 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair assignment of indivisible objects under ordinal preferences
Jun 17, 2015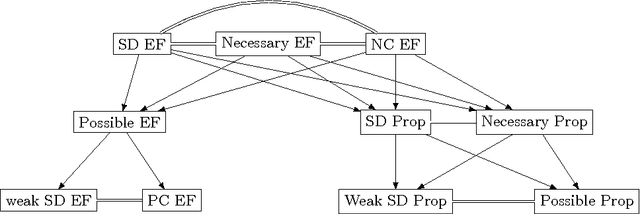

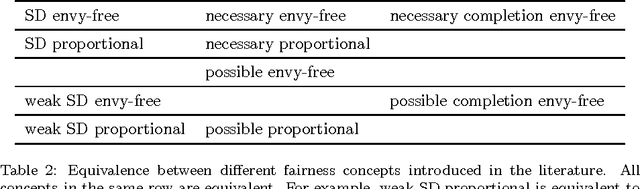
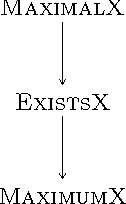
We consider the discrete assignment problem in which agents express ordinal preferences over objects and these objects are allocated to the agents in a fair manner. We use the stochastic dominance relation between fractional or randomized allocations to systematically define varying notions of proportionality and envy-freeness for discrete assignments. The computational complexity of checking whether a fair assignment exists is studied for these fairness notions. We also characterize the conditions under which a fair assignment is guaranteed to exist. For a number of fairness concepts, polynomial-time algorithms are presented to check whether a fair assignment exists. Our algorithmic results also extend to the case of unequal entitlements of agents. Our NP-hardness result, which holds for several variants of envy-freeness, answers an open question posed by Bouveret, Endriss, and Lang (ECAI 2010). We also propose fairness concepts that always suggest a non-empty set of assignments with meaningful fairness properties. Among these concepts, optimal proportionality and optimal weak proportionality appear to be desirable fairness concepts.
Online Fair Division: analysing a Food Bank problem
Feb 28, 2015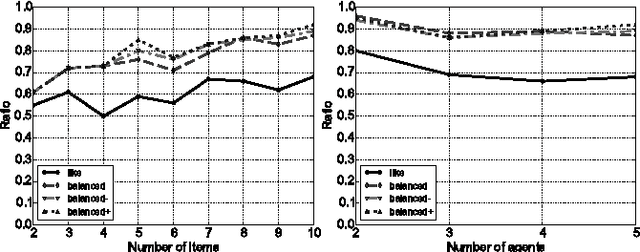

We study an online model of fair division designed to capture features of a real world charity problem. We consider two simple mechanisms for this model in which agents simply declare what items they like. We analyse several axiomatic properties of these mechanisms like strategy-proofness and envy-freeness. Finally, we perform a competitive analysis and compute the price of anarchy.
Possible and Necessary Allocations via Sequential Mechanisms
Dec 06, 2014

A simple mechanism for allocating indivisible resources is sequential allocation in which agents take turns to pick items. We focus on possible and necessary allocation problems, checking whether allocations of a given form occur in some or all mechanisms for several commonly used classes of sequential allocation mechanisms. In particular, we consider whether a given agent receives a given item, a set of items, or a subset of items for five natural classes of sequential allocation mechanisms: balanced, recursively balanced, balanced alternating, strictly alternating and all policies. We identify characterizations of allocations produced balanced, recursively balanced, balanced alternating policies and strictly alternating policies respectively, which extend the well-known characterization by Brams and King [2005] for policies without restrictions. In addition, we examine the computational complexity of possible and necessary allocation problems for these classes.
