 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRVPO: Risk-Sensitive Alignment via Variance Regularization
May 07, 2026Current critic-less RLHF methods aggregate multi-objective rewards via an arithmetic mean, leaving them vulnerable to constraint neglect: high-magnitude success in one objective can numerically offset critical failures in others (e.g., safety or formatting), masking low-performing "bottleneck" rewards vital for reliable multi-objective alignment. We propose Reward-Variance Policy Optimization (RVPO), a risk-sensitive framework that penalizes inter-reward variance during advantage aggregation, shifting the objective from "maximize sum" to "maximize consistency." We show via Taylor expansion that a LogSumExp (SoftMin) operator effectively acts as a smooth variance penalty. We evaluate RVPO on rubric-based medical and scientific reasoning with up to 17 concurrent LLM-judged reward signals (Qwen2.5-3B/7B/14B) and on tool-calling with rule-based constraints (Qwen2.5-1.5B/3B). By preventing the model from neglecting difficult constraints to exploit easier objectives, RVPO improves overall scores on HealthBench (0.261 vs. 0.215 for GDPO at 14B, $p < 0.001$) and maintains competitive accuracy on GPQA-Diamond without the late-stage degradation observed in other multi-reward methods, demonstrating that variance regularization mitigates constraint neglect across model scales without sacrificing general capabilities.
Analysis of Wikipedia-based Corpora for Question Answering
Feb 05, 2018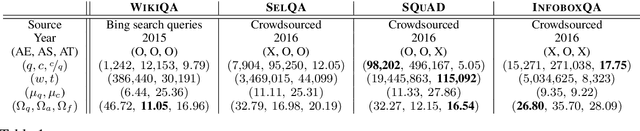
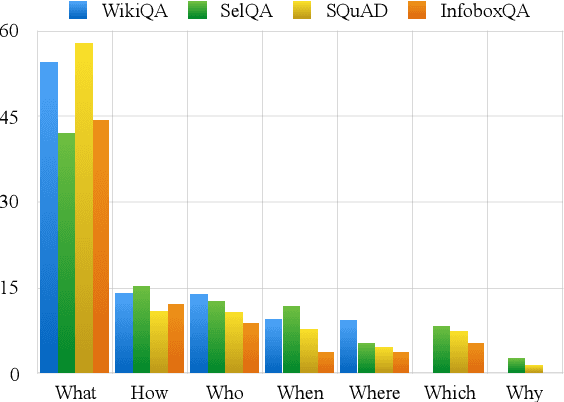

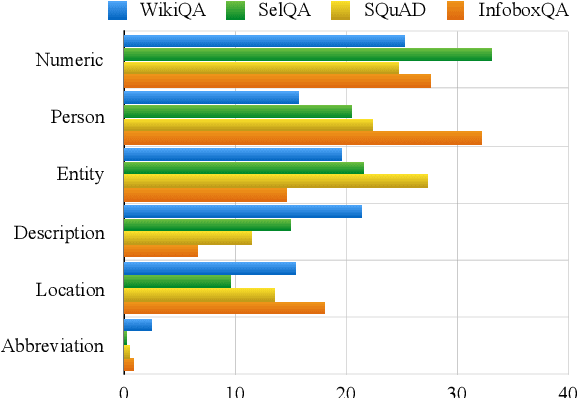
This paper gives comprehensive analyses of corpora based on Wikipedia for several tasks in question answering. Four recent corpora are collected,WikiQA, SelQA, SQuAD, and InfoQA, and first analyzed intrinsically by contextual similarities, question types, and answer categories. These corpora are then analyzed extrinsically by three question answering tasks, answer retrieval, selection, and triggering. An indexing-based method for the creation of a silver-standard dataset for answer retrieval using the entire Wikipedia is also presented. Our analysis shows the uniqueness of these corpora and suggests a better use of them for statistical question answering learning.
Cross-genre Document Retrieval: Matching between Conversational and Formal Writings
Jul 14, 2017



This paper challenges a cross-genre document retrieval task, where the queries are in formal writing and the target documents are in conversational writing. In this task, a query, is a sentence extracted from either a summary or a plot of an episode in a TV show, and the target document consists of transcripts from the corresponding episode. To establish a strong baseline, we employ the current state-of-the-art search engine to perform document retrieval on the dataset collected for this work. We then introduce a structure reranking approach to improve the initial ranking by utilizing syntactic and semantic structures generated by NLP tools. Our evaluation shows an improvement of more than 4% when the structure reranking is applied, which is very promising.
SelQA: A New Benchmark for Selection-based Question Answering
Oct 28, 2016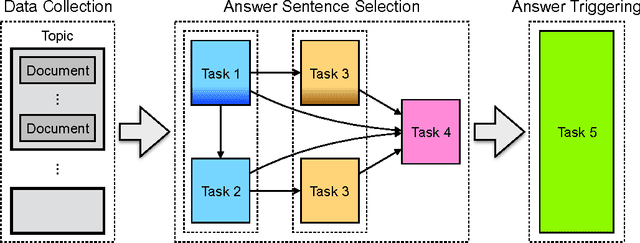
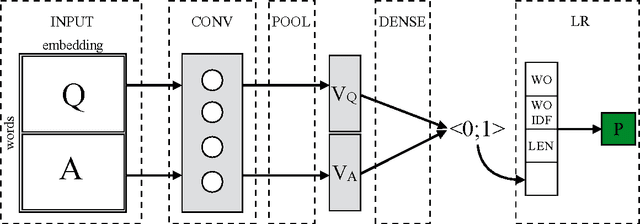

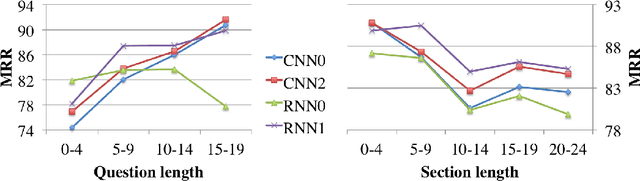
This paper presents a new selection-based question answering dataset, SelQA. The dataset consists of questions generated through crowdsourcing and sentence length answers that are drawn from the ten most prevalent topics in the English Wikipedia. We introduce a corpus annotation scheme that enhances the generation of large, diverse, and challenging datasets by explicitly aiming to reduce word co-occurrences between the question and answers. Our annotation scheme is composed of a series of crowdsourcing tasks with a view to more effectively utilize crowdsourcing in the creation of question answering datasets in various domains. Several systems are compared on the tasks of answer sentence selection and answer triggering, providing strong baseline results for future work to improve upon.
Multi-Field Structural Decomposition for Question Answering
Apr 04, 2016


This paper presents a precursory yet novel approach to the question answering task using structural decomposition. Our system first generates linguistic structures such as syntactic and semantic trees from text, decomposes them into multiple fields, then indexes the terms in each field. For each question, it decomposes the question into multiple fields, measures the relevance score of each field to the indexed ones, then ranks all documents by their relevance scores and weights associated with the fields, where the weights are learned through statistical modeling. Our final model gives an absolute improvement of over 40% to the baseline approach using simple search for detecting documents containing answers.