 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTag and correct: high precision post-editing approach to correction of speech recognition errors
Jun 11, 2024



This paper presents a new approach to the problem of correcting speech recognition errors by means of post-editing. It consists of using a neural sequence tagger that learns how to correct an ASR (Automatic Speech Recognition) hypothesis word by word and a corrector module that applies corrections returned by the tagger. The proposed solution is applicable to any ASR system, regardless of its architecture, and provides high-precision control over errors being corrected. This is especially crucial in production environments, where avoiding the introduction of new mistakes by the error correction model may be more important than the net gain in overall results. The results show that the performance of the proposed error correction models is comparable with previous approaches while requiring much smaller resources to train, which makes it suitable for industrial applications, where both inference latency and training times are critical factors that limit the use of other techniques.
* 5 pages, 3 figures, Published in Proceedings of the 17th Conference on Computer Science and Intelligence Systems (FedCSIS 2022)
Back Transcription as a Method for Evaluating Robustness of Natural Language Understanding Models to Speech Recognition Errors
Oct 25, 2023In a spoken dialogue system, an NLU model is preceded by a speech recognition system that can deteriorate the performance of natural language understanding. This paper proposes a method for investigating the impact of speech recognition errors on the performance of natural language understanding models. The proposed method combines the back transcription procedure with a fine-grained technique for categorizing the errors that affect the performance of NLU models. The method relies on the usage of synthesized speech for NLU evaluation. We show that the use of synthesized speech in place of audio recording does not change the outcomes of the presented technique in a significant way.
Open Challenge for Correcting Errors of Speech Recognition Systems
Jan 09, 2020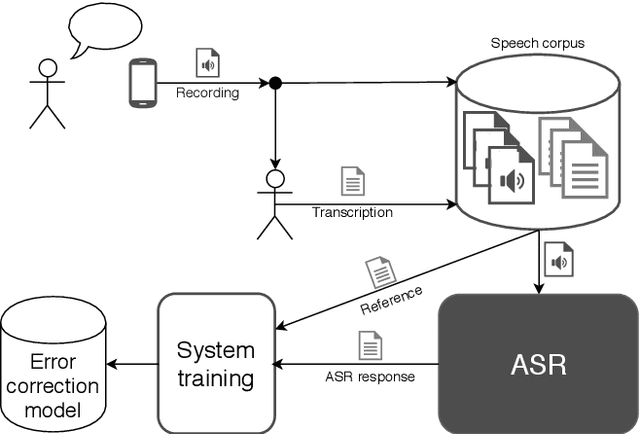
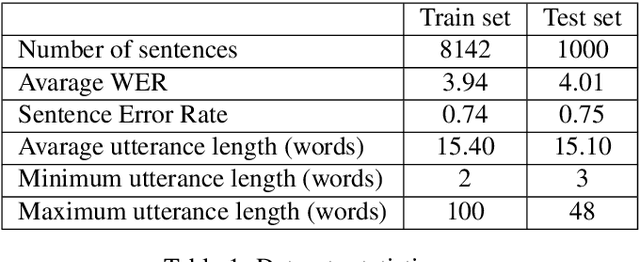
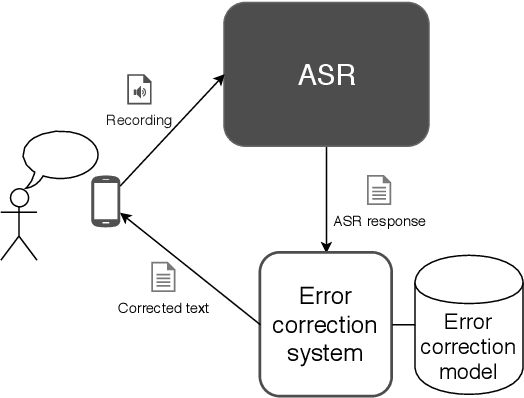
The paper announces the new long-term challenge for improving the performance of automatic speech recognition systems. The goal of the challenge is to investigate methods of correcting the recognition results on the basis of previously made errors by the speech processing system. The dataset prepared for the task is described and evaluation criteria are presented.