 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Frame Forecast
Apr 12, 2021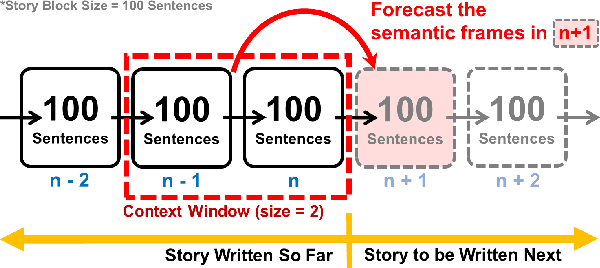
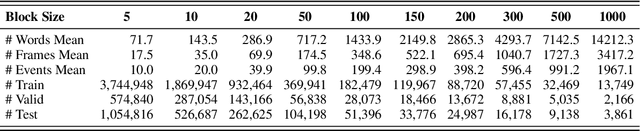
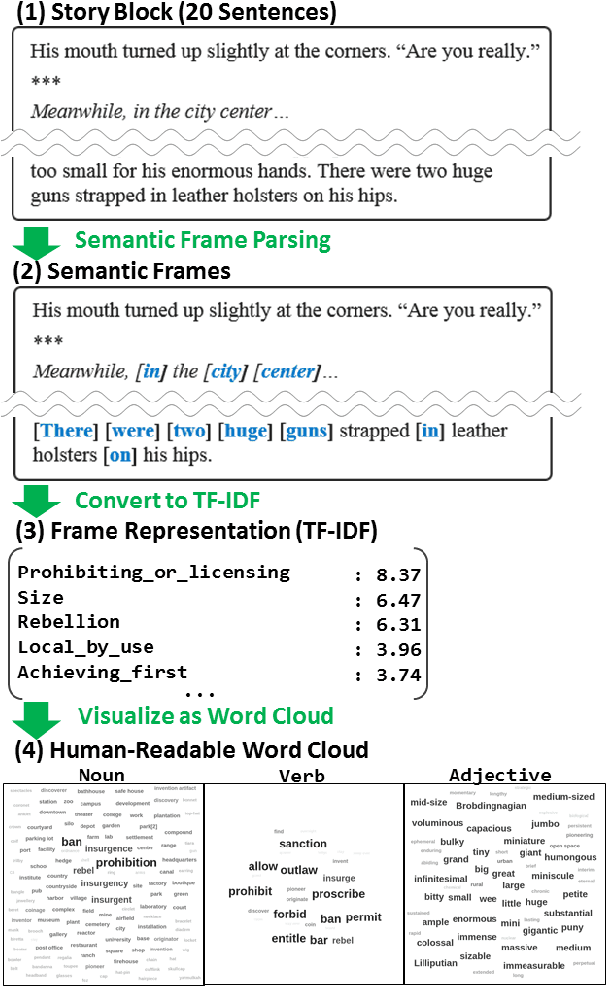
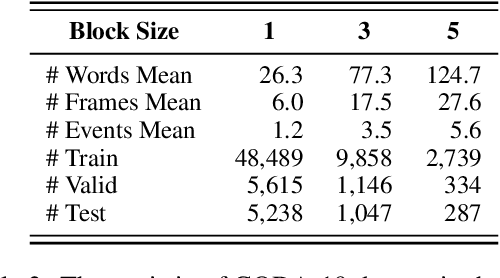
This paper introduces semantic frame forecast, a task that predicts the semantic frames that will occur in the next 10, 100, or even 1,000 sentences in a running story. Prior work focused on predicting the immediate future of a story, such as one to a few sentences ahead. However, when novelists write long stories, generating a few sentences is not enough to help them gain high-level insight to develop the follow-up story. In this paper, we formulate a long story as a sequence of "story blocks," where each block contains a fixed number of sentences (e.g., 10, 100, or 200). This formulation allows us to predict the follow-up story arc beyond the scope of a few sentences. We represent a story block using the term frequencies (TF) of semantic frames in it, normalized by each frame's inverse document frequency (IDF). We conduct semantic frame forecast experiments on 4,794 books from the Bookcorpus and 7,962 scientific abstracts from CODA-19, with block sizes ranging from 5 to 1,000 sentences. The results show that automated models can forecast the follow-up story blocks better than the random, prior, and replay baselines, indicating the task's feasibility. We also learn that the models using the frame representation as features outperform all the existing approaches when the block size is over 150 sentences. The human evaluation also shows that the proposed frame representation, when visualized as word clouds, is comprehensible, representative, and specific to humans. Our code is available at https://github.com/appleternity/FrameForecasting.
