 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREALab: An Embedded Perspective on Tampering
Nov 17, 2020

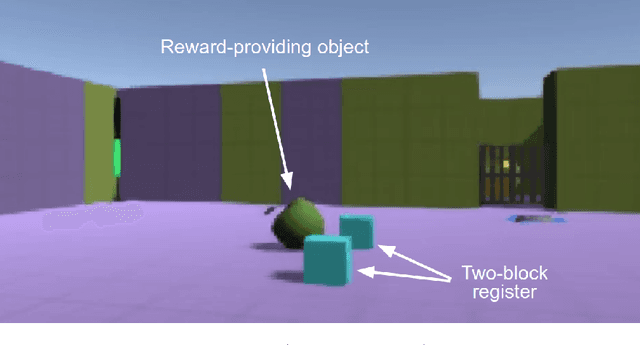

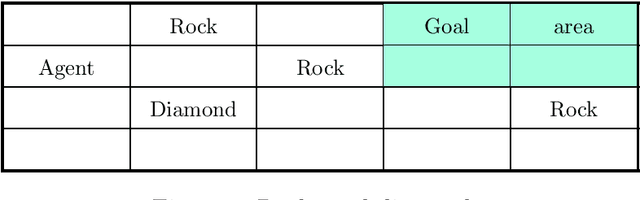
This paper describes REALab, a platform for embedded agency research in reinforcement learning (RL). REALab is designed to model the structure of tampering problems that may arise in real-world deployments of RL. Standard Markov Decision Process (MDP) formulations of RL and simulated environments mirroring the MDP structure assume secure access to feedback (e.g., rewards). This may be unrealistic in settings where agents are embedded and can corrupt the processes producing feedback (e.g., human supervisors, or an implemented reward function). We describe an alternative Corrupt Feedback MDP formulation and the REALab environment platform, which both avoid the secure feedback assumption. We hope the design of REALab provides a useful perspective on tampering problems, and that the platform may serve as a unit test for the presence of tampering incentives in RL agent designs.
The Incentives that Shape Behaviour
Jan 20, 2020

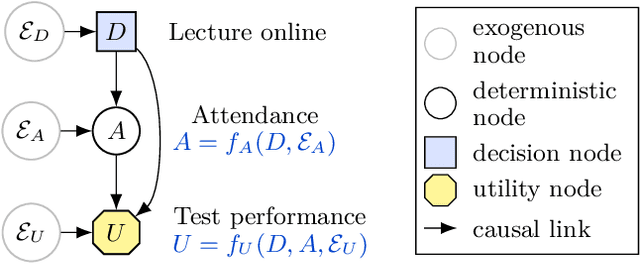
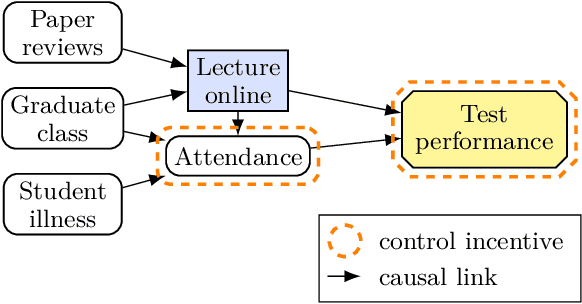
Which variables does an agent have an incentive to control with its decision, and which variables does it have an incentive to respond to? We formalise these incentives, and demonstrate unique graphical criteria for detecting them in any single decision causal influence diagram. To this end, we introduce structural causal influence models, a hybrid of the influence diagram and structural causal model frameworks. Finally, we illustrate how these incentives predict agent incentives in both fairness and AI safety applications.
Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective
Aug 20, 2019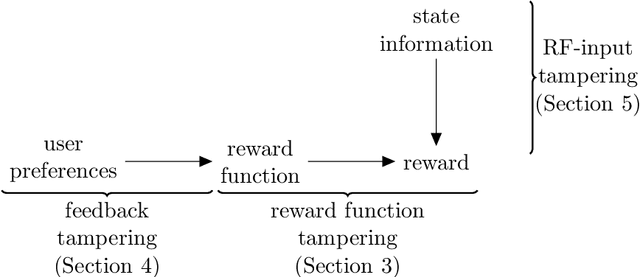
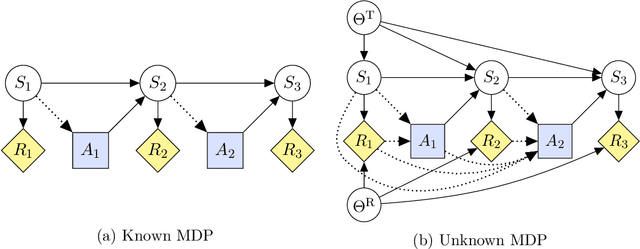
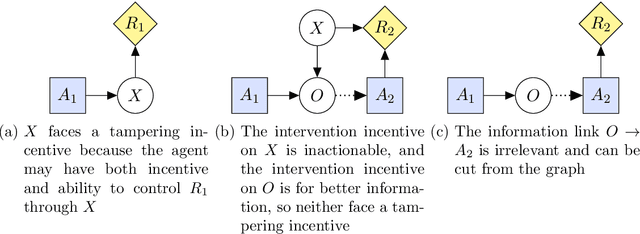
Can an arbitrarily intelligent reinforcement learning agent be kept under control by a human user? Or do agents with sufficient intelligence inevitably find ways to shortcut their reward signal? This question impacts how far reinforcement learning can be scaled, and whether alternative paradigms must be developed in order to build safe artificial general intelligence. In this paper, we use an intuitive yet precise graphical model called causal influence diagrams to formalize reward tampering problems. We also describe a number of modifications to the reinforcement learning objective that prevent incentives for reward tampering. We verify the solutions using recently developed graphical criteria for inferring agent incentives from causal influence diagrams. Along the way, we also compare corrigibility and self-preservation properties of the various solutions, and discuss how they can be combined into a single agent without reward tampering incentives.
Modeling AGI Safety Frameworks with Causal Influence Diagrams
Jun 20, 2019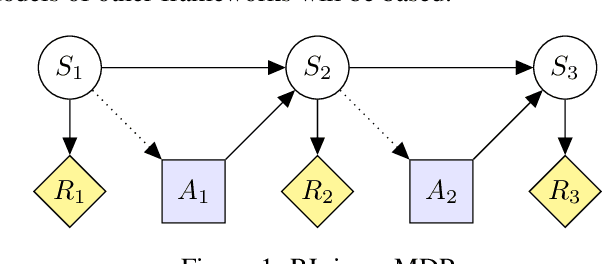
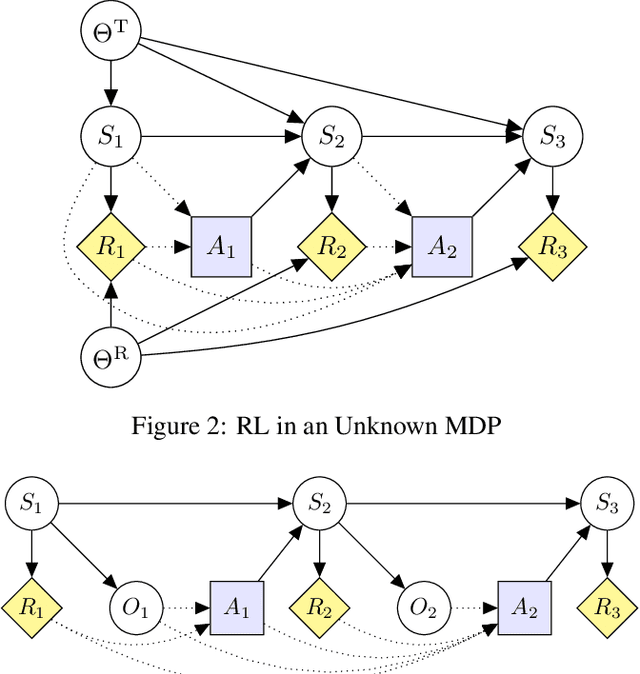
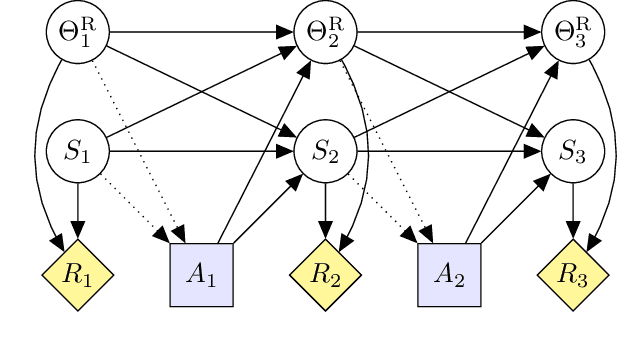
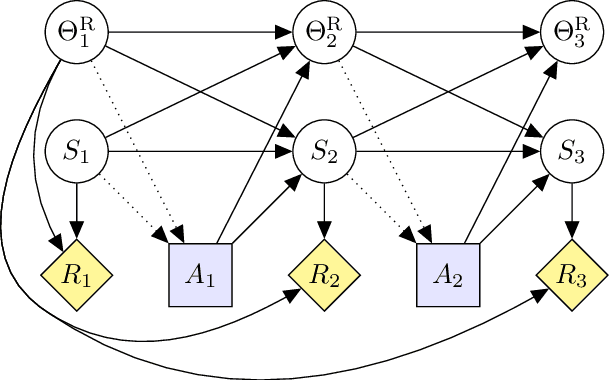
