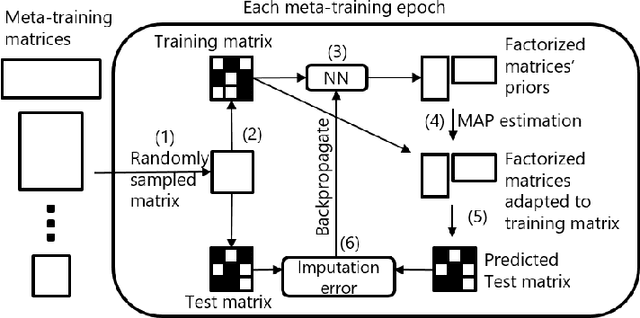
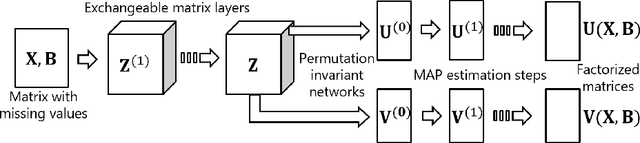
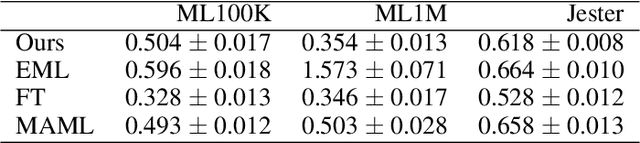
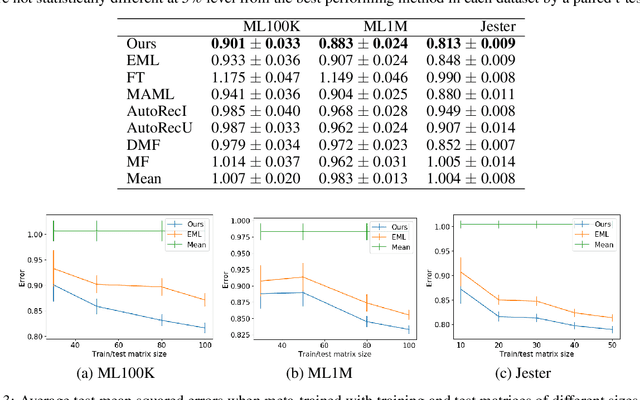
We propose a method that meta-learns a knowledge on matrix factorization from various matrices, and uses the knowledge for factorizing unseen matrices. The proposed method uses a neural network that takes a matrix as input, and generates prior distributions of factorized matrices of the given matrix. The neural network is meta-learned such that the expected imputation error is minimized when the factorized matrices are adapted to each matrix by a maximum a posteriori (MAP) estimation. We use a gradient descent method for the MAP estimation, which enables us to backpropagate the expected imputation error through the gradient descent steps for updating neural network parameters since each gradient descent step is written in a closed form and is differentiable. The proposed method can meta-learn from matrices even when their rows and columns are not shared, and their sizes are different from each other. In our experiments with three user-item rating datasets, we demonstrate that our proposed method can impute the missing values from a limited number of observations in unseen matrices after being trained with different matrices.
Loss function based second-order Jensen inequality and its application to particle variational inference
Jun 10, 2021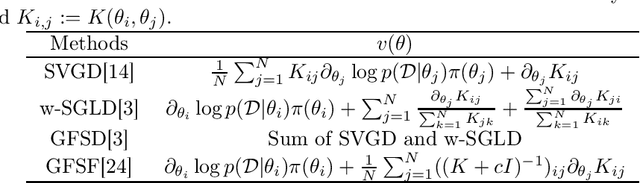
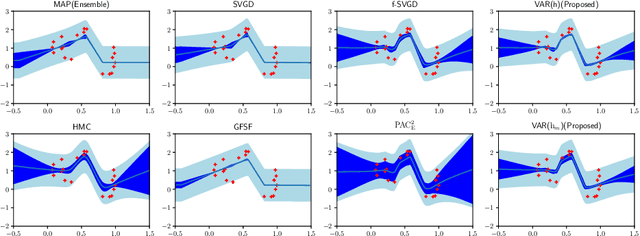
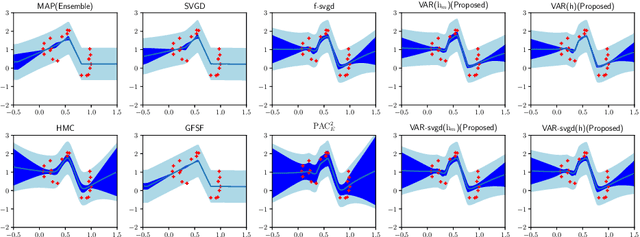
Bayesian model averaging, obtained as the expectation of a likelihood function by a posterior distribution, has been widely used for prediction, evaluation of uncertainty, and model selection. Various approaches have been developed to efficiently capture the information in the posterior distribution; one such approach is the optimization of a set of models simultaneously with interaction to ensure the diversity of the individual models in the same way as ensemble learning. A representative approach is particle variational inference (PVI), which uses an ensemble of models as an empirical approximation for the posterior distribution. PVI iteratively updates each model with a repulsion force to ensure the diversity of the optimized models. However, despite its promising performance, a theoretical understanding of this repulsion and its association with the generalization ability remains unclear. In this paper, we tackle this problem in light of PAC-Bayesian analysis. First, we provide a new second-order Jensen inequality, which has the repulsion term based on the loss function. Thanks to the repulsion term, it is tighter than the standard Jensen inequality. Then, we derive a novel generalization error bound and show that it can be reduced by enhancing the diversity of models. Finally, we derive a new PVI that optimizes the generalization error bound directly. Numerical experiments demonstrate that the performance of the proposed PVI compares favorably with existing methods in the experiment.
