 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA stochastic gradient method for trilevel optimization
May 11, 2025With the success that the field of bilevel optimization has seen in recent years, similar methodologies have started being applied to solving more difficult applications that arise in trilevel optimization. At the helm of these applications are new machine learning formulations that have been proposed in the trilevel context and, as a result, efficient and theoretically sound stochastic methods are required. In this work, we propose the first-ever stochastic gradient descent method for solving unconstrained trilevel optimization problems and provide a convergence theory that covers all forms of inexactness of the trilevel adjoint gradient, such as the inexact solutions of the middle-level and lower-level problems, inexact computation of the trilevel adjoint formula, and noisy estimates of the gradients, Hessians, Jacobians, and tensors of third-order derivatives involved. We also demonstrate the promise of our approach by providing numerical results on both synthetic trilevel problems and trilevel formulations for hyperparameter adversarial tuning.
The limitation of neural nets for approximation and optimization
Nov 21, 2023We are interested in assessing the use of neural networks as surrogate models to approximate and minimize objective functions in optimization problems. While neural networks are widely used for machine learning tasks such as classification and regression, their application in solving optimization problems has been limited. Our study begins by determining the best activation function for approximating the objective functions of popular nonlinear optimization test problems, and the evidence provided shows that~SiLU has the best performance. We then analyze the accuracy of function value, gradient, and Hessian approximations for such objective functions obtained through interpolation/regression models and neural networks. When compared to interpolation/regression models, neural networks can deliver competitive zero- and first-order approximations (at a high training cost) but underperform on second-order approximation. However, it is shown that combining a neural net activation function with the natural basis for quadratic interpolation/regression can waive the necessity of including cross terms in the natural basis, leading to models with fewer parameters to determine. Lastly, we provide evidence that the performance of a state-of-the-art derivative-free optimization algorithm can hardly be improved when the gradient of an objective function is approximated using any of the surrogate models considered, including neural networks.
Convergence rates of the stochastic alternating algorithm for bi-objective optimization