A Study of Proxies for Shapley Allocations of Transport Costs
Aug 21, 2014
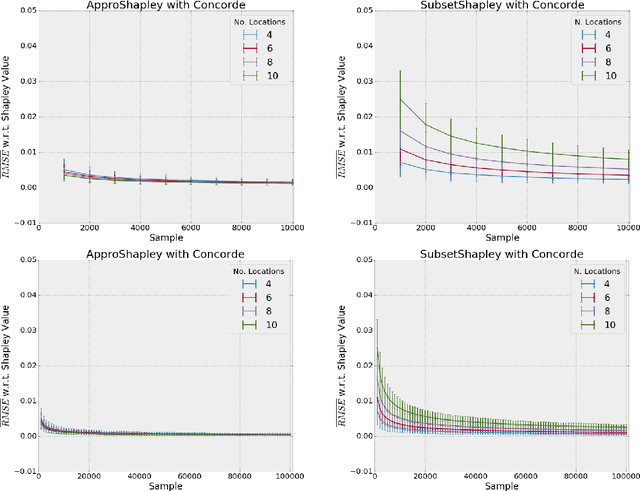
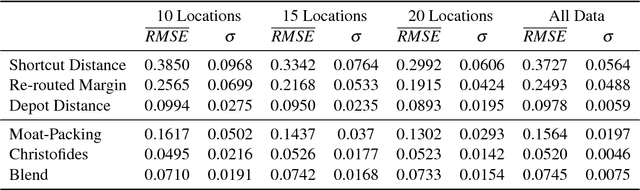
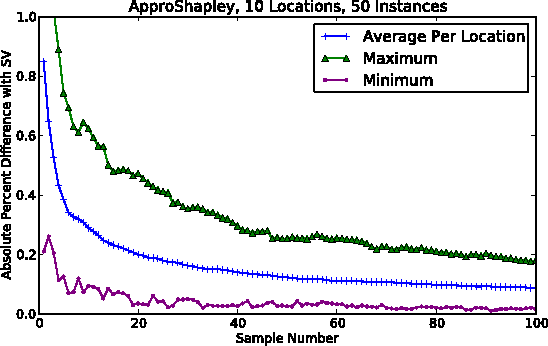
We propose and evaluate a number of solutions to the problem of calculating the cost to serve each location in a single-vehicle transport setting. Such cost to serve analysis has application both strategically and operationally in transportation. The problem is formally given by the traveling salesperson game (TSG), a cooperative total utility game in which agents correspond to locations in a traveling salesperson problem (TSP). The cost to serve a location is an allocated portion of the cost of an optimal tour. The Shapley value is one of the most important normative division schemes in cooperative games, giving a principled and fair allocation both for the TSG and more generally. We consider a number of direct and sampling-based procedures for calculating the Shapley value, and present the first proof that approximating the Shapley value of the TSG within a constant factor is NP-hard. Treating the Shapley value as an ideal baseline allocation, we then develop six proxies for that value which are relatively easy to compute. We perform an experimental evaluation using Synthetic Euclidean games as well as games derived from real-world tours calculated for fast-moving consumer goods scenarios. Our experiments show that several computationally tractable allocation techniques correspond to good proxies for the Shapley value.
Allocation in Practice
Jul 16, 2014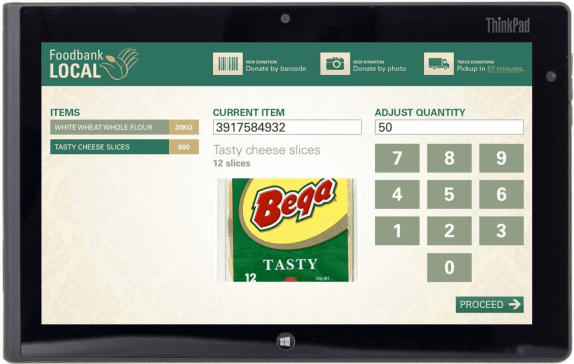
How do we allocate scarcere sources? How do we fairly allocate costs? These are two pressing challenges facing society today. I discuss two recent projects at NICTA concerning resource and cost allocation. In the first, we have been working with FoodBank Local, a social startup working in collaboration with food bank charities around the world to optimise the logistics of collecting and distributing donated food. Before we can distribute this food, we must decide how to allocate it to different charities and food kitchens. This gives rise to a fair division problem with several new dimensions, rarely considered in the literature. In the second, we have been looking at cost allocation within the distribution network of a large multinational company. This also has several new dimensions rarely considered in the literature.
Computational Aspects of Multi-Winner Approval Voting
Jul 11, 2014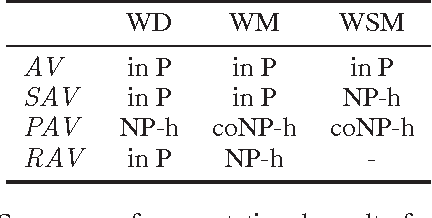
We study computational aspects of three prominent voting rules that use approval ballots to elect multiple winners. These rules are satisfaction approval voting, proportional approval voting, and reweighted approval voting. We first show that computing the winner for proportional approval voting is NP-hard, closing a long standing open problem. As none of the rules are strategyproof, even for dichotomous preferences, we study various strategic aspects of the rules. In particular, we examine the computational complexity of computing a best response for both a single agent and a group of agents. In many settings, we show that it is NP-hard for an agent or agents to compute how best to vote given a fixed set of approval ballots from the other agents.
How Hard Is It to Control an Election by Breaking Ties?
