 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Training of Hybrid CNN-CRF Models for Stereo
May 03, 2017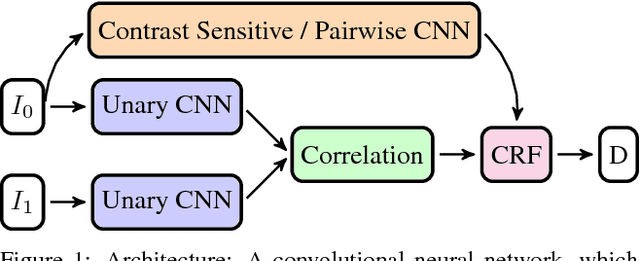
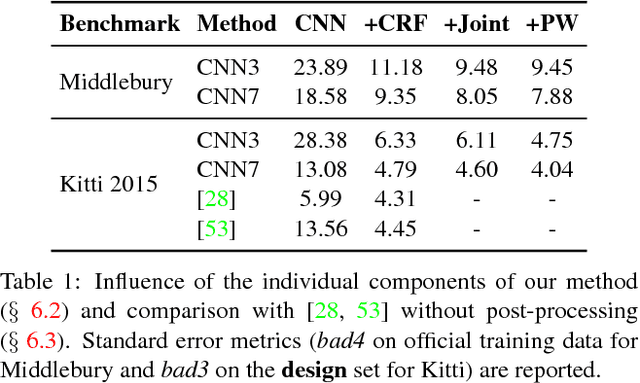

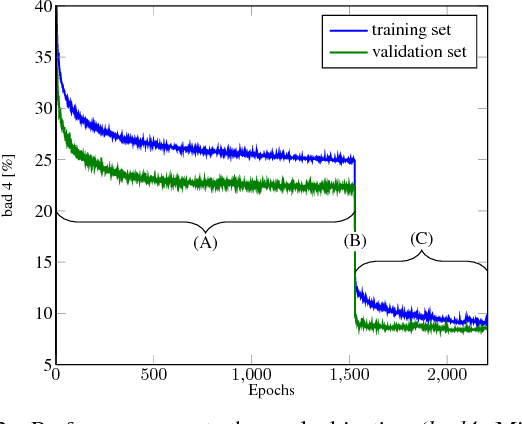
We propose a novel and principled hybrid CNN+CRF model for stereo estimation. Our model allows to exploit the advantages of both, convolutional neural networks (CNNs) and conditional random fields (CRFs) in an unified approach. The CNNs compute expressive features for matching and distinctive color edges, which in turn are used to compute the unary and binary costs of the CRF. For inference, we apply a recently proposed highly parallel dual block descent algorithm which only needs a small fixed number of iterations to compute a high-quality approximate minimizer. As the main contribution of the paper, we propose a theoretically sound method based on the structured output support vector machine (SSVM) to train the hybrid CNN+CRF model on large-scale data end-to-end. Our trained models perform very well despite the fact that we are using shallow CNNs and do not apply any kind of post-processing to the final output of the CRF. We evaluate our combined models on challenging stereo benchmarks such as Middlebury 2014 and Kitti 2015 and also investigate the performance of each individual component.