Mar 20, 2022Stochastic alternating algorithms for bi-objective optimization are considered when optimizing two conflicting functions for which optimization steps have to be applied separately for each function. Such algorithms consist of applying a certain number of steps of gradient or subgradient descent on each single objective at each iteration. In this paper, we show that stochastic alternating algorithms achieve a sublinear convergence rate of $\mathcal{O}(1/T)$, under strong convexity, for the determination of a minimizer of a weighted-sum of the two functions, parameterized by the number of steps applied on each of them. An extension to the convex case is presented for which the rate weakens to $\mathcal{O}(1/\sqrt{T})$. These rates are valid also in the non-smooth case. Importantly, by varying the proportion of steps applied to each function, one can determine an approximation to the Pareto front.
Bilevel stochastic methods for optimization and machine learning: Bilevel stochastic descent and DARTS
Oct 01, 2021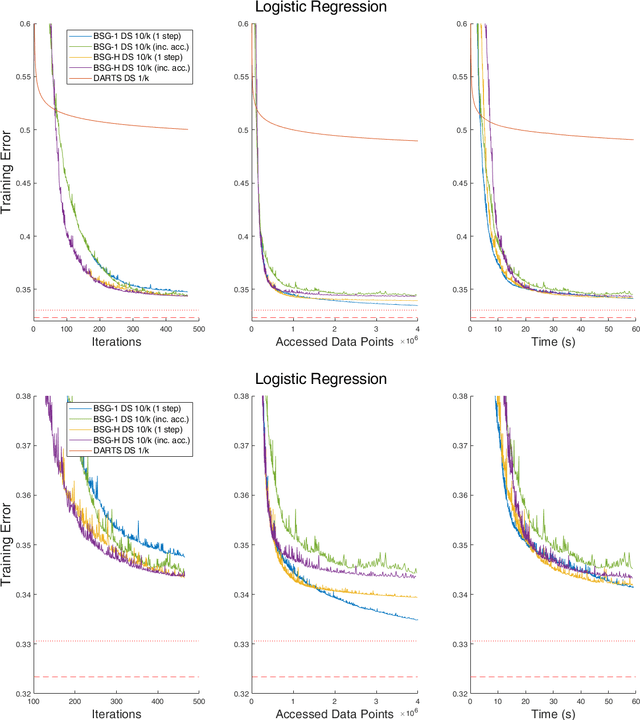
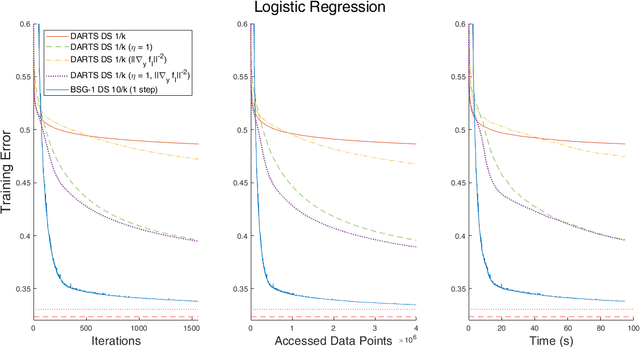
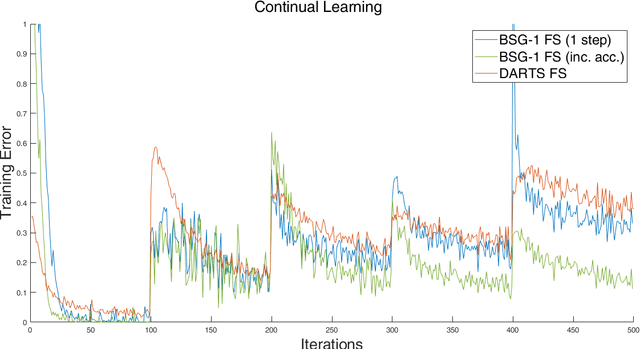
Two-level stochastic optimization formulations have become instrumental in a number of machine learning contexts such as neural architecture search, continual learning, adversarial learning, and hyperparameter tuning. Practical stochastic bilevel optimization problems become challenging in optimization or learning scenarios where the number of variables is high or there are constraints. The goal of this paper is twofold. First, we aim at promoting the use of bilevel optimization in large-scale learning and we introduce a practical bilevel stochastic gradient method (BSG-1) that requires neither lower level second-order derivatives nor system solves (and dismisses any matrix-vector products). Our BSG-1 method is close to first-order principles, which allows it to achieve a performance better than those that are not, such as DARTS. Second, we develop bilevel stochastic gradient descent for bilevel problems with lower level constraints, and we introduce a convergence theory that covers the unconstrained and constrained cases and abstracts as much as possible from the specifics of the bilevel gradient calculation.
The Sharpe predictor for fairness in machine learning
Aug 13, 2021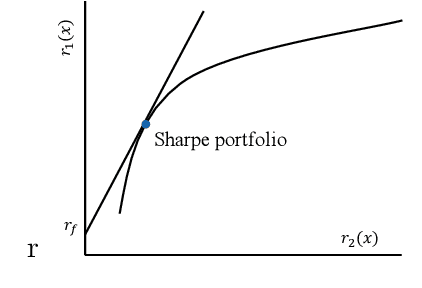
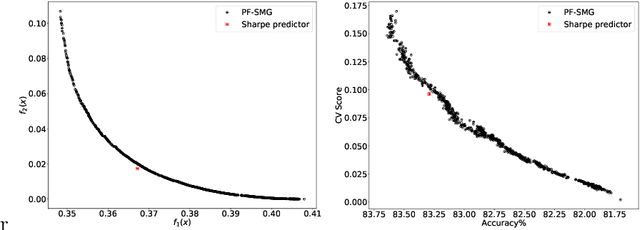
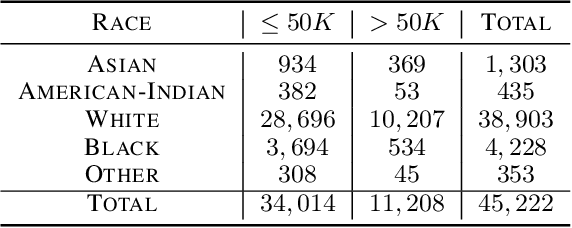
In machine learning (ML) applications, unfair predictions may discriminate against a minority group. Most existing approaches for fair machine learning (FML) treat fairness as a constraint or a penalization term in the optimization of a ML model, which does not lead to the discovery of the complete landscape of the trade-offs among learning accuracy and fairness metrics, and does not integrate fairness in a meaningful way. Recently, we have introduced a new paradigm for FML based on Stochastic Multi-Objective Optimization (SMOO), where accuracy and fairness metrics stand as conflicting objectives to be optimized simultaneously. The entire trade-offs range is defined as the Pareto front of the SMOO problem, which can then be efficiently computed using stochastic-gradient type algorithms. SMOO also allows defining and computing new meaningful predictors for FML, a novel one being the Sharpe predictor that we introduce and explore in this paper, and which gives the highest ratio of accuracy-to-unfairness. Inspired from SMOO in finance, the Sharpe predictor for FML provides the highest prediction return (accuracy) per unit of prediction risk (unfairness).