Dynamic Hawkes Processes for Discovering Time-evolving Communities' States behind Diffusion Processes
Jun 06, 2021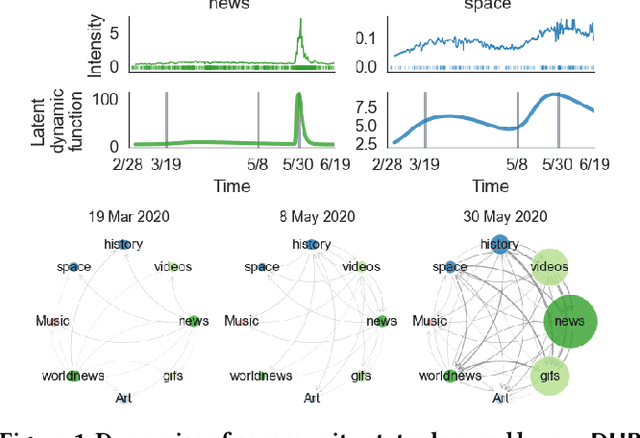
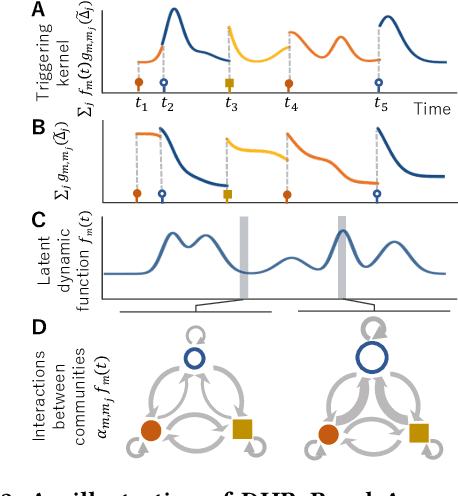
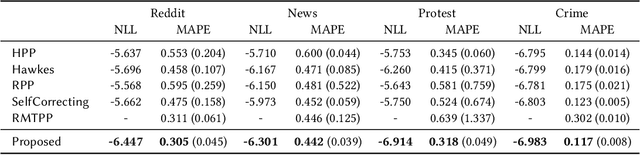
Sequences of events including infectious disease outbreaks, social network activities, and crimes are ubiquitous and the data on such events carry essential information about the underlying diffusion processes between communities (e.g., regions, online user groups). Modeling diffusion processes and predicting future events are crucial in many applications including epidemic control, viral marketing, and predictive policing. Hawkes processes offer a central tool for modeling the diffusion processes, in which the influence from the past events is described by the triggering kernel. However, the triggering kernel parameters, which govern how each community is influenced by the past events, are assumed to be static over time. In the real world, the diffusion processes depend not only on the influences from the past, but also the current (time-evolving) states of the communities, e.g., people's awareness of the disease and people's current interests. In this paper, we propose a novel Hawkes process model that is able to capture the underlying dynamics of community states behind the diffusion processes and predict the occurrences of events based on the dynamics. Specifically, we model the latent dynamic function that encodes these hidden dynamics by a mixture of neural networks. Then we design the triggering kernel using the latent dynamic function and its integral. The proposed method, termed DHP (Dynamic Hawkes Processes), offers a flexible way to learn complex representations of the time-evolving communities' states, while at the same time it allows to computing the exact likelihood, which makes parameter learning tractable. Extensive experiments on four real-world event datasets show that DHP outperforms five widely adopted methods for event prediction.