Learning a Variational Network for Reconstruction of Accelerated MRI Data
Apr 03, 2017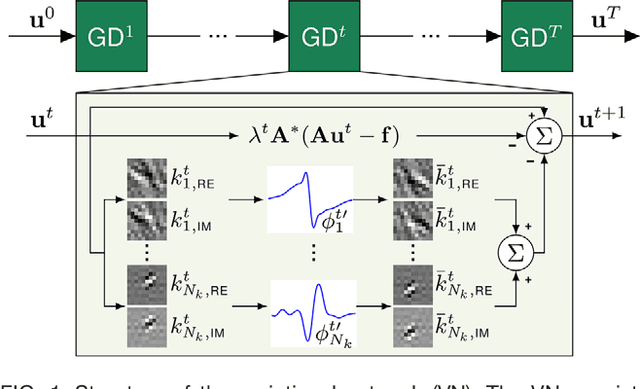
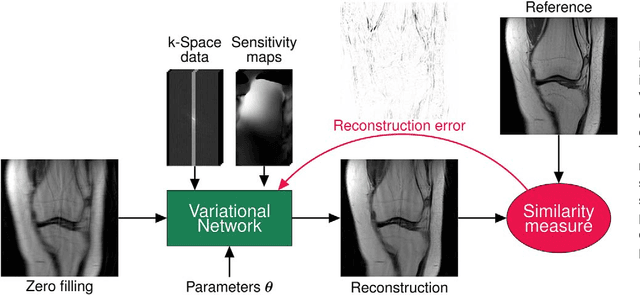
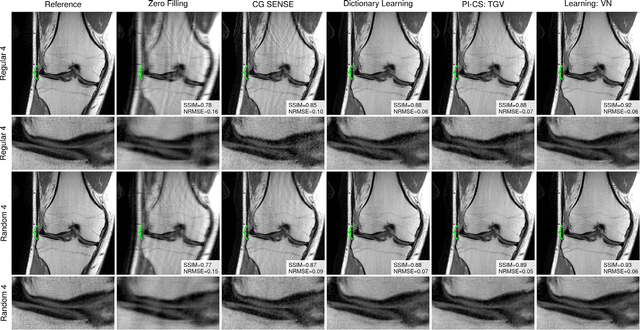
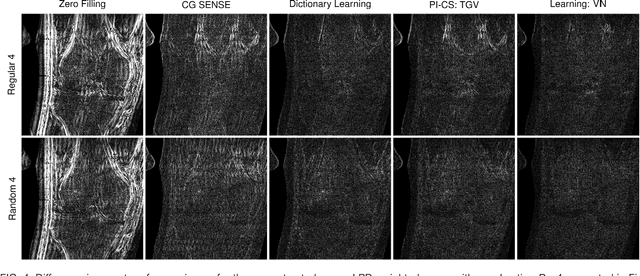
Purpose: To allow fast and high-quality reconstruction of clinical accelerated multi-coil MR data by learning a variational network that combines the mathematical structure of variational models with deep learning. Theory and Methods: Generalized compressed sensing reconstruction formulated as a variational model is embedded in an unrolled gradient descent scheme. All parameters of this formulation, including the prior model defined by filter kernels and activation functions as well as the data term weights, are learned during an offline training procedure. The learned model can then be applied online to previously unseen data. Results: The variational network approach is evaluated on a clinical knee imaging protocol. The variational network reconstructions outperform standard reconstruction algorithms in terms of image quality and residual artifacts for all tested acceleration factors and sampling patterns. Conclusion: Variational network reconstructions preserve the natural appearance of MR images as well as pathologies that were not included in the training data set. Due to its high computational performance, i.e., reconstruction time of 193 ms on a single graphics card, and the omission of parameter tuning once the network is trained, this new approach to image reconstruction can easily be integrated into clinical workflow.
