 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization for Adaptively-chosen Estimators via Stable Median
Jun 15, 2017Datasets are often reused to perform multiple statistical analyses in an adaptive way, in which each analysis may depend on the outcomes of previous analyses on the same dataset. Standard statistical guarantees do not account for these dependencies and little is known about how to provably avoid overfitting and false discovery in the adaptive setting. We consider a natural formalization of this problem in which the goal is to design an algorithm that, given a limited number of i.i.d.~samples from an unknown distribution, can answer adaptively-chosen queries about that distribution. We present an algorithm that estimates the expectations of $k$ arbitrary adaptively-chosen real-valued estimators using a number of samples that scales as $\sqrt{k}$. The answers given by our algorithm are essentially as accurate as if fresh samples were used to evaluate each estimator. In contrast, prior work yields error guarantees that scale with the worst-case sensitivity of each estimator. We also give a version of our algorithm that can be used to verify answers to such queries where the sample complexity depends logarithmically on the number of queries $k$ (as in the reusable holdout technique). Our algorithm is based on a simple approximate median algorithm that satisfies the strong stability guarantees of differential privacy. Our techniques provide a new approach for analyzing the generalization guarantees of differentially private algorithms.
Concentrated Differential Privacy: Simplifications, Extensions, and Lower Bounds
May 06, 2016"Concentrated differential privacy" was recently introduced by Dwork and Rothblum as a relaxation of differential privacy, which permits sharper analyses of many privacy-preserving computations. We present an alternative formulation of the concept of concentrated differential privacy in terms of the Renyi divergence between the distributions obtained by running an algorithm on neighboring inputs. With this reformulation in hand, we prove sharper quantitative results, establish lower bounds, and raise a few new questions. We also unify this approach with approximate differential privacy by giving an appropriate definition of "approximate concentrated differential privacy."
Make Up Your Mind: The Price of Online Queries in Differential Privacy
Apr 15, 2016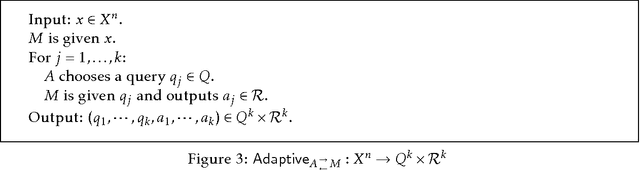
We consider the problem of answering queries about a sensitive dataset subject to differential privacy. The queries may be chosen adversarially from a larger set Q of allowable queries in one of three ways, which we list in order from easiest to hardest to answer: Offline: The queries are chosen all at once and the differentially private mechanism answers the queries in a single batch. Online: The queries are chosen all at once, but the mechanism only receives the queries in a streaming fashion and must answer each query before seeing the next query. Adaptive: The queries are chosen one at a time and the mechanism must answer each query before the next query is chosen. In particular, each query may depend on the answers given to previous queries. Many differentially private mechanisms are just as efficient in the adaptive model as they are in the offline model. Meanwhile, most lower bounds for differential privacy hold in the offline setting. This suggests that the three models may be equivalent. We prove that these models are all, in fact, distinct. Specifically, we show that there is a family of statistical queries such that exponentially more queries from this family can be answered in the offline model than in the online model. We also exhibit a family of search queries such that exponentially more queries from this family can be answered in the online model than in the adaptive model. We also investigate whether such separations might hold for simple queries like threshold queries over the real line.
More General Queries and Less Generalization Error in Adaptive Data Analysis
Nov 10, 2015


Adaptivity is an important feature of data analysis---typically the choice of questions asked about a dataset depends on previous interactions with the same dataset. However, generalization error is typically bounded in a non-adaptive model, where all questions are specified before the dataset is drawn. Recent work by Dwork et al. (STOC '15) and Hardt and Ullman (FOCS '14) initiated the formal study of this problem, and gave the first upper and lower bounds on the achievable generalization error for adaptive data analysis. Specifically, suppose there is an unknown distribution $\mathcal{P}$ and a set of $n$ independent samples $x$ is drawn from $\mathcal{P}$. We seek an algorithm that, given $x$ as input, "accurately" answers a sequence of adaptively chosen "queries" about the unknown distribution $\mathcal{P}$. How many samples $n$ must we draw from the distribution, as a function of the type of queries, the number of queries, and the desired level of accuracy? In this work we make two new contributions towards resolving this question: *We give upper bounds on the number of samples $n$ that are needed to answer statistical queries that improve over the bounds of Dwork et al. *We prove the first upper bounds on the number of samples required to answer more general families of queries. These include arbitrary low-sensitivity queries and the important class of convex risk minimization queries. As in Dwork et al., our algorithms are based on a connection between differential privacy and generalization error, but we feel that our analysis is simpler and more modular, which may be useful for studying these questions in the future.