A Stochastic Alternating Balance $k$-Means Algorithm for Fair Clustering
May 29, 2021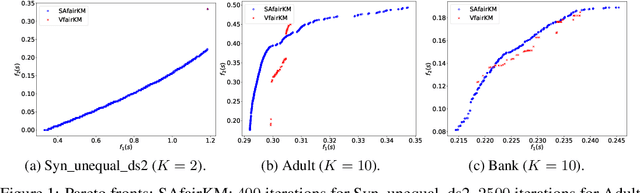
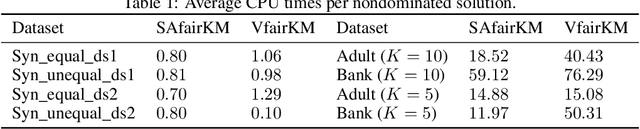
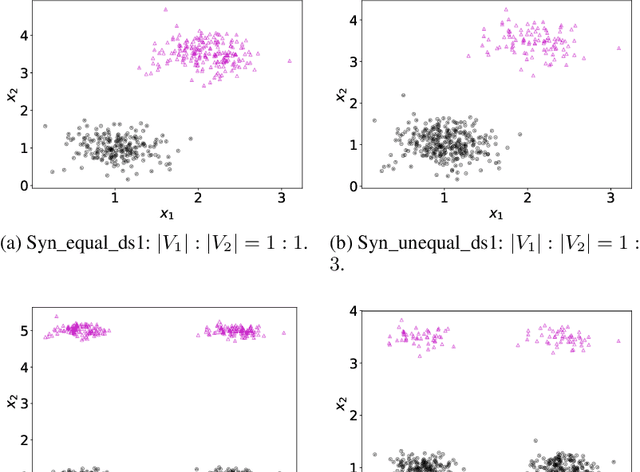
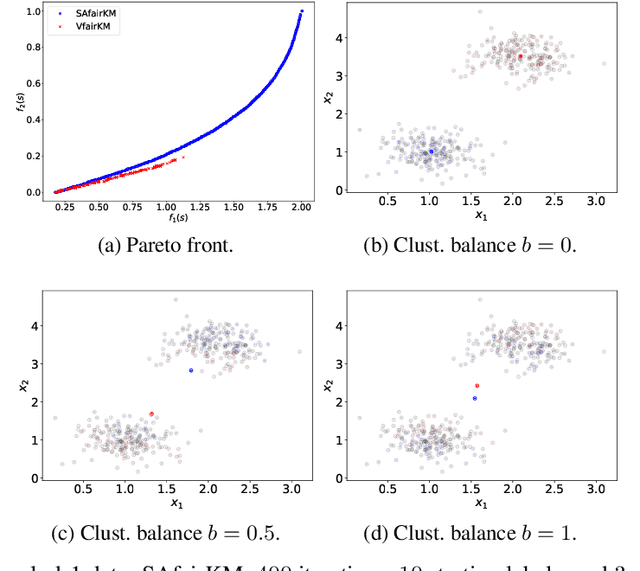
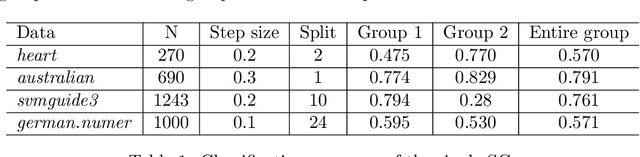
In the application of data clustering to human-centric decision-making systems, such as loan applications and advertisement recommendations, the clustering outcome might discriminate against people across different demographic groups, leading to unfairness. A natural conflict occurs between the cost of clustering (in terms of distance to cluster centers) and the balance representation of all demographic groups across the clusters, leading to a bi-objective optimization problem that is nonconvex and nonsmooth. To determine the complete trade-off between these two competing goals, we design a novel stochastic alternating balance fair $k$-means (SAfairKM) algorithm, which consists of alternating classical mini-batch $k$-means updates and group swap updates. The number of $k$-means updates and the number of swap updates essentially parameterize the weight put on optimizing each objective function. Our numerical experiments show that the proposed SAfairKM algorithm is robust and computationally efficient in constructing well-spread and high-quality Pareto fronts both on synthetic and real datasets. Moreover, we propose a novel companion algorithm, the stochastic alternating bi-objective gradient descent (SA2GD) algorithm, which can handle a smooth version of the considered bi-objective fair $k$-means problem, more amenable for analysis. A sublinear convergence rate of $\mathcal{O}(1/T)$ is established under strong convexity for the determination of a stationary point of a weighted sum of the two functions parameterized by the number of steps or updates on each function.
