 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-Unstable Semantics: Beyond NP with Normal Logic Programs
Aug 15, 2016Standard answer set programming (ASP) targets at solving search problems from the first level of the polynomial time hierarchy (PH). Tackling search problems beyond NP using ASP is less straightforward. The class of disjunctive logic programs offers the most prominent way of reaching the second level of the PH, but encoding respective hard problems as disjunctive programs typically requires sophisticated techniques such as saturation or meta-interpretation. The application of such techniques easily leads to encodings that are inaccessible to non-experts. Furthermore, while disjunctive ASP solvers often rely on calls to a (co-)NP oracle, it may be difficult to detect from the input program where the oracle is being accessed. In other formalisms, such as Quantified Boolean Formulas (QBFs), the interface to the underlying oracle is more transparent as it is explicitly recorded in the quantifier prefix of a formula. On the other hand, ASP has advantages over QBFs from the modeling perspective. The rich high-level languages such as ASP-Core-2 offer a wide variety of primitives that enable concise and natural encodings of search problems. In this paper, we present a novel logic programming--based modeling paradigm that combines the best features of ASP and QBFs. We develop so-called combined logic programs in which oracles are directly cast as (normal) logic programs themselves. Recursive incarnations of this construction enable logic programming on arbitrarily high levels of the PH. We develop a proof-of-concept implementation for our new paradigm. This paper is under consideration for acceptance in TPLP.
Optimizing Phylogenetic Supertrees Using Answer Set Programming
Jul 19, 2015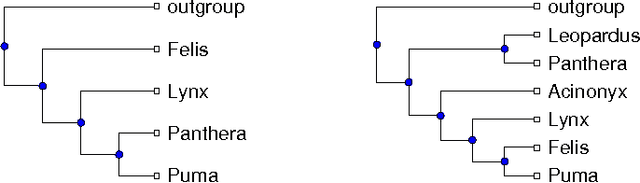
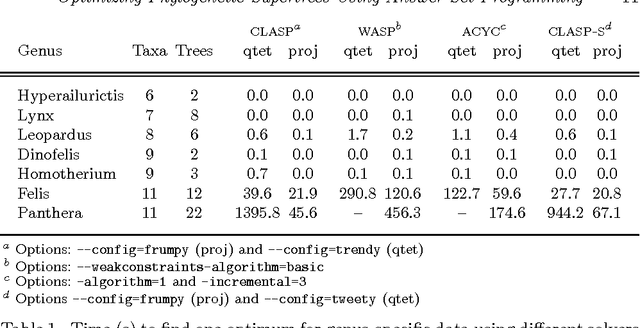
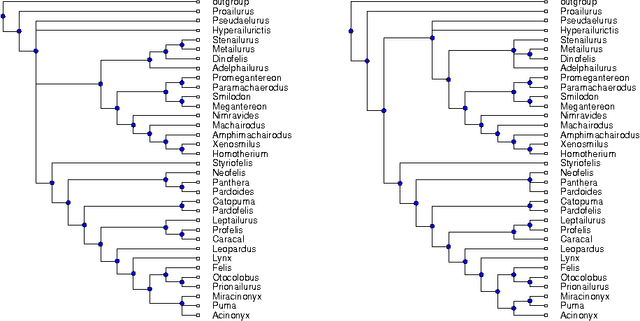
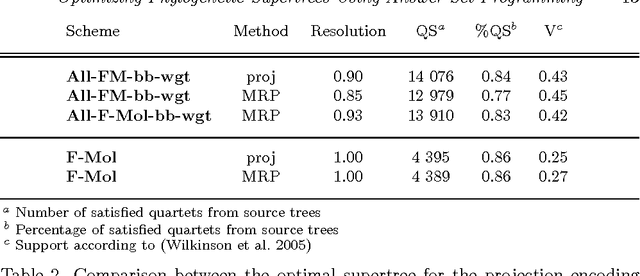
The supertree construction problem is about combining several phylogenetic trees with possibly conflicting information into a single tree that has all the leaves of the source trees as its leaves and the relationships between the leaves are as consistent with the source trees as possible. This leads to an optimization problem that is computationally challenging and typically heuristic methods, such as matrix representation with parsimony (MRP), are used. In this paper we consider the use of answer set programming to solve the supertree construction problem in terms of two alternative encodings. The first is based on an existing encoding of trees using substructures known as quartets, while the other novel encoding captures the relationships present in trees through direct projections. We use these encodings to compute a genus-level supertree for the family of cats (Felidae). Furthermore, we compare our results to recent supertrees obtained by the MRP method.
