 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretable Machine Vision Approach to Human Activity Recognition using Photoplethysmograph Sensor Data
Dec 03, 2018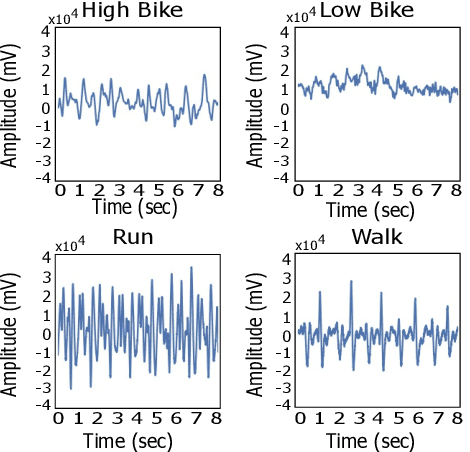
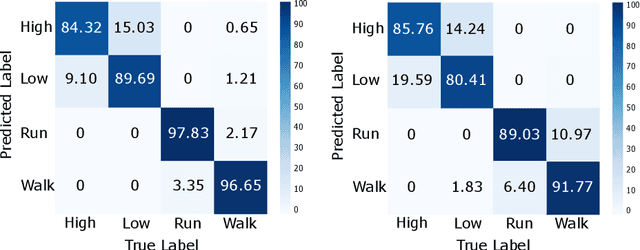
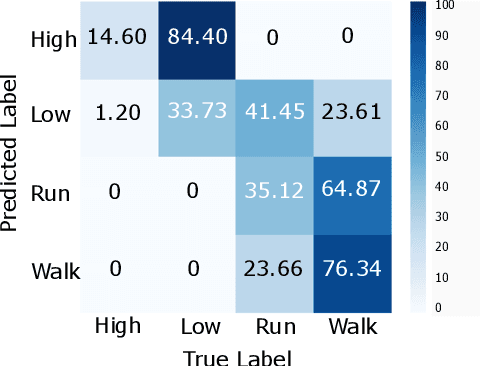
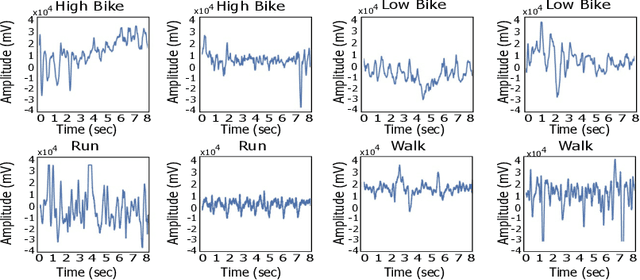
The current gold standard for human activity recognition (HAR) is based on the use of cameras. However, the poor scalability of camera systems renders them impractical in pursuit of the goal of wider adoption of HAR in mobile computing contexts. Consequently, researchers instead rely on wearable sensors and in particular inertial sensors. A particularly prevalent wearable is the smart watch which due to its integrated inertial and optical sensing capabilities holds great potential for realising better HAR in a non-obtrusive way. This paper seeks to simplify the wearable approach to HAR through determining if the wrist-mounted optical sensor alone typically found in a smartwatch or similar device can be used as a useful source of data for activity recognition. The approach has the potential to eliminate the need for the inertial sensing element which would in turn reduce the cost of and complexity of smartwatches and fitness trackers. This could potentially commoditise the hardware requirements for HAR while retaining the functionality of both heart rate monitoring and activity capture all from a single optical sensor. Our approach relies on the adoption of machine vision for activity recognition based on suitably scaled plots of the optical signals. We take this approach so as to produce classifications that are easily explainable and interpretable by non-technical users. More specifically, images of photoplethysmography signal time series are used to retrain the penultimate layer of a convolutional neural network which has initially been trained on the ImageNet database. We then use the 2048 dimensional features from the penultimate layer as input to a support vector machine. Results from the experiment yielded an average classification accuracy of 92.3%. This result outperforms that of an optical and inertial sensor combined (78%) and illustrates the capability of HAR systems using...
