 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-Level Fine-Grained Story Visualization
Aug 03, 2022

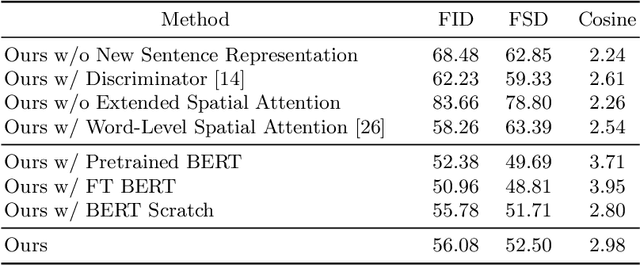
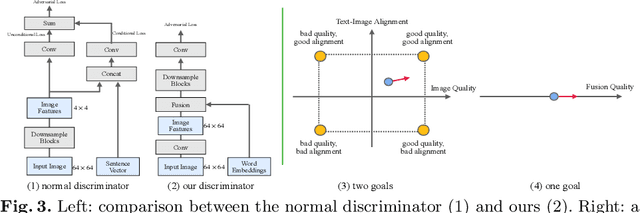
Story visualization aims to generate a sequence of images to narrate each sentence in a multi-sentence story with a global consistency across dynamic scenes and characters. Current works still struggle with output images' quality and consistency, and rely on additional semantic information or auxiliary captioning networks. To address these challenges, we first introduce a new sentence representation, which incorporates word information from all story sentences to mitigate the inconsistency problem. Then, we propose a new discriminator with fusion features and further extend the spatial attention to improve image quality and story consistency. Extensive experiments on different datasets and human evaluation demonstrate the superior performance of our approach, compared to state-of-the-art methods, neither using segmentation masks nor auxiliary captioning networks.
PCA: Semi-supervised Segmentation with Patch Confidence Adversarial Training
Jul 24, 2022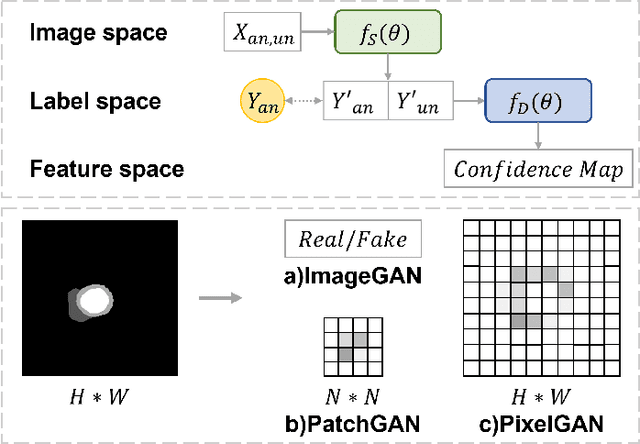
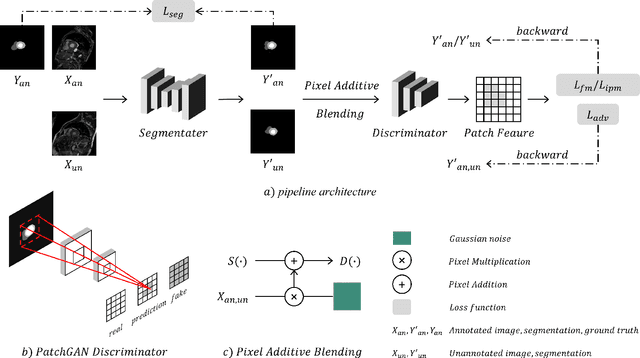
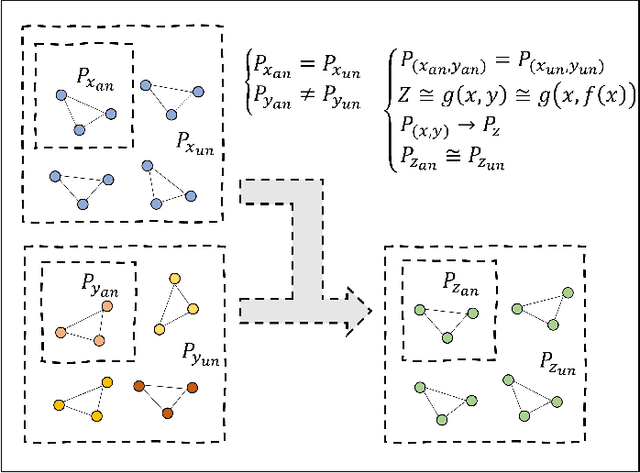
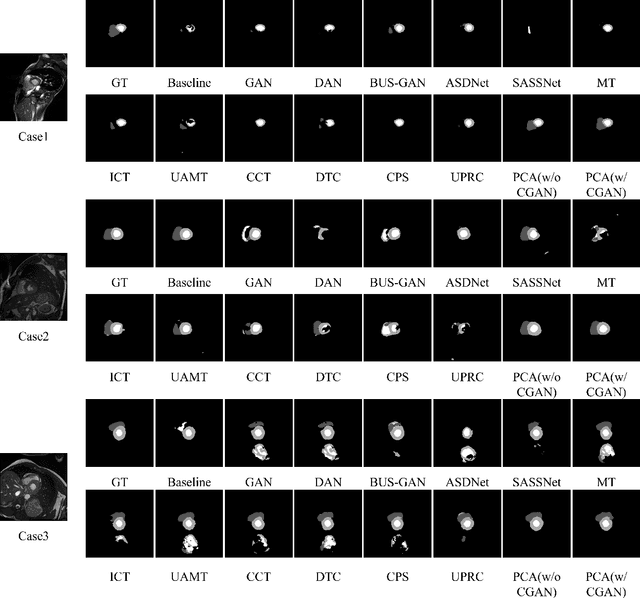
Deep learning based semi-supervised learning (SSL) methods have achieved strong performance in medical image segmentation, which can alleviate doctors' expensive annotation by utilizing a large amount of unlabeled data. Unlike most existing semi-supervised learning methods, adversarial training based methods distinguish samples from different sources by learning the data distribution of the segmentation map, leading the segmenter to generate more accurate predictions. We argue that the current performance restrictions for such approaches are the problems of feature extraction and learning preference. In this paper, we propose a new