Real-Time Panoramic Tracking for Event Cameras
Mar 21, 2017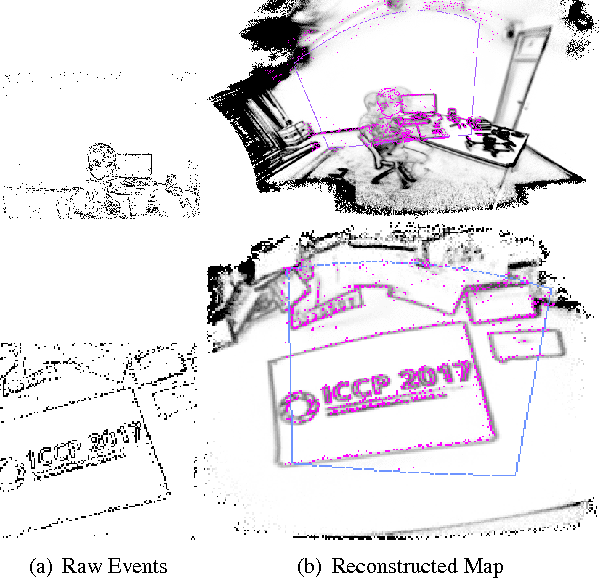
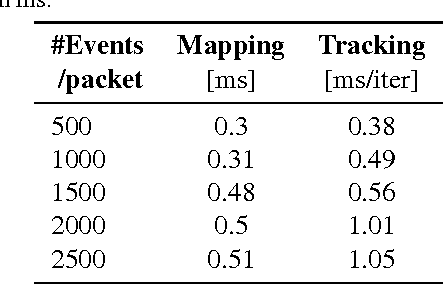
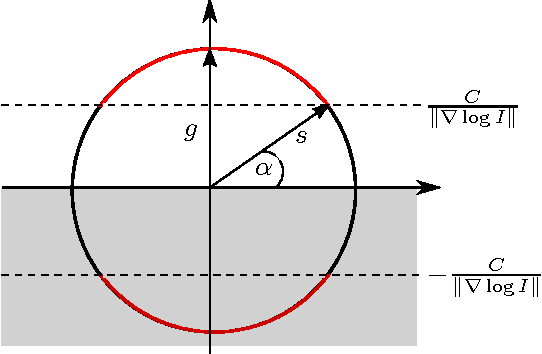
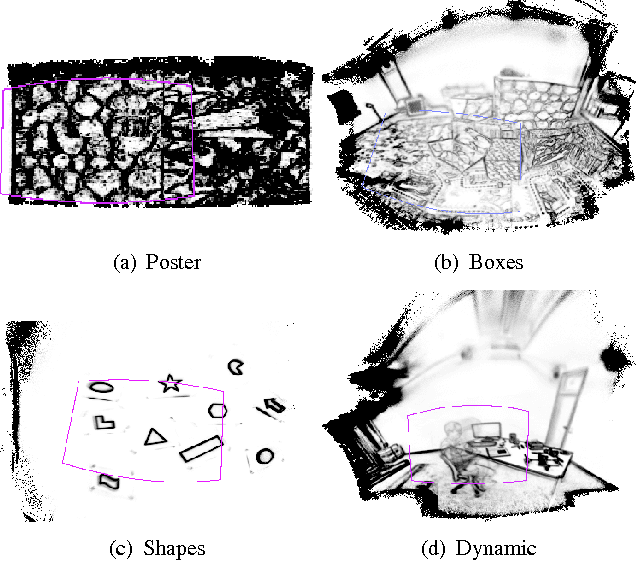
Event cameras are a paradigm shift in camera technology. Instead of full frames, the sensor captures a sparse set of events caused by intensity changes. Since only the changes are transferred, those cameras are able to capture quick movements of objects in the scene or of the camera itself. In this work we propose a novel method to perform camera tracking of event cameras in a panoramic setting with three degrees of freedom. We propose a direct camera tracking formulation, similar to state-of-the-art in visual odometry. We show that the minimal information needed for simultaneous tracking and mapping is the spatial position of events, without using the appearance of the imaged scene point. We verify the robustness to fast camera movements and dynamic objects in the scene on a recently proposed dataset and self-recorded sequences.
