 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic set-valued optimization and its application to robust learning
Mar 18, 2026In this paper, we develop a stochastic set-valued optimization (SVO) framework tailored for robust machine learning. In the SVO setting, each decision variable is mapped to a set of objective values, and optimality is defined via set relations. We focus on SVO problems with hyperbox sets, which can be reformulated as multi-objective optimization (MOO) problems with finitely many objectives and serve as a foundation for representing or approximating more general mapped sets. Two special cases of hyperbox-valued optimization (HVO) are interval-valued (IVO) and rectangle-valued (RVO) optimization. We construct stochastic IVO/RVO formulations that incorporate subquantiles and superquantiles into the objective functions of the MOO reformulations, providing a new characterization for subquantiles. These formulations provide interpretable trade-offs by capturing both lower- and upper-tail behaviors of loss distributions, thereby going beyond standard empirical risk minimization and classical robust models. To solve the resulting multi-objective problems, we adopt stochastic multi-gradient algorithms and select a Pareto knee solution. In numerical experiments, the proposed algorithms with this selection strategy exhibit improved robustness and reduced variability across test replications under distributional shift compared with empirical risk minimization, while maintaining competitive accuracy.
A stochastic gradient method for trilevel optimization
May 11, 2025With the success that the field of bilevel optimization has seen in recent years, similar methodologies have started being applied to solving more difficult applications that arise in trilevel optimization. At the helm of these applications are new machine learning formulations that have been proposed in the trilevel context and, as a result, efficient and theoretically sound stochastic methods are required. In this work, we propose the first-ever stochastic gradient descent method for solving unconstrained trilevel optimization problems and provide a convergence theory that covers all forms of inexactness of the trilevel adjoint gradient, such as the inexact solutions of the middle-level and lower-level problems, inexact computation of the trilevel adjoint formula, and noisy estimates of the gradients, Hessians, Jacobians, and tensors of third-order derivatives involved. We also demonstrate the promise of our approach by providing numerical results on both synthetic trilevel problems and trilevel formulations for hyperparameter adversarial tuning.
The limitation of neural nets for approximation and optimization
Nov 21, 2023We are interested in assessing the use of neural networks as surrogate models to approximate and minimize objective functions in optimization problems. While neural networks are widely used for machine learning tasks such as classification and regression, their application in solving optimization problems has been limited. Our study begins by determining the best activation function for approximating the objective functions of popular nonlinear optimization test problems, and the evidence provided shows that~SiLU has the best performance. We then analyze the accuracy of function value, gradient, and Hessian approximations for such objective functions obtained through interpolation/regression models and neural networks. When compared to interpolation/regression models, neural networks can deliver competitive zero- and first-order approximations (at a high training cost) but underperform on second-order approximation. However, it is shown that combining a neural net activation function with the natural basis for quadratic interpolation/regression can waive the necessity of including cross terms in the natural basis, leading to models with fewer parameters to determine. Lastly, we provide evidence that the performance of a state-of-the-art derivative-free optimization algorithm can hardly be improved when the gradient of an objective function is approximated using any of the surrogate models considered, including neural networks.
Bilevel stochastic methods for optimization and machine learning: Bilevel stochastic descent and DARTS
Oct 01, 2021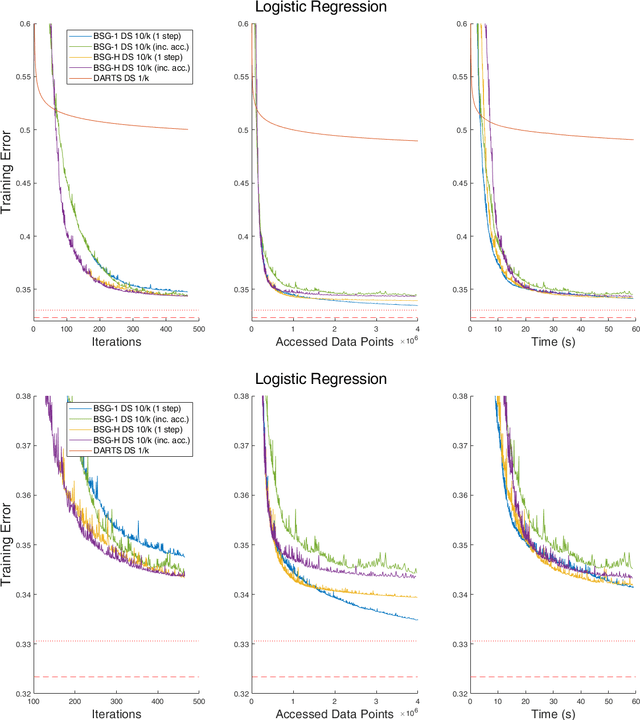
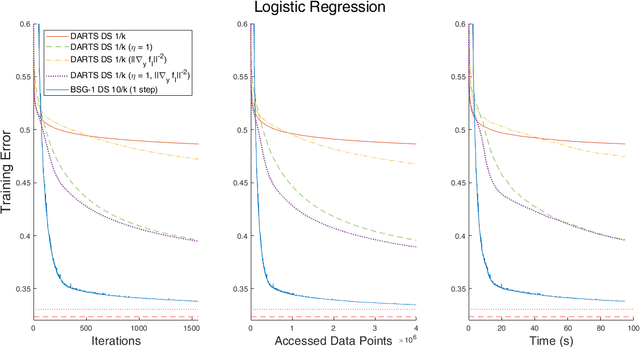
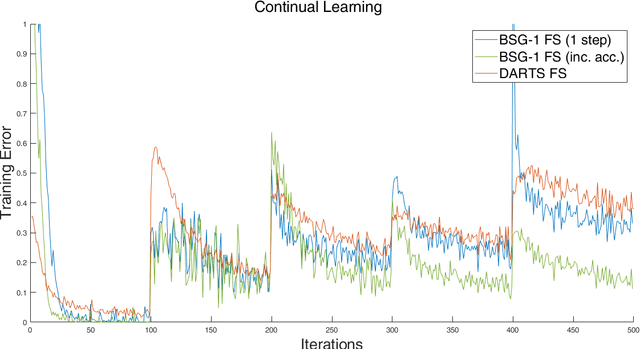
Two-level stochastic optimization formulations have become instrumental in a number of machine learning contexts such as neural architecture search, continual learning, adversarial learning, and hyperparameter tuning. Practical stochastic bilevel optimization problems become challenging in optimization or learning scenarios where the number of variables is high or there are constraints. The goal of this paper is twofold. First, we aim at promoting the use of bilevel optimization in large-scale learning and we introduce a practical bilevel stochastic gradient method (BSG-1) that requires neither lower level second-order derivatives nor system solves (and dismisses any matrix-vector products). Our BSG-1 method is close to first-order principles, which allows it to achieve a performance better than those that are not, such as DARTS. Second, we develop bilevel stochastic gradient descent for bilevel problems with lower level constraints, and we introduce a convergence theory that covers the unconstrained and constrained cases and abstracts as much as possible from the specifics of the bilevel gradient calculation.