semi-supervised adversarial method called Patch Confidence Adversarial Training (PCA) for medical image segmentation. Rather than single scalar classification results or pixel-level confidence maps, our proposed discriminator creates patch confidence maps and classifies them at the scale of the patches. The prediction of unlabeled data learns the pixel structure and context information in each patch to get enough gradient feedback, which aids the discriminator in convergent to an optimal state and improves semi-supervised segmentation performance. Furthermore, at the discriminator's input, we supplement semantic information constraints on images, making it simpler for unlabeled data to fit the expected data distribution. Extensive experiments on the Automated Cardiac Diagnosis Challenge (ACDC) 2017 dataset and the Brain Tumor Segmentation (BraTS) 2019 challenge dataset show that our method outperforms the state-of-the-art semi-supervised methods, which demonstrates its effectiveness for medical image segmentation.
Explaining Chest X-ray Pathologies in Natural Language
Jul 09, 2022



Most deep learning algorithms lack explanations for their predictions, which limits their deployment in clinical practice. Approaches to improve explainability, especially in medical imaging, have often been shown to convey limited information, be overly reassuring, or lack robustness. In this work, we introduce the task of generating natural language explanations (NLEs) to justify predictions made on medical images. NLEs are human-friendly and comprehensive, and enable the training of intrinsically explainable models. To this goal, we introduce MIMIC-NLE, the first, large-scale, medical imaging dataset with NLEs. It contains over 38,000 NLEs, which explain the presence of various thoracic pathologies and chest X-ray findings. We propose a general approach to solve the task and evaluate several architectures on this dataset, including via clinician assessment.