Proposals for safe AGI systems are typically made at the level of frameworks, specifying how the components of the proposed system should be trained and interact with each other. In this paper, we model and compare the most promising AGI safety frameworks using causal influence diagrams. The diagrams show the optimization objective and causal assumptions of the framework. The unified representation permits easy comparison of frameworks and their assumptions. We hope that the diagrams will serve as an accessible and visual introduction to the main AGI safety frameworks.
Understanding Agent Incentives using Causal Influence Diagrams. Part I: Single Action Settings
Mar 12, 2019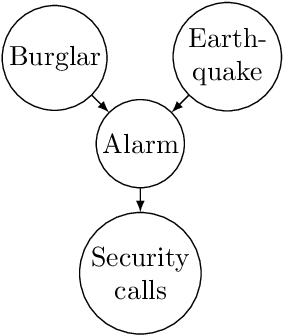

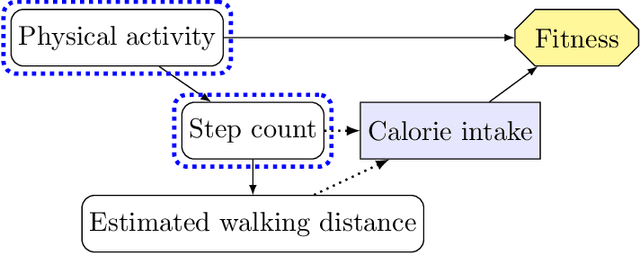
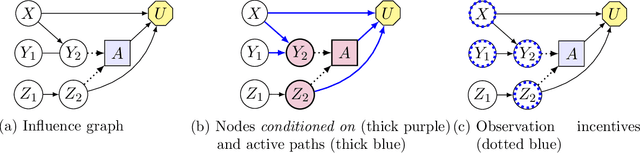
Agents are systems that optimize an objective function in an environment. Together, the goal and the environment induce secondary objectives, incentives. Modeling the agent-environment interaction in graphical models called influence diagrams, we can answer two fundamental questions about an agent's incentives directly from the graph: (1) which nodes is the agent incentivized to observe, and (2) which nodes is the agent incentivized to influence? The answers tell us which information and influence points need extra protection. For example, we may want a classifier for job applications to not use the ethnicity of the candidate, and a reinforcement learning agent not to take direct control of its reward mechanism. Different algorithms and training paradigms can lead to different influence diagrams, so our method can be used to identify algorithms with problematic incentives and help in designing algorithms with better incentives.