Explaining the Road Not Taken
Mar 30, 2021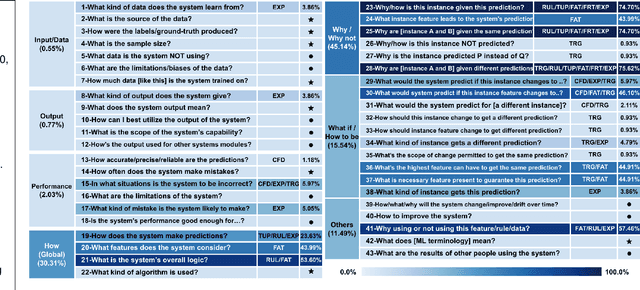
It is unclear if existing interpretations of deep neural network models respond effectively to the needs of users. This paper summarizes the common forms of explanations (such as feature attribution, decision rules, or probes) used in over 200 recent papers about natural language processing (NLP), and compares them against user questions collected in the XAI Question Bank. We found that although users are interested in explanations for the road not taken -- namely, why the model chose one result and not a well-defined, seemly similar legitimate counterpart -- most model interpretations cannot answer these questions.
Assessing the Helpfulness of Learning Materials with Inference-Based Learner-Like Agent
Oct 05, 2020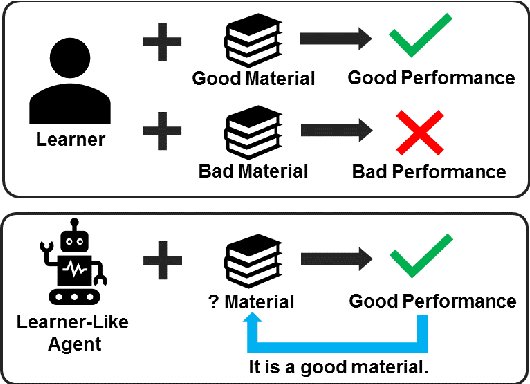
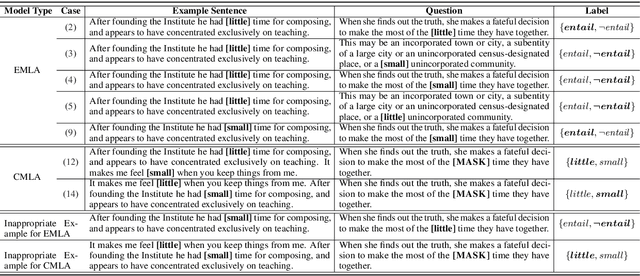
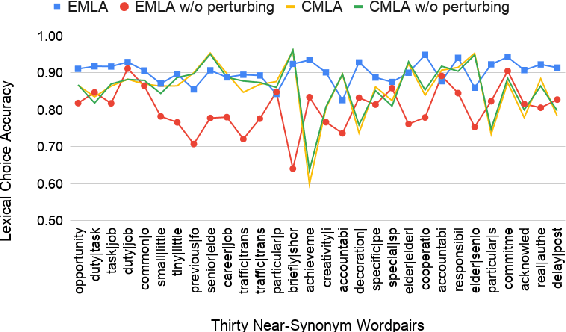

Many English-as-a-second language learners have trouble using near-synonym words (e.g., small vs.little; briefly vs.shortly) correctly, and often look for example sentences to learn how two nearly synonymous terms differ. Prior work uses hand-crafted scores to recommend sentences but has difficulty in adopting such scores to all the near-synonyms as near-synonyms differ in various ways. We notice that the helpfulness of the learning material would reflect on the learners' performance. Thus, we propose the inference-based learner-like agent to mimic learner behavior and identify good learning materials by examining the agent's performance. To enable the agent to behave like a learner, we leverage entailment modeling's capability of inferring answers from the provided materials. Experimental results show that the proposed agent is equipped with good learner-like behavior to achieve the best performance in both fill-in-the-blank (FITB) and good example sentence selection tasks. We further conduct a classroom user study with college ESL learners. The results of the user study show that the proposed agent can find out example sentences that help students learn more easily and efficiently. Compared to other models, the proposed agent improves the score of more than 17% of students after learning.