Accuracy and Fairness Trade-offs in Machine Learning: A Stochastic Multi-Objective Approach
Aug 03, 2020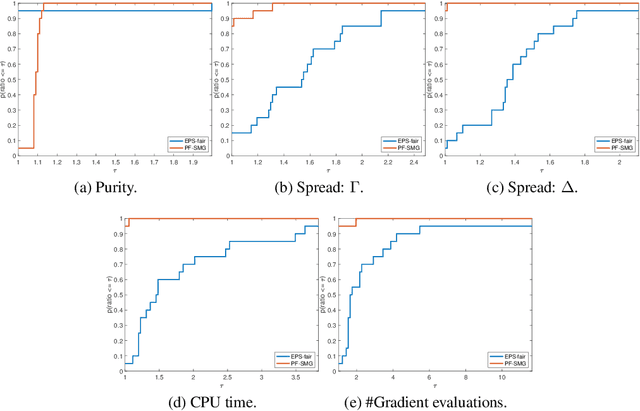
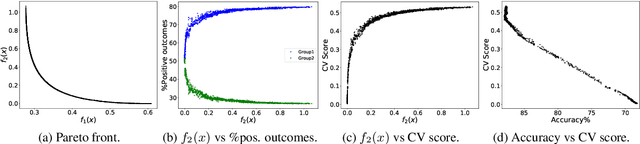
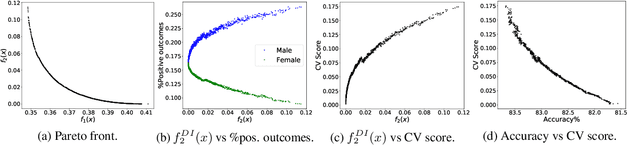
In the application of machine learning to real-life decision-making systems, e.g., credit scoring and criminal justice, the prediction outcomes might discriminate against people with sensitive attributes, leading to unfairness. The commonly used strategy in fair machine learning is to include fairness as a constraint or a penalization term in the minimization of the prediction loss, which ultimately limits the information given to decision-makers. In this paper, we introduce a new approach to handle fairness by formulating a stochastic multi-objective optimization problem for which the corresponding Pareto fronts uniquely and comprehensively define the accuracy-fairness trade-offs. We have then applied a stochastic approximation-type method to efficiently obtain well-spread and accurate Pareto fronts, and by doing so we can handle training data arriving in a streaming way.
The stochastic multi-gradient algorithm for multi-objective optimization and its application to supervised machine learning
Jul 17, 2019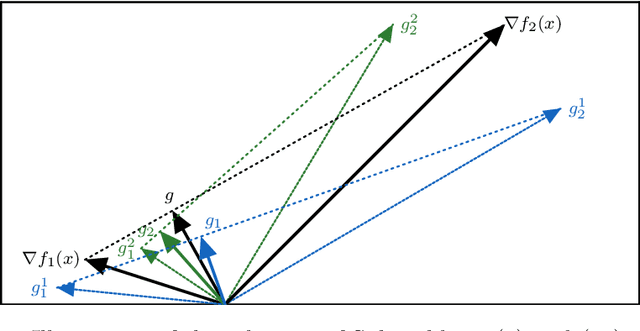
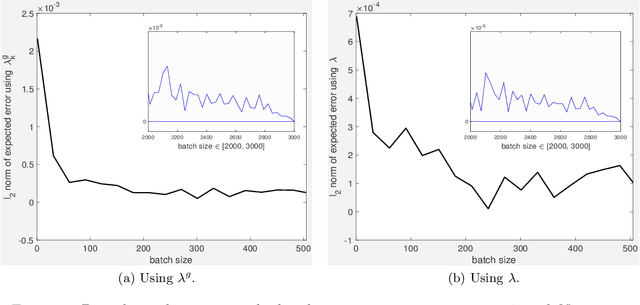
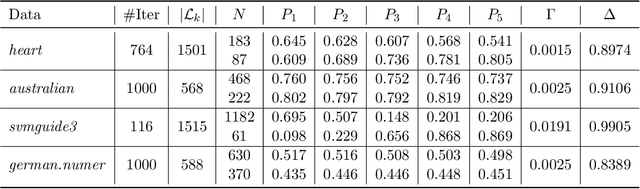
Optimization of conflicting functions is of paramount importance in decision making, and real world applications frequently involve data that is uncertain or unknown, resulting in multi-objective optimization (MOO) problems of stochastic type. We study the stochastic multi-gradient (SMG) method, seen as an extension of the classical stochastic gradient method for single-objective optimization. At each iteration of the SMG method, a stochastic multi-gradient direction is calculated by solving a quadratic subproblem, and it is shown that this direction is biased even when all individual gradient estimators are unbiased. We establish rates to compute a point in the Pareto front, of order similar to what is known for stochastic gradient in both convex and strongly convex cases. The analysis handles the bias in the multi-gradient and the unknown a priori weights of the limiting Pareto point. The SMG method is framed into a Pareto-front type algorithm for the computation of the entire Pareto front. The Pareto-front SMG algorithm is capable of robustly determining Pareto fronts for a number of synthetic test problems. One can apply it to any stochastic MOO problem arising from supervised machine learning, and we report results for logistic binary classification where multiple objectives correspond to distinct-sources data groups.