May 29, 2014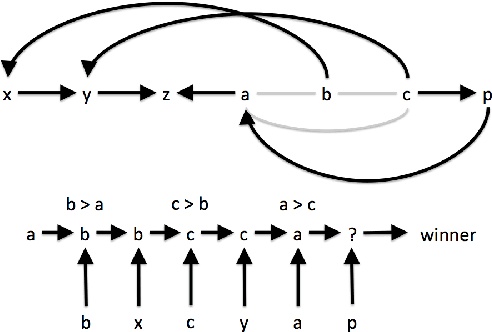
We study the computational complexity of controlling the result of an election by breaking ties strategically. This problem is equivalent to the problem of deciding the winner of an election under parallel universes tie-breaking. When the chair of the election is only asked to break ties to choose between one of the co-winners, the problem is trivially easy. However, in multi-round elections, we prove that it can be NP-hard for the chair to compute how to break ties to ensure a given result. Additionally, we show that the form of the tie-breaking function can increase the opportunities for control. Indeed, we prove that it can be NP-hard to control an election by breaking ties even with a two-stage voting rule.
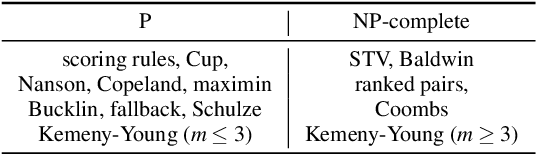
The Computational Impact of Partial Votes on Strategic Voting
May 28, 2014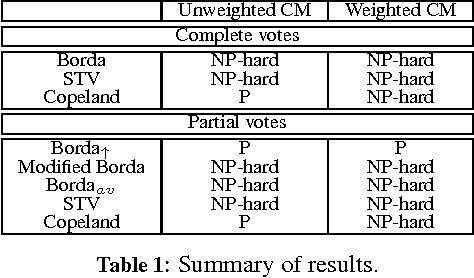
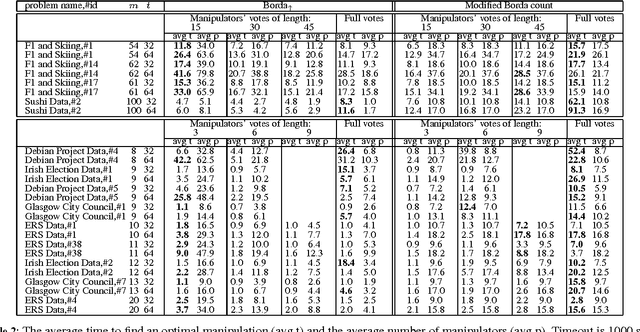
In many real world elections, agents are not required to rank all candidates. We study three of the most common methods used to modify voting rules to deal with such partial votes. These methods modify scoring rules (like the Borda count), elimination style rules (like single transferable vote) and rules based on the tournament graph (like Copeland) respectively. We argue that with an elimination style voting rule like single transferable vote, partial voting does not change the situations where strategic voting is possible. However, with scoring rules and rules based on the tournament graph, partial voting can increase the situations where strategic voting is possible. As a consequence, the computational complexity of computing a strategic vote can change. For example, with Borda count, the complexity of computing a strategic vote can decrease or stay the same depending on how we score partial votes.
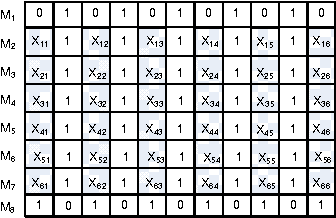
The PeerRank Method for Peer Assessment
May 28, 2014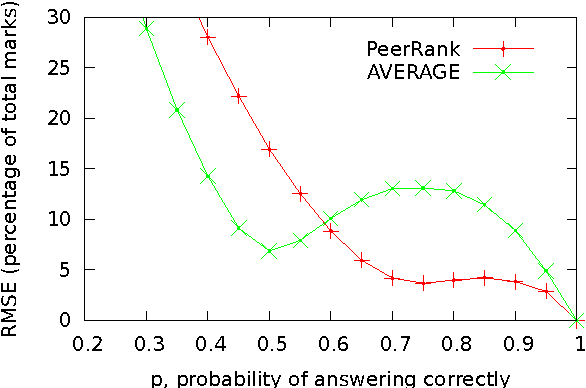
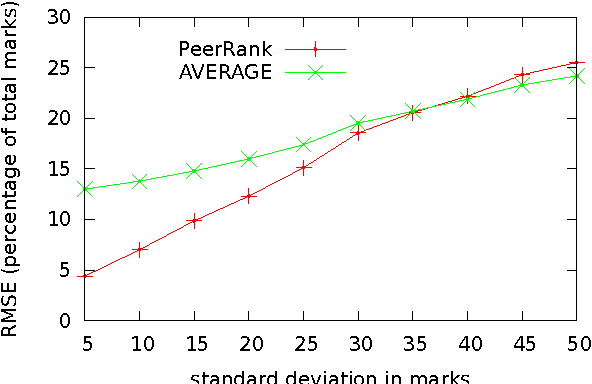
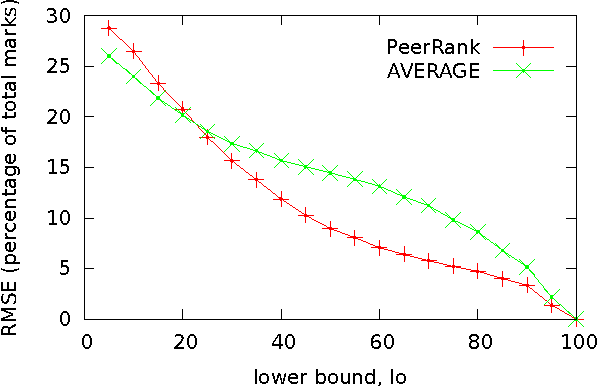
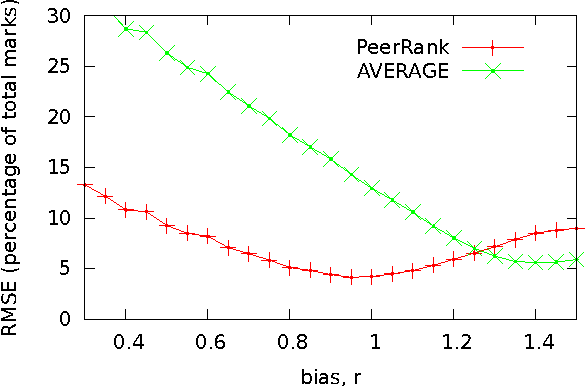