Few-shot Learning for Topic Modeling
Apr 19, 2021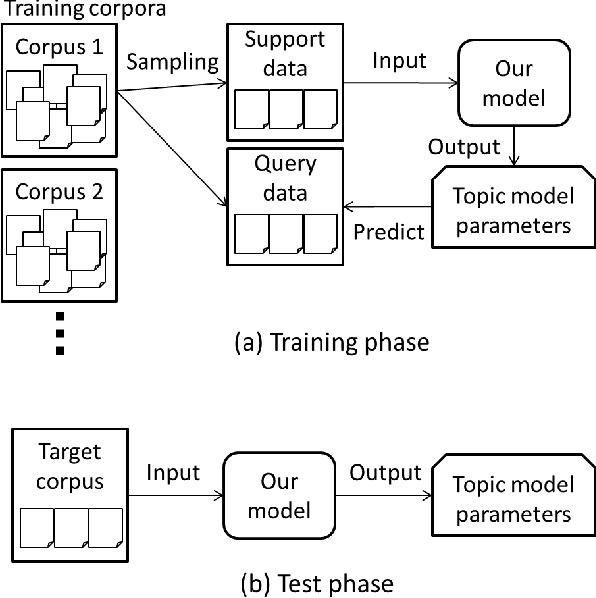

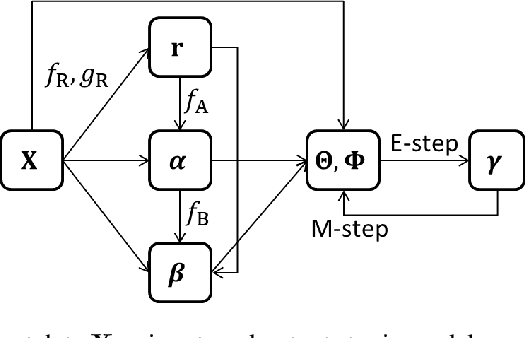
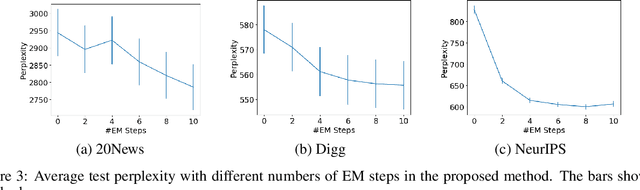
Topic models have been successfully used for analyzing text documents. However, with existing topic models, many documents are required for training. In this paper, we propose a neural network-based few-shot learning method that can learn a topic model from just a few documents. The neural networks in our model take a small number of documents as inputs, and output topic model priors. The proposed method trains the neural networks such that the expected test likelihood is improved when topic model parameters are estimated by maximizing the posterior probability using the priors based on the EM algorithm. Since each step in the EM algorithm is differentiable, the proposed method can backpropagate the loss through the EM algorithm to train the neural networks. The expected test likelihood is maximized by a stochastic gradient descent method using a set of multiple text corpora with an episodic training framework. In our experiments, we demonstrate that the proposed method achieves better perplexity than existing methods using three real-world text document sets.
Meta-learning representations for clustering with infinite Gaussian mixture models
Mar 01, 2021

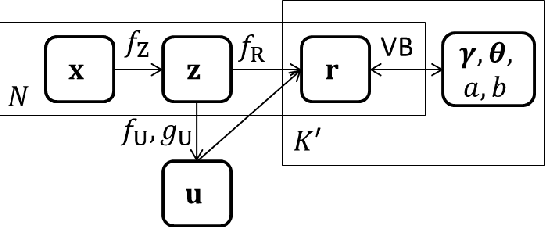
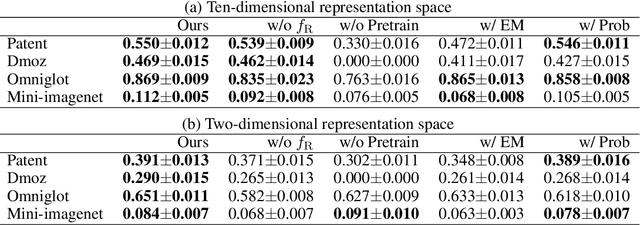
For better clustering performance, appropriate representations are critical. Although many neural network-based metric learning methods have been proposed, they do not directly train neural networks to improve clustering performance. We propose a meta-learning method that train neural networks for obtaining representations such that clustering performance improves when the representations are clustered by the variational Bayesian (VB) inference with an infinite Gaussian mixture model. The proposed method can cluster unseen unlabeled data using knowledge meta-learned with labeled data that are different from the unlabeled data. For the objective function, we propose a continuous approximation of the adjusted Rand index (ARI), by which we can evaluate the clustering performance from soft clustering assignments. Since the approximated ARI and the VB inference procedure are differentiable, we can backpropagate the objective function through the VB inference procedure to train the neural networks. With experiments using text and image data sets, we demonstrate that our proposed method has a higher adjusted Rand index than existing methods do.