RISE Video Dataset: Recognizing Industrial Smoke Emissions
May 20, 2020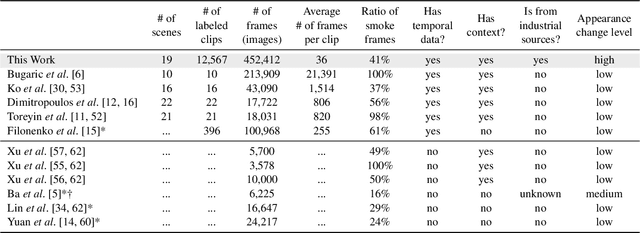
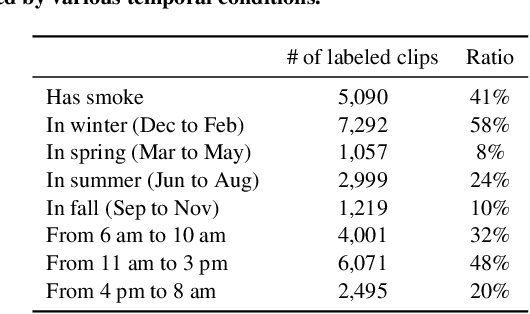
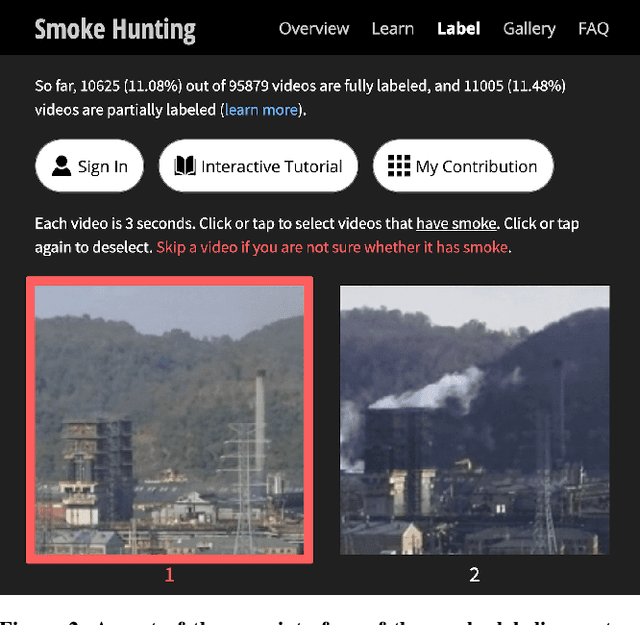

Industrial smoke emissions pose a significant concern to human health. Prior works have shown that using Computer Vision (CV) techniques to identify smoke as visual evidence can influence the attitude of regulators and empower citizens in pursuing environmental justice. However, existing datasets do not have sufficient quality nor quantity for training robust CV models to support air quality advocacy. We introduce RISE, the first large-scale video dataset for Recognizing Industrial Smoke Emissions. We adopt the citizen science approach to collaborate with local community members in annotating whether a video clip has smoke emissions. Our dataset contains 12,567 clips with 19 distinct views from cameras on three sites that monitored three different industrial facilities. The clips are from 30 days that spans four seasons in two years in the daytime. We run experiments using deep neural networks developed for video action recognition to establish a performance baseline and reveal the challenges for smoke recognition. Our data analysis also shows opportunities for integrating citizen scientists and crowd workers into the application of Artificial Intelligence for social good.