Trainable Nonlinear Reaction Diffusion: A Flexible Framework for Fast and Effective Image Restoration
Aug 20, 2016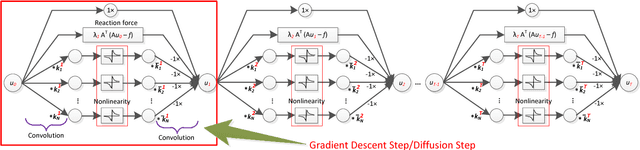
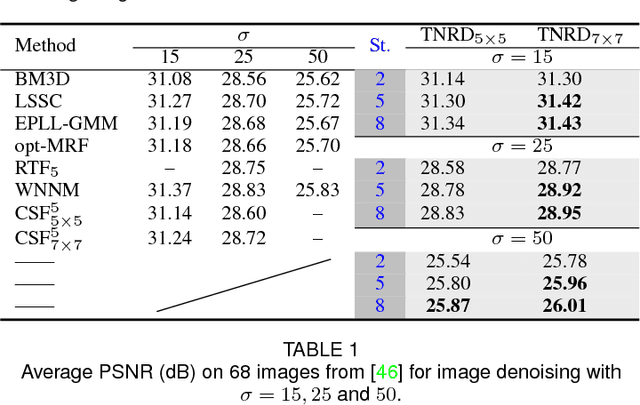
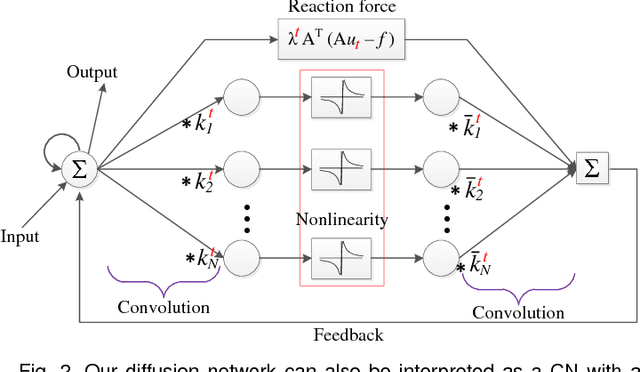
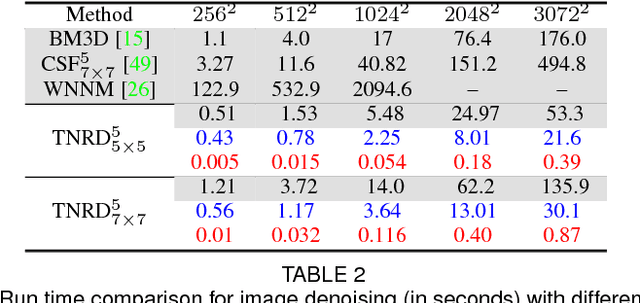
Image restoration is a long-standing problem in low-level computer vision with many interesting applications. We describe a flexible learning framework based on the concept of nonlinear reaction diffusion models for various image restoration problems. By embodying recent improvements in nonlinear diffusion models, we propose a dynamic nonlinear reaction diffusion model with time-dependent parameters (\ie, linear filters and influence functions). In contrast to previous nonlinear diffusion models, all the parameters, including the filters and the influence functions, are simultaneously learned from training data through a loss based approach. We call this approach TNRD -- \textit{Trainable Nonlinear Reaction Diffusion}. The TNRD approach is applicable for a variety of image restoration tasks by incorporating appropriate reaction force. We demonstrate its capabilities with three representative applications, Gaussian image denoising, single image super resolution and JPEG deblocking. Experiments show that our trained nonlinear diffusion models largely benefit from the training of the parameters and finally lead to the best reported performance on common test datasets for the tested applications. Our trained models preserve the structural simplicity of diffusion models and take only a small number of diffusion steps, thus are highly efficient. Moreover, they are also well-suited for parallel computation on GPUs, which makes the inference procedure extremely fast.