Meta-learning One-class Classifiers with Eigenvalue Solvers for Supervised Anomaly Detection
Mar 01, 2021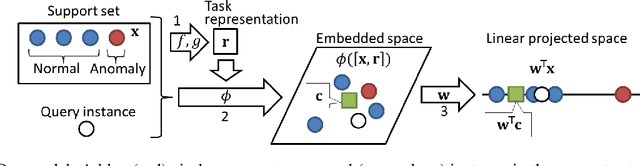
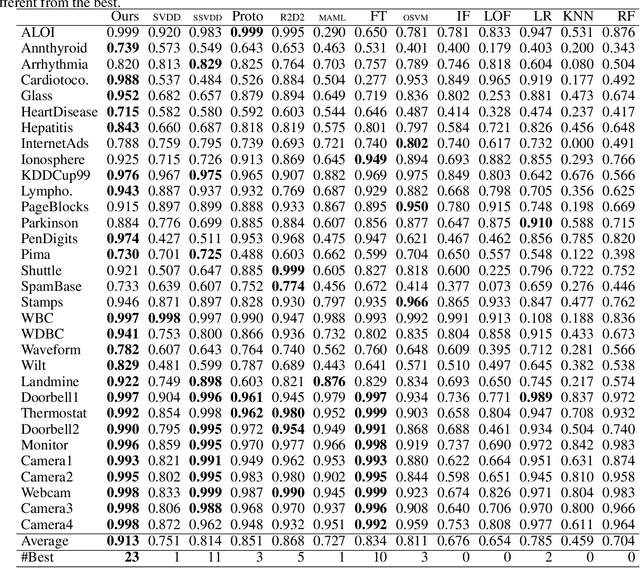
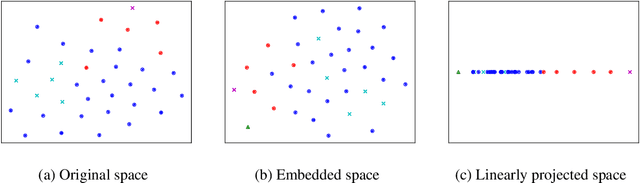
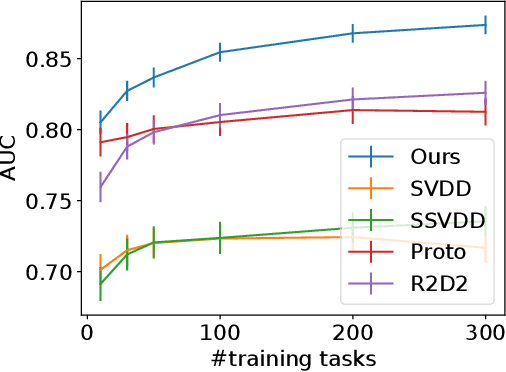
Neural network-based anomaly detection methods have shown to achieve high performance. However, they require a large amount of training data for each task. We propose a neural network-based meta-learning method for supervised anomaly detection. The proposed method improves the anomaly detection performance on unseen tasks, which contains a few labeled normal and anomalous instances, by meta-training with various datasets. With a meta-learning framework, quick adaptation to each task and its effective backpropagation are important since the model is trained by the adaptation for each epoch. Our model enables them by formulating adaptation as a generalized eigenvalue problem with one-class classification; its global optimum solution is obtained, and the solver is differentiable. We experimentally demonstrate that the proposed method achieves better performance than existing anomaly detection and few-shot learning methods on various datasets.