CODA-19: Reliably Annotating Research Aspects on 10,000+ CORD-19 Abstracts Using a Non-Expert Crowd
May 20, 2020
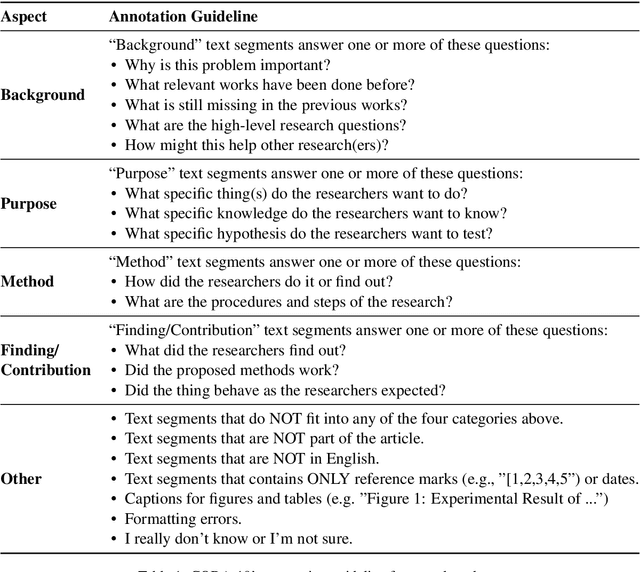


This paper introduces CODA-19, a human-annotated dataset that codes the Background, Purpose, Method, Finding/Contribution, and Other sections of 10,966 English abstracts in the COVID-19 Open Research Dataset. CODA-19 was created by 248 crowd workers from Amazon Mechanical Turk within 10 days, achieving a label quality comparable to that of experts. Each abstract was annotated by nine different workers, and the final labels were obtained by majority vote. The inter-annotator agreement (Cohen's kappa) between the crowd and the biomedical expert (0.741) is comparable to inter-expert agreement (0.788). CODA-19's labels have an accuracy of 82.2% when compared to the biomedical expert's labels, while the accuracy between experts was 85.0%. Reliable human annotations help scientists to understand the rapidly accelerating coronavirus literature and also serve as the battery of AI/NLP research, but obtaining expert annotations can be slow. We demonstrated that a non-expert crowd can be rapidly employed at scale to join the fight against COVID-19.
Smell Pittsburgh: Engaging Community Citizen Science for Air Quality
Dec 30, 2019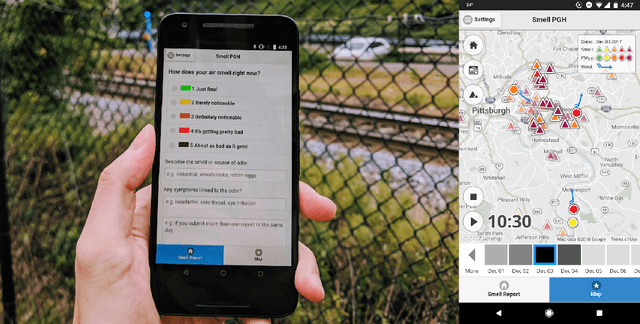
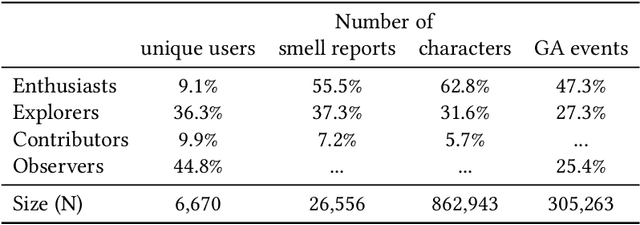
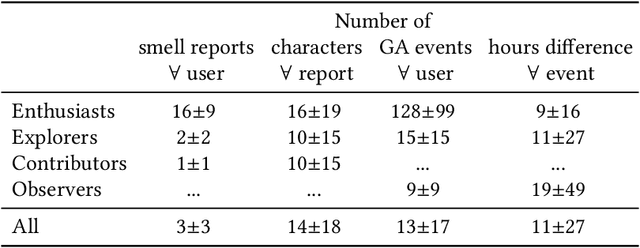
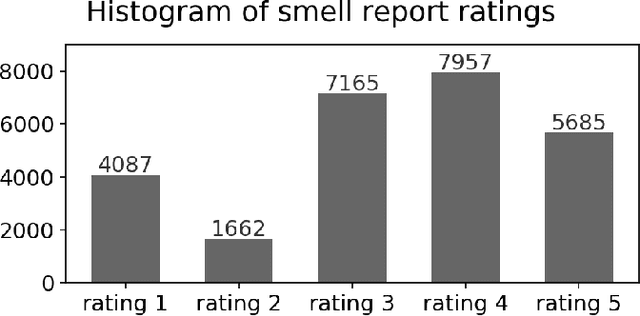
Urban air pollution has been linked to various human health concerns, including cardiopulmonary diseases. Communities who suffer from poor air quality often rely on experts to identify pollution sources due to the lack of accessible tools. Taking this into account, we developed Smell Pittsburgh, a system that enables community members to report odors and track where these odors are frequently concentrated. All smell report data are publicly accessible online. These reports are also sent to the local health department and visualized on a map along with air quality data from monitoring stations. This