Real-Time Intensity-Image Reconstruction for Event Cameras Using Manifold Regularisation
Aug 04, 2016



Event cameras or neuromorphic cameras mimic the human perception system as they measure the per-pixel intensity change rather than the actual intensity level. In contrast to traditional cameras, such cameras capture new information about the scene at MHz frequency in the form of sparse events. The high temporal resolution comes at the cost of losing the familiar per-pixel intensity information. In this work we propose a variational model that accurately models the behaviour of event cameras, enabling reconstruction of intensity images with arbitrary frame rate in real-time. Our method is formulated on a per-event-basis, where we explicitly incorporate information about the asynchronous nature of events via an event manifold induced by the relative timestamps of events. In our experiments we verify that solving the variational model on the manifold produces high-quality images without explicitly estimating optical flow.
Total variation on a tree
Apr 25, 2016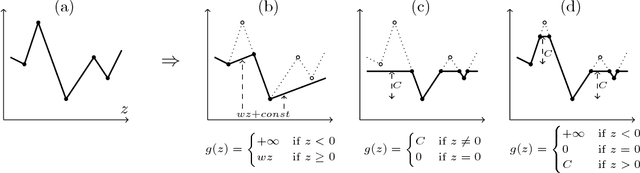
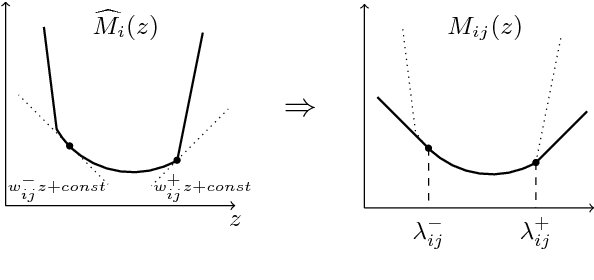
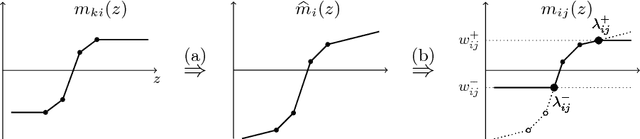
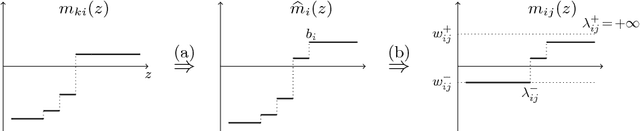
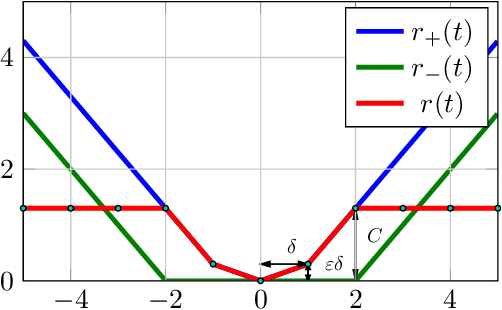
We consider the problem of minimizing the continuous valued total variation subject to different unary terms on trees and propose fast direct algorithms based on dynamic programming to solve these problems. We treat both the convex and the non-convex case and derive worst case complexities that are equal or better than existing methods. We show applications to total variation based 2D image processing and computer vision problems based on a Lagrangian decomposition approach. The resulting algorithms are very efficient, offer a high degree of parallelism and come along with memory requirements which are only in the order of the number of image pixels.