Scalable agent alignment via reward modeling: a research direction
Nov 19, 2018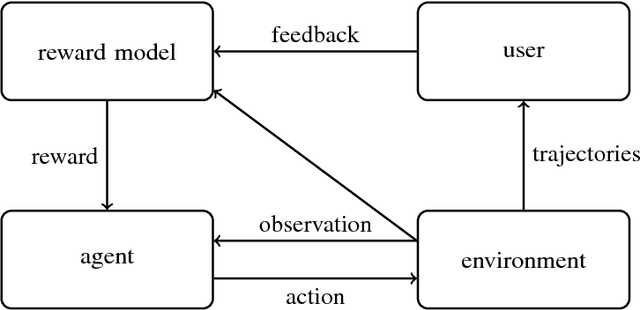
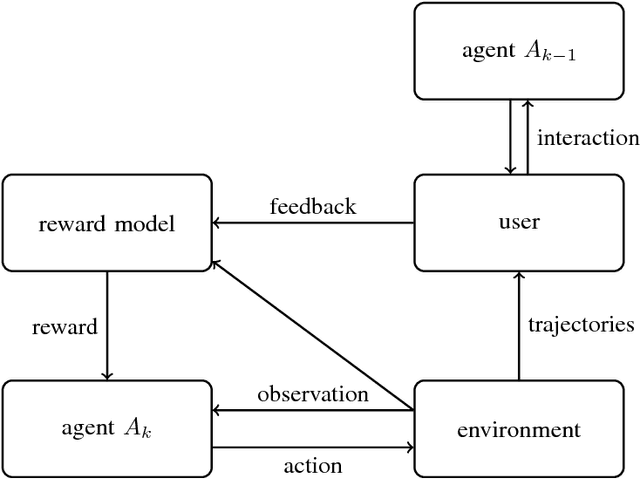

One obstacle to applying reinforcement learning algorithms to real-world problems is the lack of suitable reward functions. Designing such reward functions is difficult in part because the user only has an implicit understanding of the task objective. This gives rise to the agent alignment problem: how do we create agents that behave in accordance with the user's intentions? We outline a high-level research direction to solve the agent alignment problem centered around reward modeling: learning a reward function from interaction with the user and optimizing the learned reward function with reinforcement learning. We discuss the key challenges we expect to face when scaling reward modeling to complex and general domains, concrete approaches to mitigate these challenges, and ways to establish trust in the resulting agents.
AGI Safety Literature Review
May 21, 2018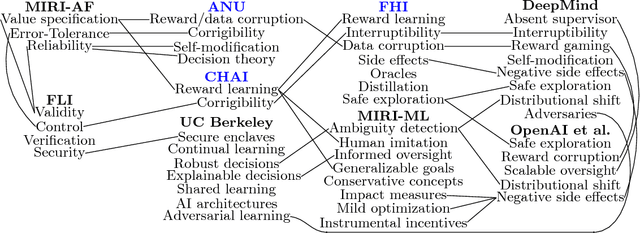
The development of Artificial General Intelligence (AGI) promises to be a major event. Along with its many potential benefits, it also raises serious safety concerns (Bostrom, 2014). The intention of this paper is to provide an easily accessible and up-to-date collection of references for the emerging field of AGI safety. A significant number of safety problems for AGI have been identified. We list these, and survey recent research on