visualization provides a comprehensive overview of the local pollution landscape. Additionally, with these reports and air quality data, we developed a model to predict upcoming smell events and send push notifications to inform communities. We also applied regression analysis to identify statistically significant effects of push notifications on user engagement. Our evaluation of this system demonstrates that engaging residents in documenting their experiences with pollution odors can help identify local air pollution patterns, and can empower communities to advocate for better air quality. All citizen-contributed smell data are publicly accessible and can be downloaded from https://smellpgh.org.
Knowledge-Enriched Visual Storytelling
Dec 03, 2019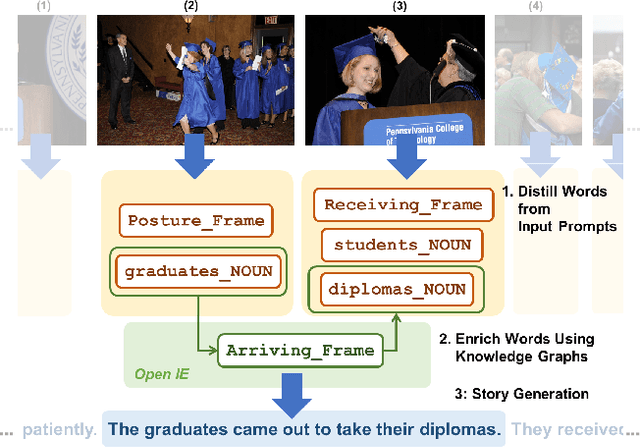

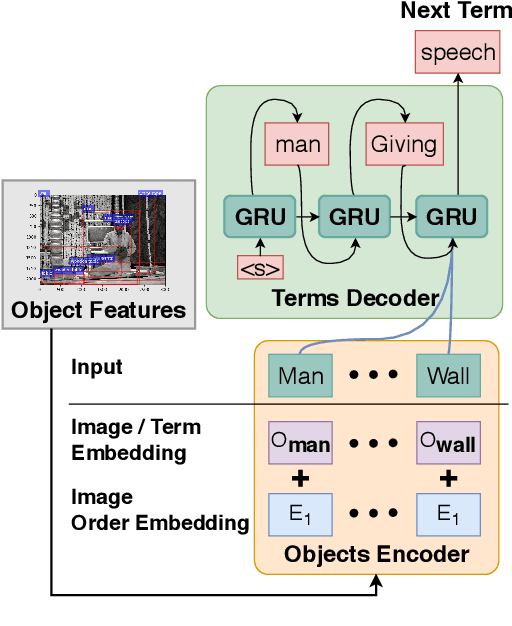
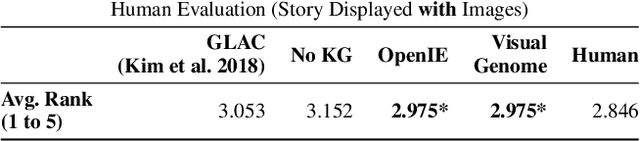
Stories are diverse and highly personalized, resulting in a large possible output space for story generation. Existing end-to-end approaches produce monotonous stories because they are limited to the vocabulary and knowledge in a single training dataset. This paper introduces KG-Story, a three-stage framework that allows the story generation model to take advantage of external Knowledge Graphs to produce interesting stories. KG-Story distills a set of representative words from the input prompts, enriches the word set by using external knowledge graphs, and finally generates stories based on the enriched word set. This distill-enrich-generate framework allows the use of external resources not only for the enrichment phase, but also for the distillation and generation phases. In this paper, we show the superiority of KG-Story for visual storytelling, where the input prompt is a sequence of five photos and the output is a short story. Per the human ranking evaluation, stories generated by KG-Story are on average ranked better than that of the state-of-the-art systems. Our code and output stories are available at https://github.com/zychen423/KE-VIST.