Acceleration of the PDHGM on strongly convex subspaces
Feb 10, 2016
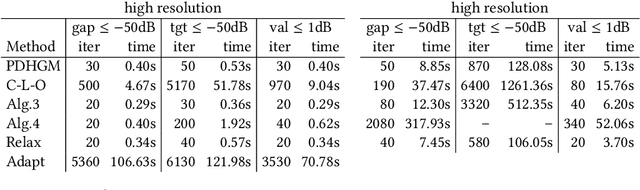
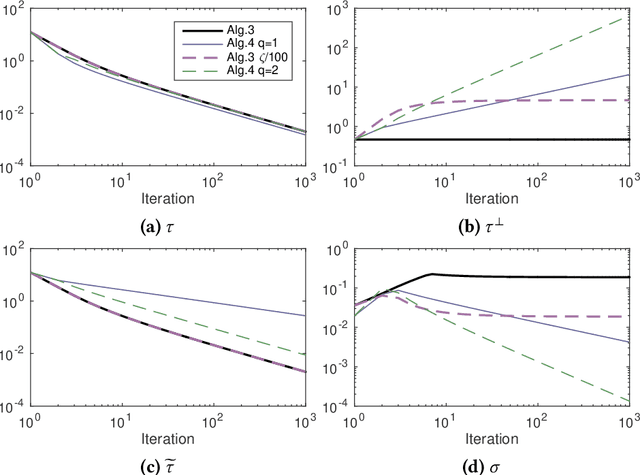
We propose several variants of the primal-dual method due to Chambolle and Pock. Without requiring full strong convexity of the objective functions, our methods are accelerated on subspaces with strong convexity. This yields mixed rates, $O(1/N^2)$ with respect to initialisation and $O(1/N)$ with respect to the dual sequence, and the residual part of the primal sequence. We demonstrate the efficacy of the proposed methods on image processing problems lacking strong convexity, such as total generalised variation denoising and total variation deblurring.
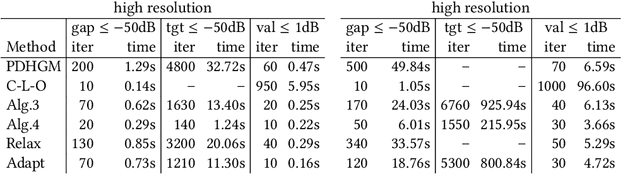
Solving Dense Image Matching in Real-Time using Discrete-Continuous Optimization
Jan 23, 2016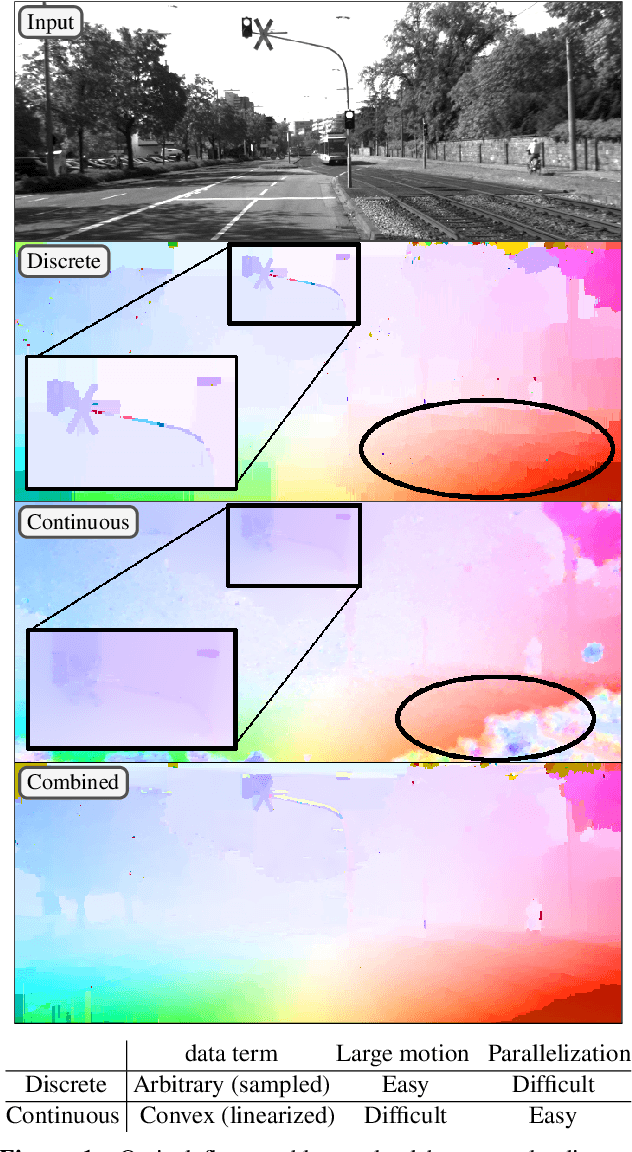


Dense image matching is a fundamental low-level problem in Computer Vision, which has received tremendous attention from both discrete and continuous optimization communities. The goal of this paper is to combine the advantages of discrete and continuous optimization in a coherent framework. We devise a model based on energy minimization, to be optimized by both discrete and continuous algorithms in a consistent way. In the discrete setting, we propose a novel optimization algorithm that can be massively parallelized. In the continuous setting we tackle the problem of non-convex regularizers by a formulation based on differences of convex functions. The resulting hybrid discrete-continuous algorithm can be efficiently accelerated by modern GPUs and we demonstrate its real-time performance for the applications of dense stereo matching and optical flow.