Algorithmic Stability for Adaptive Data Analysis
Nov 08, 2015
Adaptivity is an important feature of data analysis---the choice of questions to ask about a dataset often depends on previous interactions with the same dataset. However, statistical validity is typically studied in a nonadaptive model, where all questions are specified before the dataset is drawn. Recent work by Dwork et al. (STOC, 2015) and Hardt and Ullman (FOCS, 2014) initiated the formal study of this problem, and gave the first upper and lower bounds on the achievable generalization error for adaptive data analysis. Specifically, suppose there is an unknown distribution $\mathbf{P}$ and a set of $n$ independent samples $\mathbf{x}$ is drawn from $\mathbf{P}$. We seek an algorithm that, given $\mathbf{x}$ as input, accurately answers a sequence of adaptively chosen queries about the unknown distribution $\mathbf{P}$. How many samples $n$ must we draw from the distribution, as a function of the type of queries, the number of queries, and the desired level of accuracy? In this work we make two new contributions: (i) We give upper bounds on the number of samples $n$ that are needed to answer statistical queries. The bounds improve and simplify the work of Dwork et al. (STOC, 2015), and have been applied in subsequent work by those authors (Science, 2015, NIPS, 2015). (ii) We prove the first upper bounds on the number of samples required to answer more general families of queries. These include arbitrary low-sensitivity queries and an important class of optimization queries. As in Dwork et al., our algorithms are based on a connection with algorithmic stability in the form of differential privacy. We extend their work by giving a quantitatively optimal, more general, and simpler proof of their main theorem that stability implies low generalization error. We also study weaker stability guarantees such as bounded KL divergence and total variation distance.
Interactive Fingerprinting Codes and the Hardness of Preventing False Discovery
Feb 20, 2015We show an essentially tight bound on the number of adaptively chosen statistical queries that a computationally efficient algorithm can answer accurately given $n$ samples from an unknown distribution. A statistical query asks for the expectation of a predicate over the underlying distribution, and an answer to a statistical query is accurate if it is "close" to the correct expectation over the distribution. This question was recently studied by Dwork et al., who showed how to answer $\tilde{\Omega}(n^2)$ queries efficiently, and also by Hardt and Ullman, who showed that answering $\tilde{O}(n^3)$ queries is hard. We close the gap between the two bounds and show that, under a standard hardness assumption, there is no computationally efficient algorithm that, given $n$ samples from an unknown distribution, can give valid answers to $O(n^2)$ adaptively chosen statistical queries. An implication of our results is that computationally efficient algorithms for answering arbitrary, adaptively chosen statistical queries may as well be differentially private. We obtain our results using a new connection between the problem of answering adaptively chosen statistical queries and a combinatorial object called an interactive fingerprinting code. In order to optimize our hardness result, we give a new Fourier-analytic approach to analyzing fingerprinting codes that is simpler, more flexible, and yields better parameters than previous constructions.
Between Pure and Approximate Differential Privacy
Jan 24, 2015
We show a new lower bound on the sample complexity of $(\varepsilon, \delta)$-differentially private algorithms that accurately answer statistical queries on high-dimensional databases. The novelty of our bound is that it depends optimally on the parameter $\delta$, which loosely corresponds to the probability that the algorithm fails to be private, and is the first to smoothly interpolate between approximate differential privacy ($\delta > 0$) and pure differential privacy ($\delta = 0$). Specifically, we consider a database $D \in \{\pm1\}^{n \times d}$ and its \emph{one-way marginals}, which are the $d$ queries of the form "What fraction of individual records have the $i$-th bit set to $+1$?" We show that in order to answer all of these queries to within error $\pm \alpha$ (on average) while satisfying $(\varepsilon, \delta)$-differential privacy, it is necessary that $$ n \geq \Omega\left( \frac{\sqrt{d \log(1/\delta)}}{\alpha \varepsilon} \right), $$ which is optimal up to constant factors. To prove our lower bound, we build on the connection between \emph{fingerprinting codes} and lower bounds in differential privacy (Bun, Ullman, and Vadhan, STOC'14). In addition to our lower bound, we give new purely and approximately differentially private algorithms for answering arbitrary statistical queries that improve on the sample complexity of the standard Laplace and Gaussian mechanisms for achieving worst-case accuracy guarantees by a logarithmic factor.
Weighted Polynomial Approximations: Limits for Learning and Pseudorandomness
Dec 08, 2014Polynomial approximations to boolean functions have led to many positive results in computer science. In particular, polynomial approximations to the sign function underly algorithms for agnostically learning halfspaces, as well as pseudorandom generators for halfspaces. In this work, we investigate the limits of these techniques by proving inapproximability results for the sign function. Firstly, the polynomial regression algorithm of Kalai et al. (SIAM J. Comput. 2008) shows that halfspaces can be learned with respect to log-concave distributions on $\mathbb{R}^n$ in the challenging agnostic learning model. The power of this algorithm relies on the fact that under log-concave distributions, halfspaces can be approximated arbitrarily well by low-degree polynomials. We ask whether this technique can be extended beyond log-concave distributions, and establish a negative result. We show that polynomials of any degree cannot approximate the sign function to within arbitrarily low error for a large class of non-log-concave distributions on the real line, including those with densities proportional to $\exp(-|x|^{0.99})$. Secondly, we investigate the derandomization of Chernoff-type concentration inequalities. Chernoff-type tail bounds on sums of independent random variables have pervasive applications in theoretical computer science. Schmidt et al. (SIAM J. Discrete Math. 1995) showed that these inequalities can be established for sums of random variables with only $O(\log(1/\delta))$-wise independence, for a tail probability of $\delta$. We show that their results are tight up to constant factors. These results rely on techniques from weighted approximation theory, which studies how well functions on the real line can be approximated by polynomials under various distributions. We believe that these techniques will have further applications in other areas of computer science.