 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpitome for Automatic Image Colorization
Oct 08, 2012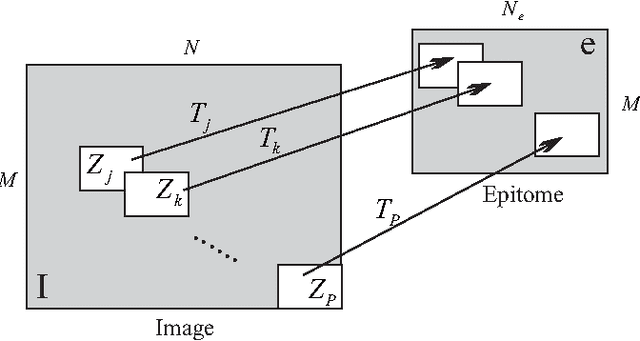
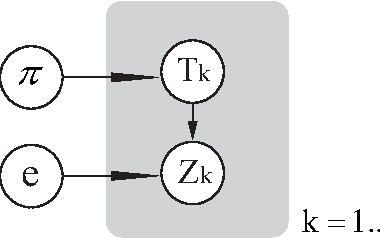


Image colorization adds color to grayscale images. It not only increases the visual appeal of grayscale images, but also enriches the information contained in scientific images that lack color information. Most existing methods of colorization require laborious user interaction for scribbles or image segmentation. To eliminate the need for human labor, we develop an automatic image colorization method using epitome. Built upon a generative graphical model, epitome is a condensed image appearance and shape model which also proves to be an effective summary of color information for the colorization task. We train the epitome from the reference images and perform inference in the epitome to colorize grayscale images, rendering better colorization results than previous method in our experiments.
Regularized Maximum Likelihood for Intrinsic Dimension Estimation
Mar 15, 2012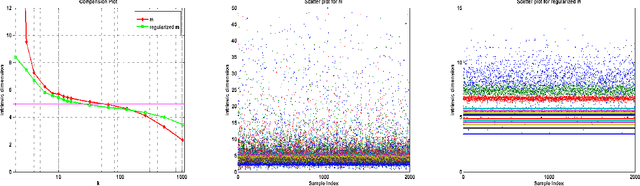
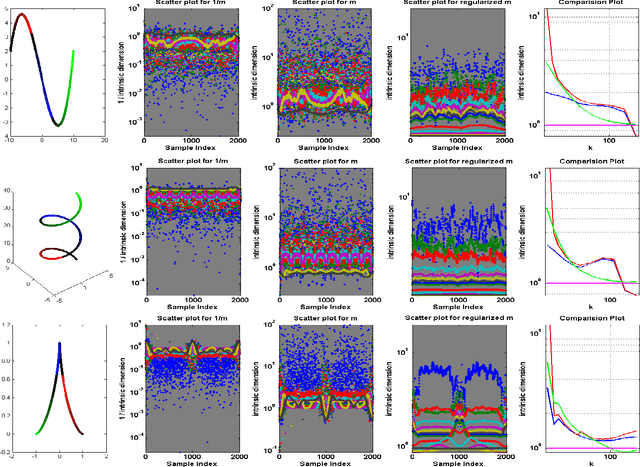
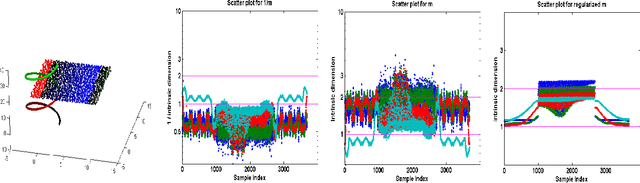
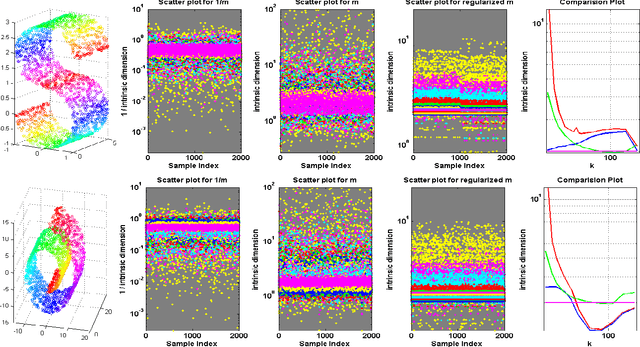
We propose a new method for estimating the intrinsic dimension of a dataset by applying the principle of regularized maximum likelihood to the distances between close neighbors. We propose a regularization scheme which is motivated by divergence minimization principles. We derive the estimator by a Poisson process approximation, argue about its convergence properties and apply it to a number of simulated and real datasets. We also show it has the best overall performance compared with two other intrinsic dimension estimators.
Bregman Distance to L1 Regularized Logistic Regression
Apr 21, 2010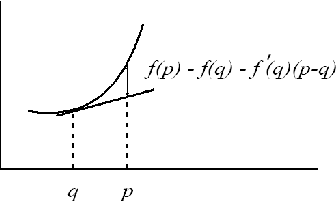
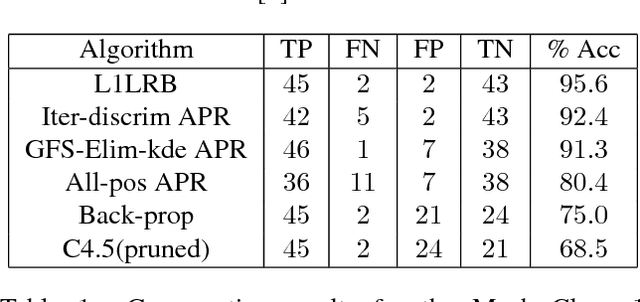
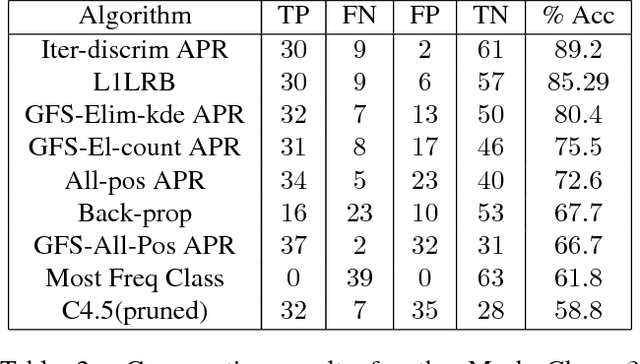
In this work we investigate the relationship between Bregman distances and regularized Logistic Regression model. We present a detailed study of Bregman Distance minimization, a family of generalized entropy measures associated with convex functions. We convert the L1-regularized logistic regression into this more general framework and propose a primal-dual method based algorithm for learning the parameters. We pose L1-regularized logistic regression into Bregman distance minimization and then apply non-linear constrained optimization techniques to estimate the parameters of the logistic model.