* To appear in Theory and Practice of Logic Programming (TPLP), Proceedings of ICLP 2015
Modularity Aspects of Disjunctive Stable Models
Jan 15, 2014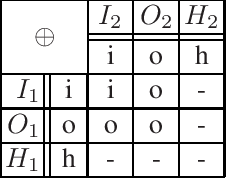
Practically all programming languages allow the programmer to split a program into several modules which brings along several advantages in software development. In this paper, we are interested in the area of answer-set programming where fully declarative and nonmonotonic languages are applied. In this context, obtaining a modular structure for programs is by no means straightforward since the output of an entire program cannot in general be composed from the output of its components. To better understand the effects of disjunctive information on modularity we restrict the scope of analysis to the case of disjunctive logic programs (DLPs) subject to stable-model semantics. We define the notion of a DLP-function, where a well-defined input/output interface is provided, and establish a novel module theorem which indicates the compositionality of stable-model semantics for DLP-functions. The module theorem extends the well-known splitting-set theorem and enables the decomposition of DLP-functions given their strongly connected components based on positive dependencies induced by rules. In this setting, it is also possible to split shared disjunctive rules among components using a generalized shifting technique. The concept of modular equivalence is introduced for the mutual comparison of DLP-functions using a generalization of a translation-based verification method.
Learning Chordal Markov Networks by Constraint Satisfaction
Oct 03, 2013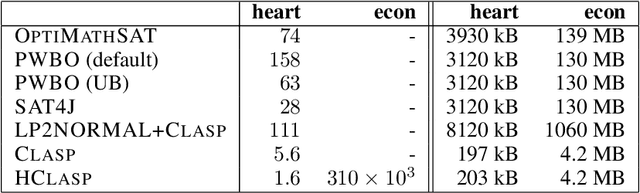
We investigate the problem of learning the structure of a Markov network from data. It is shown that the structure of such networks can be described in terms of constraints which enables the use of existing solver technology with optimization capabilities to compute optimal networks starting from initial scores computed from the data. To achieve efficient encodings, we develop a novel characterization of Markov network structure using a balancing condition on the separators between cliques forming the network. The resulting translations into propositional satisfiability and its extensions such as maximum satisfiability, satisfiability modulo theories, and answer set programming, enable us to prove optimal certain network structures which have been previously found by stochastic search.
Translating Answer-Set Programs into Bit-Vector Logic
Aug 30, 2011
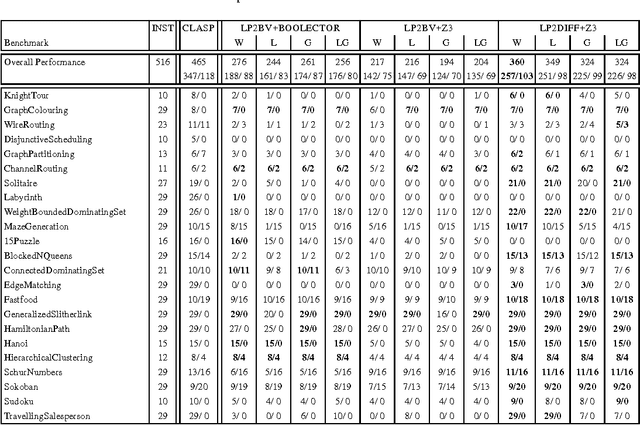
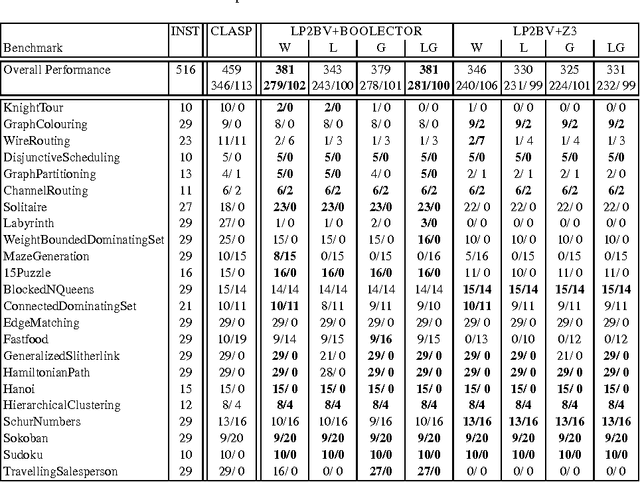
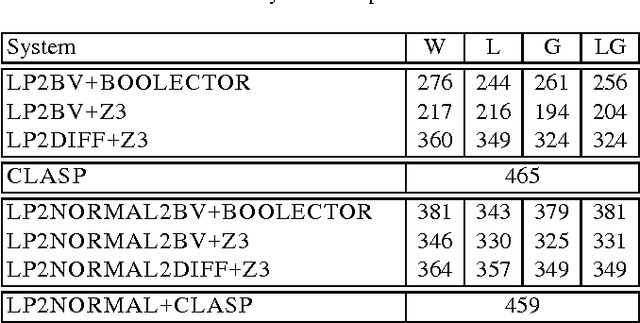
Answer set programming (ASP) is a paradigm for declarative problem solving where problems are first formalized as rule sets, i.e., answer-set programs, in a uniform way and then solved by computing answer sets for programs. The satisfiability modulo theories (SMT) framework follows a similar modelling philosophy but the syntax is based on extensions of propositional logic rather than rules. Quite recently, a translation from answer-set programs into difference logic was provided---enabling the use of particular SMT solvers for the computation of answer sets. In this paper, the translation is revised for another SMT fragment, namely that based on fixed-width bit-vector theories. Thus, even further SMT solvers can be harnessed for the task of computing answer sets. The results of a preliminary experimental comparison are also reported. They suggest a level of performance which is similar to that achieved via difference logic.