On learning optimized reaction diffusion processes for effective image restoration
Mar 25, 2015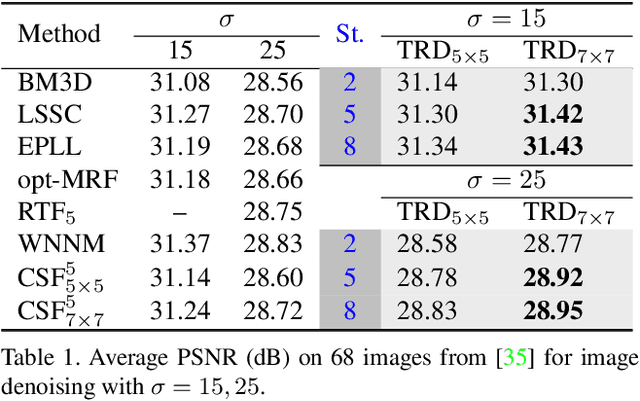

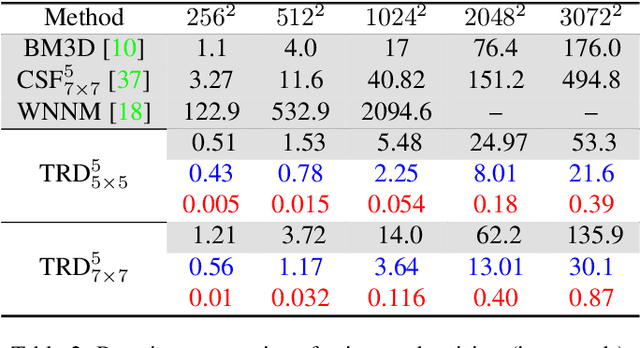
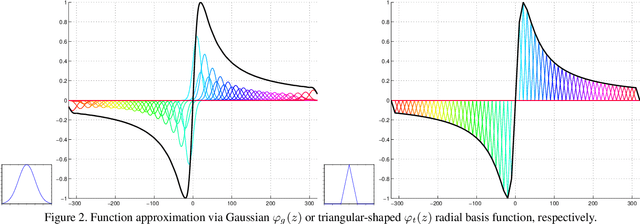
For several decades, image restoration remains an active research topic in low-level computer vision and hence new approaches are constantly emerging. However, many recently proposed algorithms achieve state-of-the-art performance only at the expense of very high computation time, which clearly limits their practical relevance. In this work, we propose a simple but effective approach with both high computational efficiency and high restoration quality. We extend conventional nonlinear reaction diffusion models by several parametrized linear filters as well as several parametrized influence functions. We propose to train the parameters of the filters and the influence functions through a loss based approach. Experiments show that our trained nonlinear reaction diffusion models largely benefit from the training of the parameters and finally lead to the best reported performance on common test datasets for image restoration. Due to their structural simplicity, our trained models are highly efficient and are also well-suited for parallel computation on GPUs.