Use of Neural Signals to Evaluate the Quality of Generative Adversarial Network Performance in Facial Image Generation
Nov 10, 2018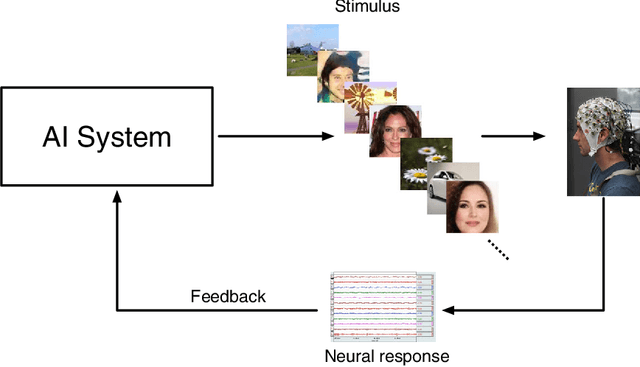
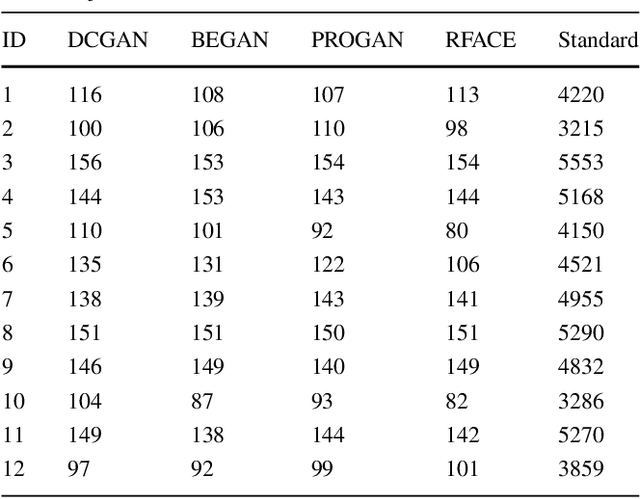
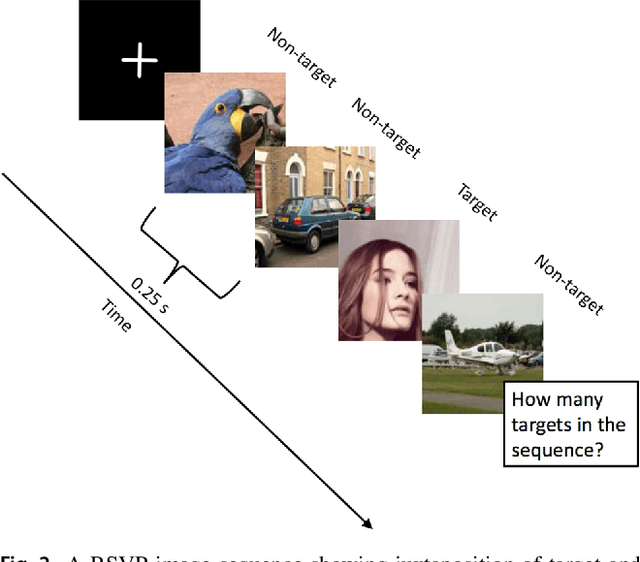
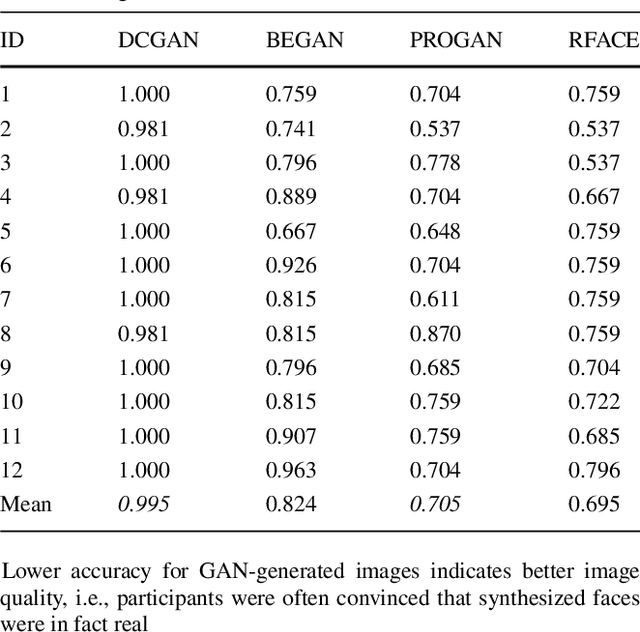
There is a growing interest in using Generative Adversarial Networks (GANs) to produce image content that is indistinguishable from a real image as judged by a typical person. A number of GAN variants for this purpose have been proposed, however, evaluating GANs is inherently difficult because current methods of measuring the quality of the output do not always mirror what is actually perceived by a human. We propose a novel approach that deploys a brain-computer interface to generate a neural score that closely mirrors the behavioral ground truth measured from participants discerning real from synthetic images. In this paper, we first compare the three most widely used metrics in the literature for evaluating GANs in terms of visual quality compared to human judgments. Second, we propose and demonstrate a novel approach using neural signals and rapid serial visual presentation (RSVP) that directly measures a human perceptual response to facial production quality independent of a behavioral response measurement. Finally we show that our neural score is more consistent with human judgment compared to the conventional metrics we evaluated. We conclude that neural signals have potential application for high quality, rapid evaluation of GANs in the context of visual image synthesis.