solving them. We also cover works on how best to think of AGI from the limited knowledge we have today, predictions for when AGI will first be created, and what will happen after its creation. Finally, we review the current public policy on AGI.
A Topological Approach to Meta-heuristics: Analytical Results on the BFS vs. DFS Algorithm Selection Problem
Apr 12, 2018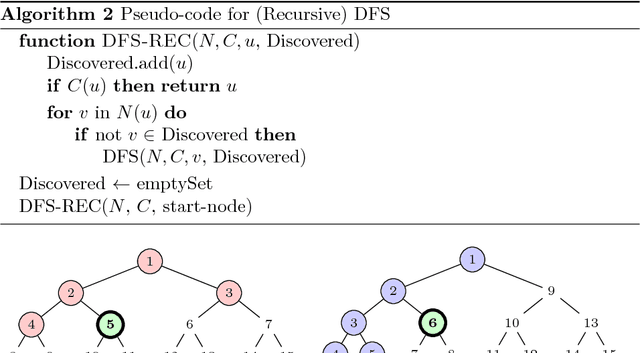
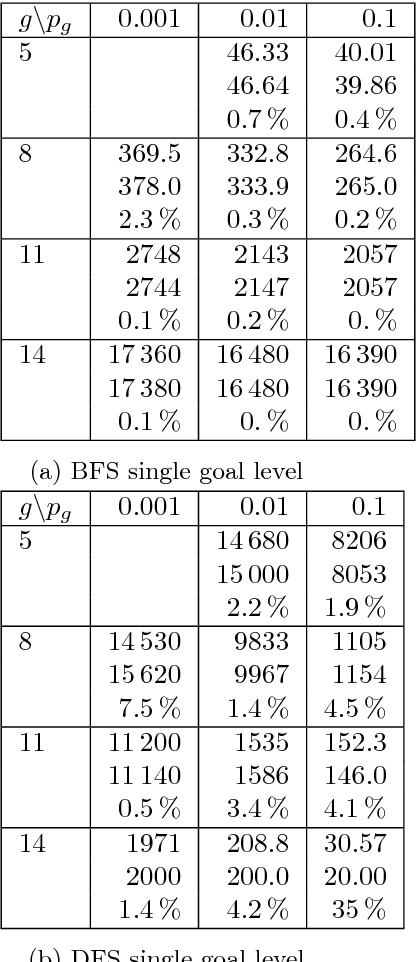
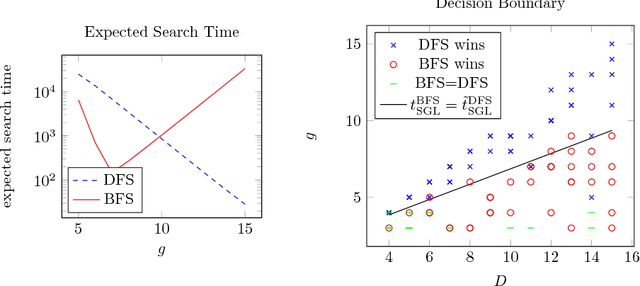
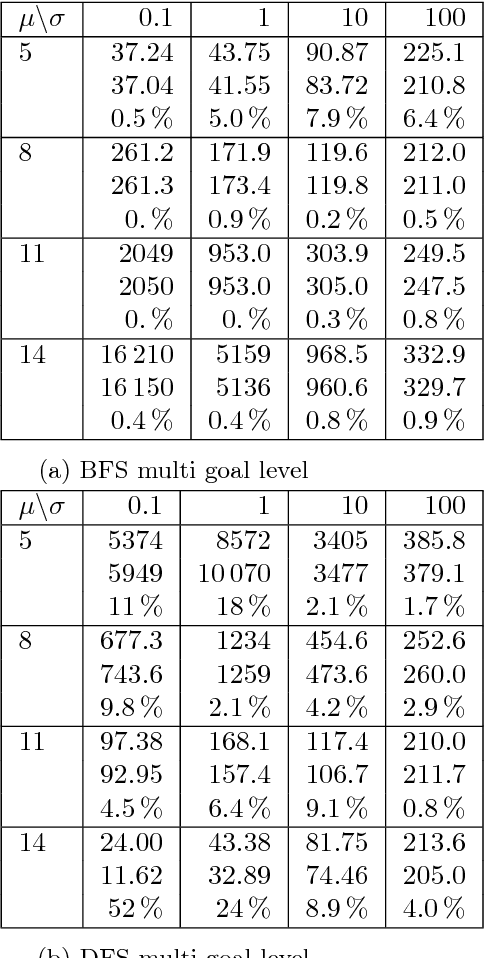
Search is a central problem in artificial intelligence, and breadth-first search (BFS) and depth-first search (DFS) are the two most fundamental ways to search. In this paper we derive estimates for average BFS and DFS runtime. The average runtime estimates can be used to allocate resources or judge the hardness of a problem. They can also be used for selecting the best graph representation, and for selecting the faster algorithm out of BFS and DFS. They may also form the basis for an analysis of more advanced search methods. The paper treats both tree search and graph search. For tree search, we employ a probabilistic model of goal distribution; for graph search, the analysis depends on an additional statistic of path redundancy and average branching factor. As an application, we use the results to predict BFS and DFS runtime on two concrete grammar problems and on the N-puzzle. Experimental verification shows that our analytical approximations come close to empirical reality.
