 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Physics-Informed Machine Learning for Data Center Operations: A Tropical Case Study
May 26, 2025



Data centers are the backbone of computing capacity. Operating data centers in the tropical regions faces unique challenges due to consistently high ambient temperature and elevated relative humidity throughout the year. These conditions result in increased cooling costs to maintain the reliability of the computing systems. While existing machine learning-based approaches have demonstrated potential to elevate operations to a more proactive and intelligent level, their deployment remains dubious due to concerns about model extrapolation capabilities and associated system safety issues. To address these concerns, this article proposes incorporating the physical characteristics of data centers into traditional data-driven machine learning solutions. We begin by introducing the data center system, including the relevant multiphysics processes and the data-physics availability. Next, we outline the associated modeling and optimization problems and propose an integrated, physics-informed machine learning system to address them. Using the proposed system, we present relevant applications across varying levels of operational intelligence. A case study on an industry-grade tropical data center is provided to demonstrate the effectiveness of our approach. Finally, we discuss key challenges and highlight potential future directions.
Counting Protests in News Articles: A Dataset and Semi-Automated Data Collection Pipeline
Feb 01, 2021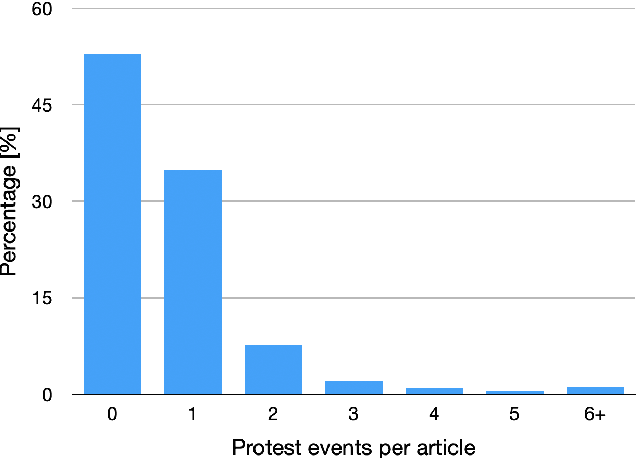
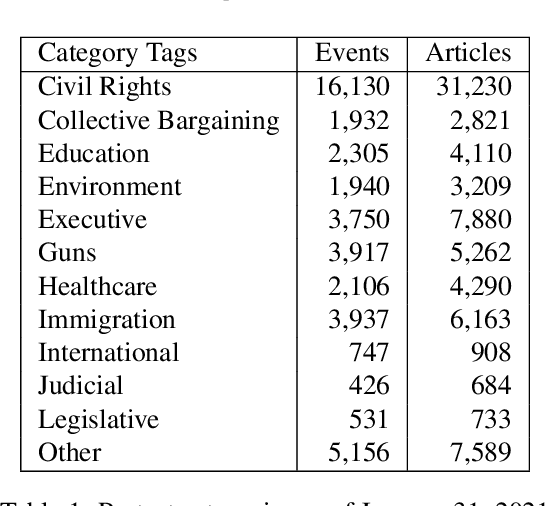
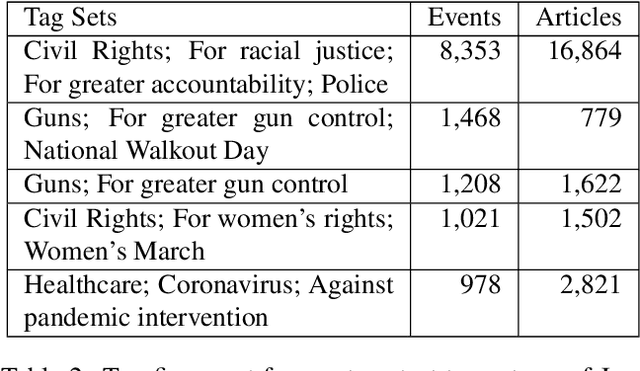
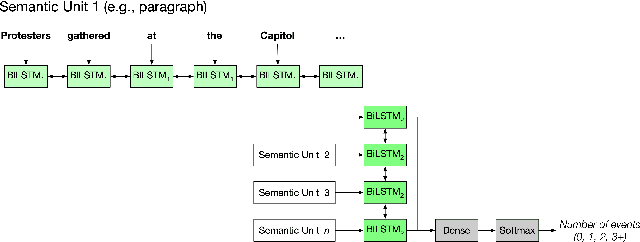
Between January 2017 and January 2021, thousands of local news sources in the United States reported on over 42,000 protests about topics such as civil rights, immigration, guns, and the environment. Given the vast number of local journalists that report on protests daily, extracting these events as structured data to understand temporal and geographic trends can empower civic decision-making. However, the task of extracting events from news articles presents well known challenges to the NLP community in the fields of domain detection, slot filling, and coreference resolution. To help improve the resources available for extracting structured data from news stories, our contribution is three-fold. We 1) release a manually labeled dataset of news article URLs, dates, locations, crowd size estimates, and 494 discrete descriptive tags corresponding to 42,347 reported protest events in the United States between January 2017 and January 2021; 2) describe the semi-automated data collection pipeline used to discover, sort, and review the 144,568 English articles that comprise the dataset; and 3) benchmark a long-short term memory (LSTM) low dimensional classifier that demonstrates the utility of processing news articles based on syntactic structures, such as paragraphs and sentences, to count the number of reported protest events.