An inertial forward-backward algorithm for monotone inclusions
Sep 12, 2014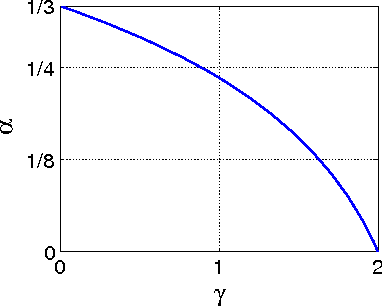

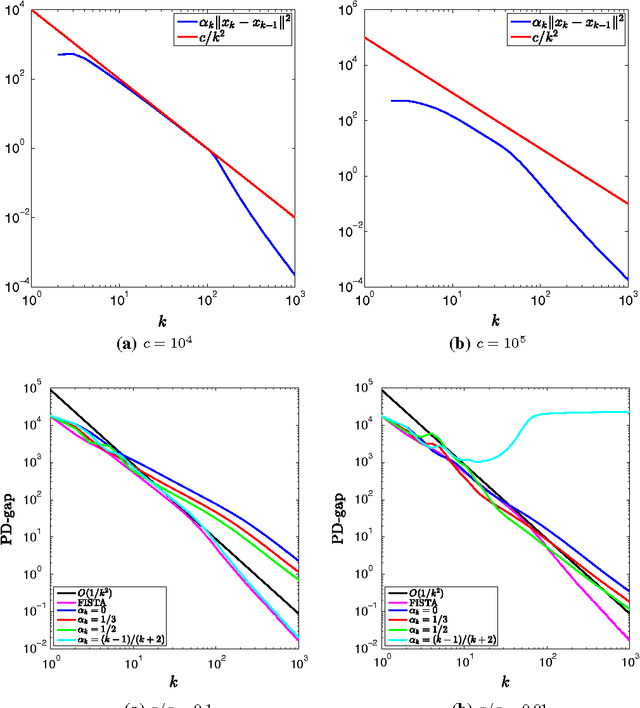
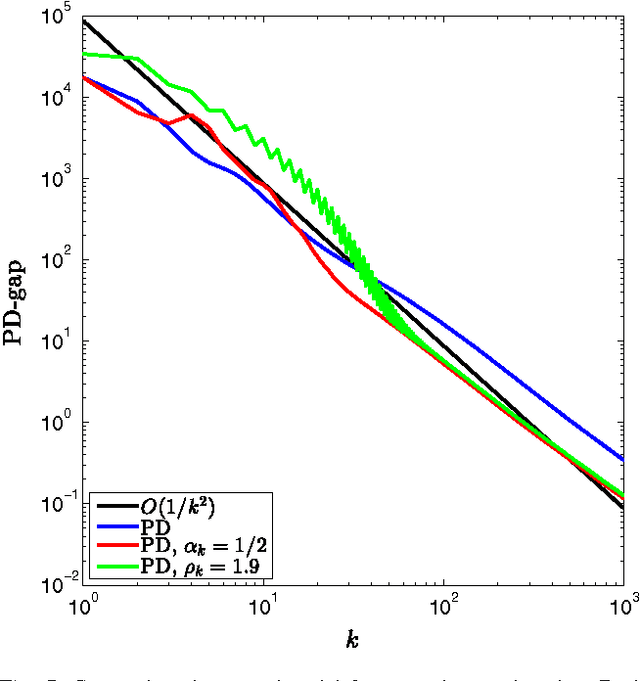
In this paper, we propose an inertial forward backward splitting algorithm to compute a zero of the sum of two monotone operators, with one of the two operators being co-coercive. The algorithm is inspired by the accelerated gradient method of Nesterov, but can be applied to a much larger class of problems including convex-concave saddle point problems and general monotone inclusions. We prove convergence of the algorithm in a Hilbert space setting and show that several recently proposed first-order methods can be obtained as special cases of the general algorithm. Numerical results show that the proposed algorithm converges faster than existing methods, while keeping the computational cost of each iteration basically unchanged.