AI Safety Gridworlds
Nov 28, 2017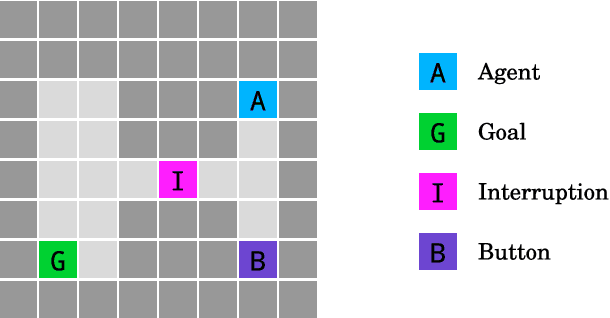
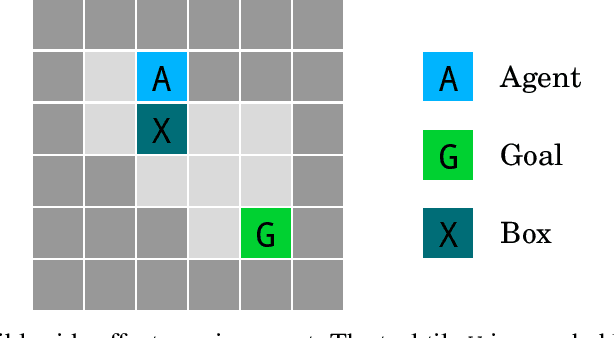
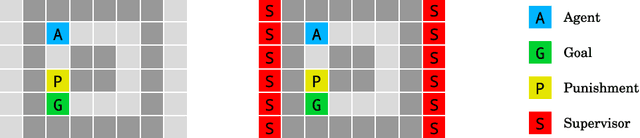
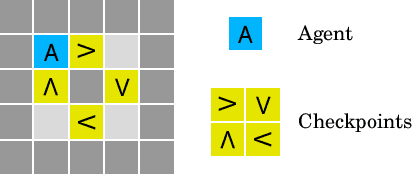
We present a suite of reinforcement learning environments illustrating various safety properties of intelligent agents. These problems include safe interruptibility, avoiding side effects, absent supervisor, reward gaming, safe exploration, as well as robustness to self-modification, distributional shift, and adversaries. To measure compliance with the intended safe behavior, we equip each environment with a performance function that is hidden from the agent. This allows us to categorize AI safety problems into robustness and specification problems, depending on whether the performance function corresponds to the observed reward function. We evaluate A2C and Rainbow, two recent deep reinforcement learning agents, on our environments and show that they are not able to solve them satisfactorily.
Reinforcement Learning with a Corrupted Reward Channel
Aug 19, 2017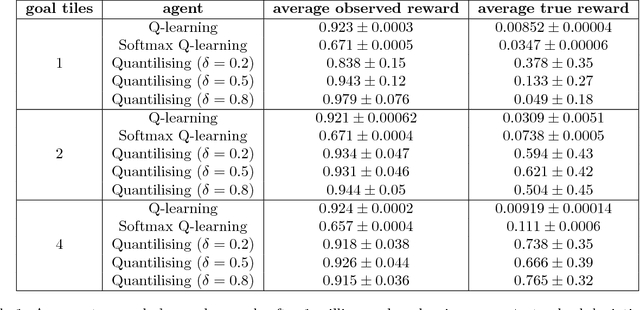
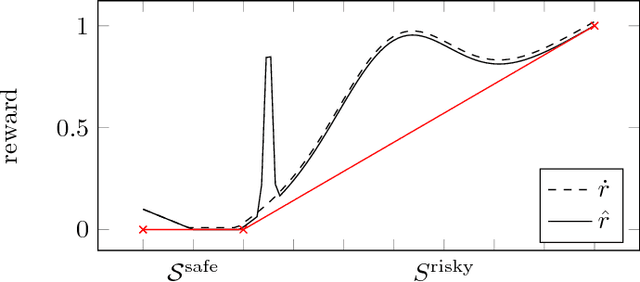

No real-world reward function is perfect. Sensory errors and software bugs may result in RL agents observing higher (or lower) rewards than they should. For example, a reinforcement learning agent may prefer states where a sensory error gives it the maximum reward, but where the true reward is actually small. We formalise this problem as a generalised Markov Decision Problem called Corrupt Reward MDP. Traditional RL methods fare poorly in CRMDPs, even under strong simplifying assumptions and when trying to compensate for the possibly corrupt rewards. Two ways around the problem are investigated. First, by giving the agent richer data, such as in inverse reinforcement learning and semi-supervised reinforcement learning, reward corruption stemming from systematic sensory errors may sometimes be completely managed. Second, by using randomisation to blunt the agent's optimisation, reward corruption can be partially managed under some assumptions.