On Automating Conversations
Oct 24, 2019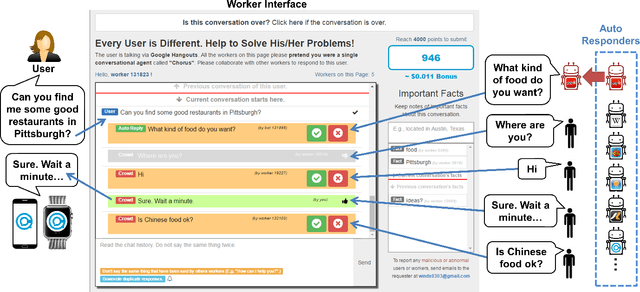
From 2016 to 2018, we developed and deployed Chorus, a system that blends real-time human computation with artificial intelligence (AI) and has real-world, open conversations with users. We took a top-down approach that started with a working crowd-powered system, Chorus, and then created a framework, Evorus, that enables Chorus to automate itself over time. Over our two-year deployment, more than 420 users talked with Chorus, having over 2,200 conversation sessions. This line of work demonstrated how a crowd-powered conversational assistant can be automated over time, and more importantly, how such a system can be deployed to talk with real users to help them with their everyday tasks. This position paper discusses two sets of challenges that we explored during the development and deployment of Chorus and Evorus: the challenges that come from being an "agent" and those that arise from the subset of conversations that are more difficult to automate.
InstructableCrowd: Creating IF-THEN Rules for Smartphones via Conversations with the Crowd
Sep 12, 2019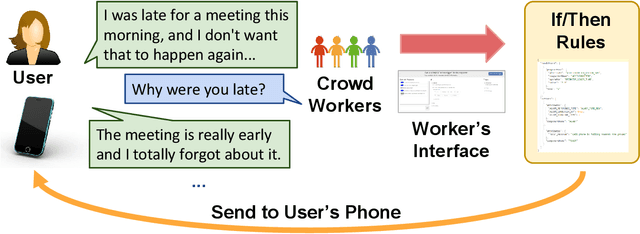
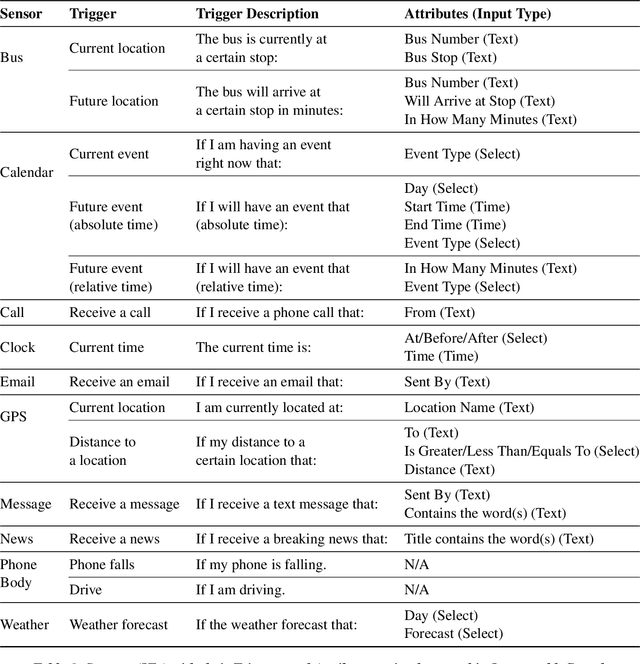
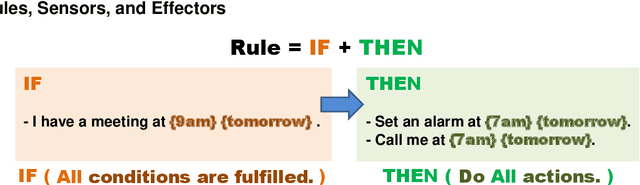
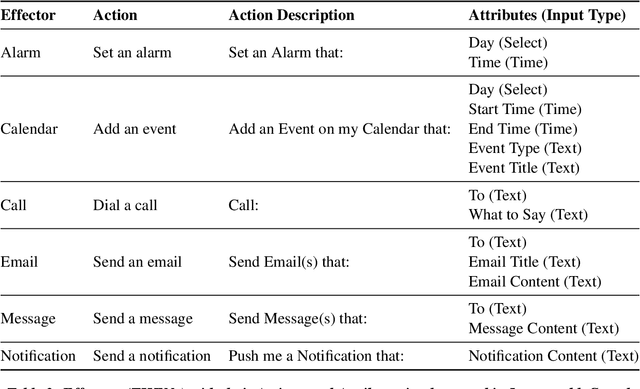
Natural language interfaces have become a common part of modern digital life. Chatbots utilize text-based conversations to communicate with users; personal assistants on smartphones such as Google Assistant take direct speech commands from their users; and speech-controlled devices such as Amazon Echo use voice as their only input mode. In this paper, we introduce InstructableCrowd, a crowd-powered