Meta-Learning for Koopman Spectral Analysis with Short Time-series
Feb 09, 2021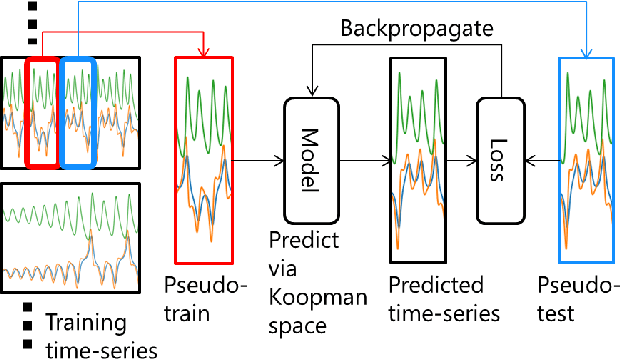
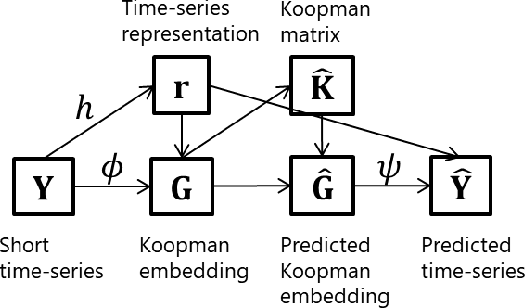
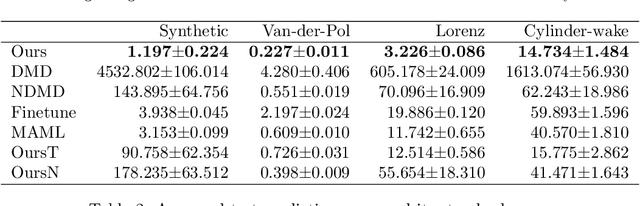
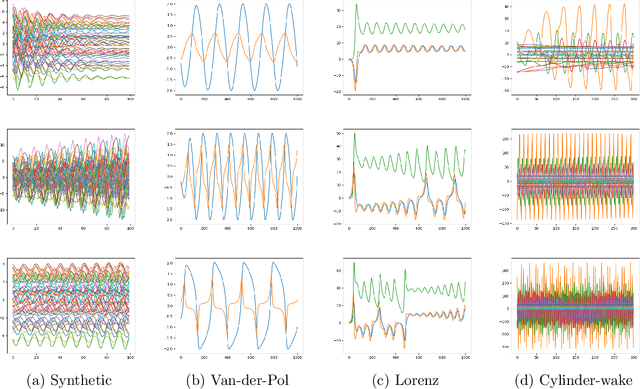
Koopman spectral analysis has attracted attention for nonlinear dynamical systems since we can analyze nonlinear dynamics with a linear regime by embedding data into a Koopman space by a nonlinear function. For the analysis, we need to find appropriate embedding functions. Although several neural network-based methods have been proposed for learning embedding functions, existing methods require long time-series for training neural networks. This limitation prohibits performing Koopman spectral analysis in applications where only short time-series are available. In this paper, we propose a meta-learning method for estimating embedding functions from unseen short time-series by exploiting knowledge learned from related but different time-series. With the proposed method, a representation of a given short time-series is obtained by a bidirectional LSTM for extracting its properties. The embedding function of the short time-series is modeled by a neural network that depends on the time-series representation. By sharing the LSTM and neural networks across multiple time-series, we can learn common knowledge from different time-series while modeling time-series-specific embedding functions with the time-series representation. Our model is trained such that the expected test prediction error is minimized with the episodic training framework. We experimentally demonstrate that the proposed method achieves better performance in terms of eigenvalue estimation and future prediction than existing methods.