We propose the PeerRank method for peer assessment. This constructs a grade for an agent based on the grades proposed by the agents evaluating the agent. Since the grade of an agent is a measure of their ability to grade correctly, the PeerRank method weights grades by the grades of the grading agent. The PeerRank method also provides an incentive for agents to grade correctly. As the grades of an agent depend on the grades of the grading agents, and as these grades themselves depend on the grades of other agents, we define the PeerRank method by a fixed point equation similar to the PageRank method for ranking web-pages. We identify some formal properties of the PeerRank method (for example, it satisfies axioms of unanimity, no dummy, no discrimination and symmetry), discuss some examples, compare with related work and evaluate the performance on some synthetic data. Our results show considerable promise, reducing the error in grade predictions by a factor of 2 or more in many cases over the natural baseline of averaging peer grades.
Breaking Symmetry with Different Orderings
Jun 21, 2013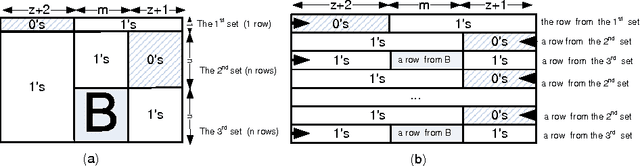
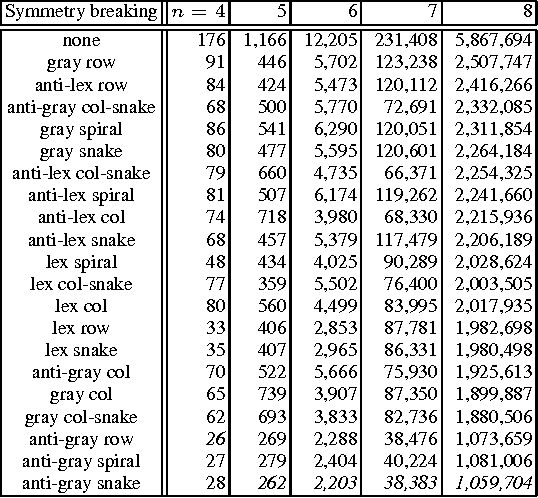
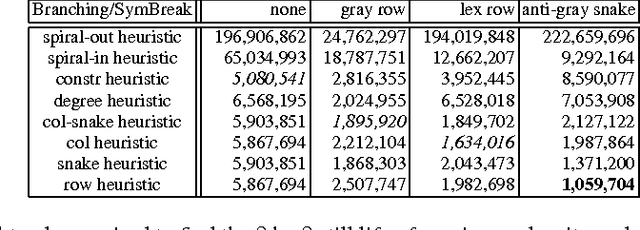
We can break symmetry by eliminating solutions within each symmetry class. For instance, the Lex-Leader method eliminates all but the smallest solution in the lexicographical ordering. Unfortunately, the Lex-Leader method is intractable in general. We prove that, under modest assumptions, we cannot reduce the worst case complexity of breaking symmetry by using other orderings on solutions. We also prove that a common type of symmetry, where rows and columns in a matrix of decision variables are interchangeable, is intractable to break when we use two promising alternatives to the lexicographical ordering: the Gray code ordering (which uses a different ordering on solutions), and the Snake-Lex ordering (which is a variant of the lexicographical ordering that re-orders the variables). Nevertheless, we show experimentally that using other orderings like the Gray code to break symmetry can be beneficial in practice as they may better align with the objective function and branching heuristic.