system that allows users to program their devices via conversation. The user verbally expresses a problem to the system, in which a group of crowd workers collectively respond and program relevant multi-part IF-THEN rules to help the user. The IF-THEN rules generated by InstructableCrowd connect relevant sensor combinations (e.g., location, weather, device acceleration, etc.) to useful effectors (e.g., text messages, device alarms, etc.). Our study showed that non-programmers can use the conversational interface of InstructableCrowd to create IF-THEN rules that have similar quality compared with the rules created manually. InstructableCrowd generally illustrates how users may converse with their devices, not only to trigger simple voice commands, but also to personalize their increasingly powerful and complicated devices.
* Published at Human Computation (2019) 6:1:113-146
Visual Story Post-Editing
Jun 05, 2019
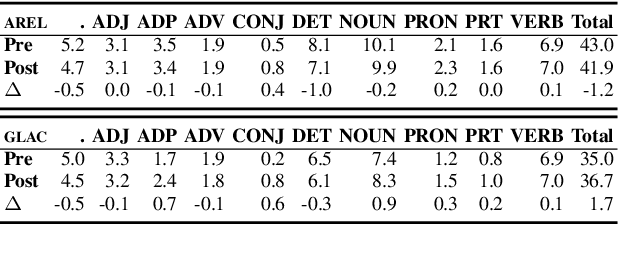
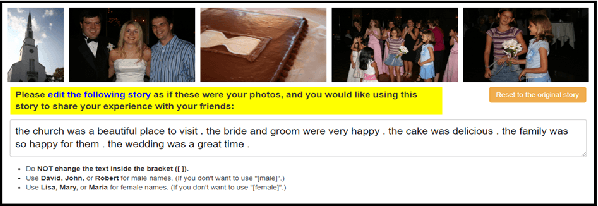

We introduce the first dataset for human edits of machine-generated visual stories and explore how these collected edits may be used for the visual story post-editing task. The dataset, VIST-Edit, includes 14,905 human edited versions of 2,981 machine-generated visual stories. The stories were generated by two state-of-the-art visual storytelling models, each aligned to 5 human-edited versions. We establish baselines for the task, showing how a relatively small set of human edits can be leveraged to boost the performance of large visual storytelling models. We also discuss the weak correlation between automatic evaluation scores and human ratings, motivating the need for new automatic metrics.