Adversarial Training Makes Weight Loss Landscape Sharper in Logistic Regression
Feb 05, 2021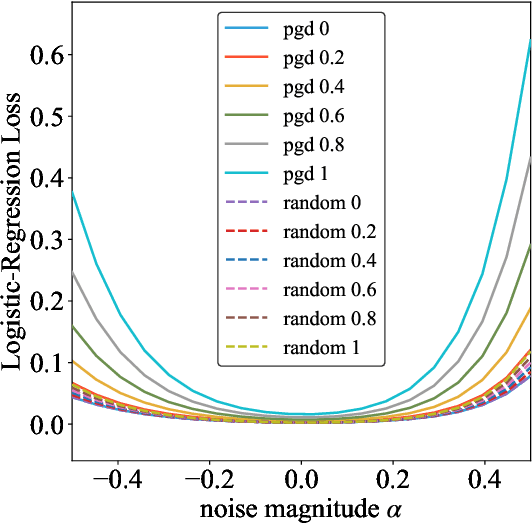
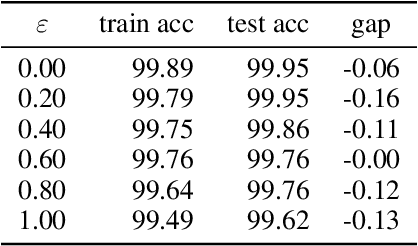
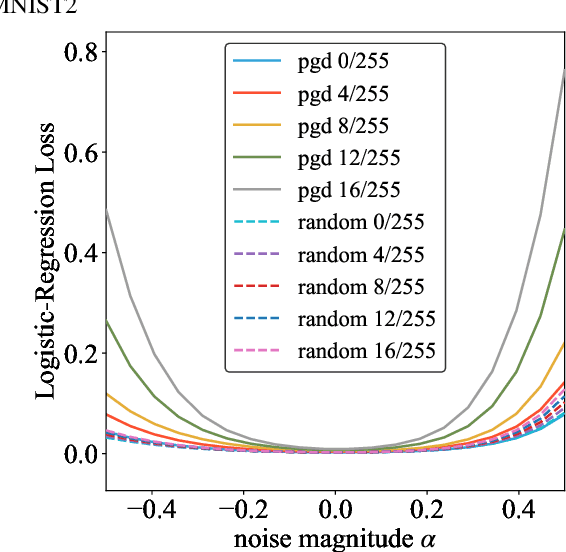
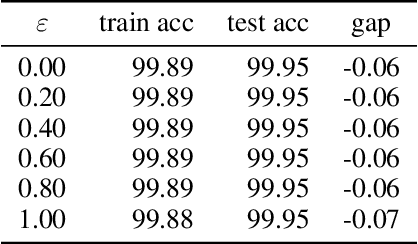
Adversarial training is actively studied for learning robust models against adversarial examples. A recent study finds that adversarially trained models degenerate generalization performance on adversarial examples when their weight loss landscape, which is loss changes with respect to weights, is sharp. Unfortunately, it has been experimentally shown that adversarial training sharpens the weight loss landscape, but this phenomenon has not been theoretically clarified. Therefore, we theoretically analyze this phenomenon in this paper. As a first step, this paper proves that adversarial training with the L2 norm constraints sharpens the weight loss landscape in the linear logistic regression model. Our analysis reveals that the sharpness of the weight loss landscape is caused by the noise aligned in the direction of increasing the loss, which is used in adversarial training. We theoretically and experimentally confirm that the weight loss landscape becomes sharper as the magnitude of the noise of adversarial training increases in the linear logistic regression model. Moreover, we experimentally confirm the same phenomena in ResNet18 with softmax as a more general case.
Neural Dynamic Mode Decomposition for End-to-End Modeling of Nonlinear Dynamics
Dec 11, 2020

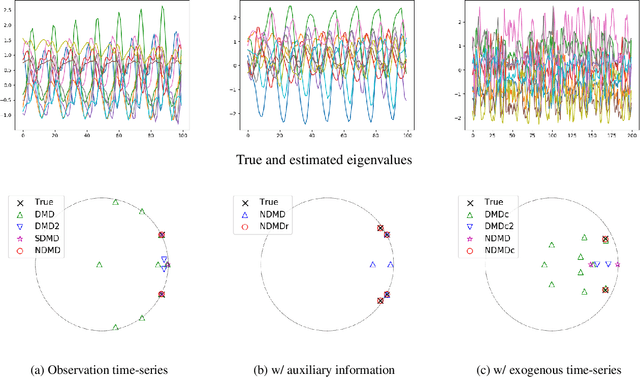
Koopman spectral analysis has attracted attention for understanding nonlinear dynamical systems by which we can analyze nonlinear dynamics with a linear regime by lifting observations using a nonlinear function. For analysis, we need to find an appropriate lift function. Although several methods have been proposed for estimating a lift function based on neural networks, the existing methods train neural networks without spectral analysis. In this paper, we propose neural dynamic mode decomposition, in which neural networks are trained such that the forecast error is minimized when the dynamics is modeled based on spectral decomposition in the lifted space. With our proposed method, the forecast error is backpropagated through the neural networks and the spectral decomposition, enabling end-to-end learning of Koopman spectral analysis. When information is available on the frequencies or the growth rates of the dynamics, the proposed method can exploit it as regularizers for training. We also propose an extension of our approach when observations are influenced by exogenous control time-series. Our experiments demonstrate the effectiveness of our proposed method in terms of eigenvalue estimation and forecast performance.