Achieving compositionality of the stable model semantics for Smodels programs
Sep 26, 2008In this paper, a Gaifman-Shapiro-style module architecture is tailored to the case of Smodels programs under the stable model semantics. The composition of Smodels program modules is suitably limited by module conditions which ensure the compatibility of the module system with stable models. Hence the semantics of an entire Smodels program depends directly on stable models assigned to its modules. This result is formalized as a module theorem which truly strengthens Lifschitz and Turner's splitting-set theorem for the class of Smodels programs. To streamline generalizations in the future, the module theorem is first proved for normal programs and then extended to cover Smodels programs using a translation from the latter class of programs to the former class. Moreover, the respective notion of module-level equivalence, namely modular equivalence, is shown to be a proper congruence relation: it is preserved under substitutions of modules that are modularly equivalent. Principles for program decomposition are also addressed. The strongly connected components of the respective dependency graph can be exploited in order to extract a module structure when there is no explicit a priori knowledge about the modules of a program. The paper includes a practical demonstration of tools that have been developed for automated (de)composition of Smodels programs. To appear in Theory and Practice of Logic Programming.
Automated verification of weak equivalence within the SMODELS system
Aug 25, 2006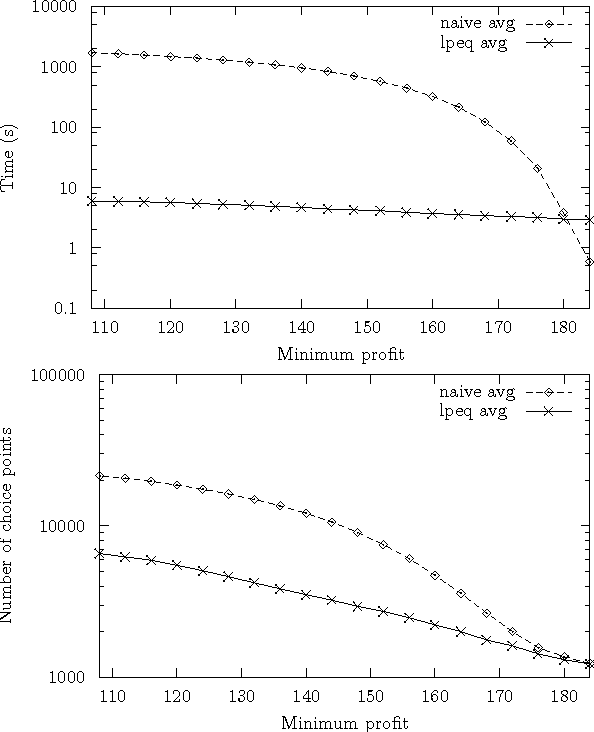
In answer set programming (ASP), a problem at hand is solved by (i) writing a logic program whose answer sets correspond to the solutions of the problem, and by (ii) computing the answer sets of the program using an answer set solver as a search engine. Typically, a programmer creates a series of gradually improving logic programs for a particular problem when optimizing program length and execution time on a particular solver. This leads the programmer to a meta-level problem of ensuring that the programs are equivalent, i.e., they give rise to the same answer sets. To ease answer set programming at methodological level, we propose a translation-based method for verifying the equivalence of logic programs. The basic idea is to translate logic programs P and Q under consideration into a single logic program EQT(P,Q) whose answer sets (if such exist) yield counter-examples to the equivalence of P and Q. The method is developed here in a slightly more general setting by taking the visibility of atoms properly into account when comparing answer sets. The translation-based approach presented in the paper has been implemented as a translator called lpeq that enables the verification of weak equivalence within the smodels system using the same search engine as for the search of models. Our experiments with lpeq and smodels suggest that establishing the equivalence of logic programs in this way is in certain cases much faster than naive cross-checking of answer sets.