NP-Match: When Neural Processes meet Semi-Supervised Learning
Jul 03, 2022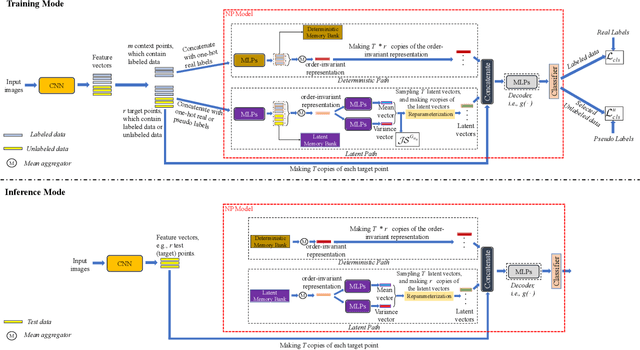
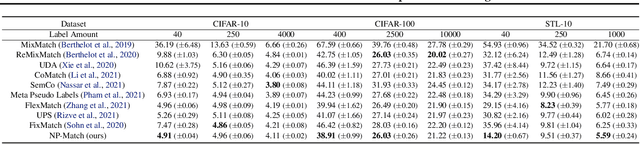
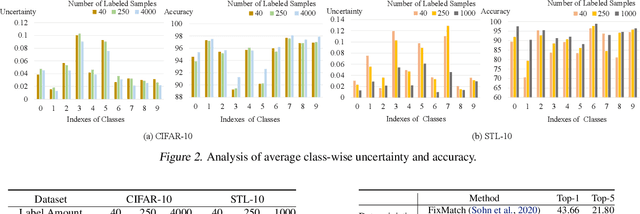
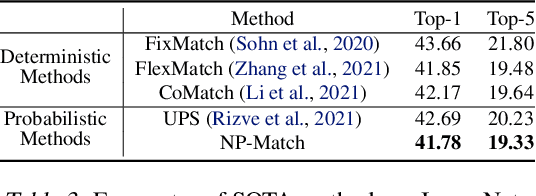
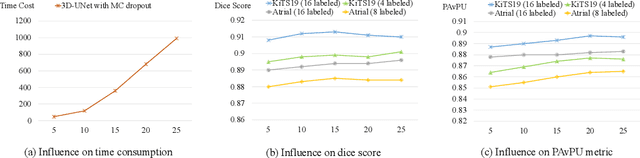
Semi-supervised learning (SSL) has been widely explored in recent years, and it is an effective way of leveraging unlabeled data to reduce the reliance on labeled data. In this work, we adjust neural processes (NPs) to the semi-supervised image classification task, resulting in a new method named NP-Match. NP-Match is suited to this task for two reasons. Firstly, NP-Match implicitly compares data points when making predictions, and as a result, the prediction of each unlabeled data point is affected by the labeled data points that are similar to it, which improves the quality of pseudo-labels. Secondly, NP-Match is able to estimate uncertainty that can be used as a tool for selecting unlabeled samples with reliable pseudo-labels. Compared with uncertainty-based SSL methods implemented with Monte Carlo (MC) dropout, NP-Match estimates uncertainty with much less computational overhead, which can save time at both the training and the testing phases. We conducted extensive experiments on four public datasets, and NP-Match outperforms state-of-the-art (SOTA) results or achieves competitive results on them, which shows the effectiveness of NP-Match and its potential for SSL.
Rethinking Bayesian Deep Learning Methods for Semi-Supervised Volumetric Medical Image Segmentation
Jun 18, 2022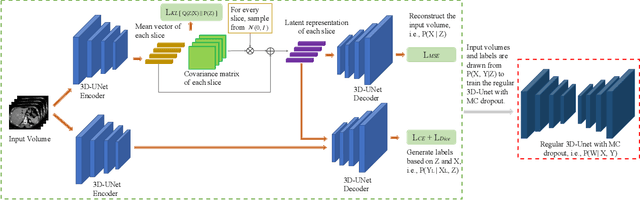
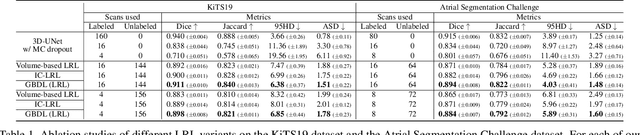
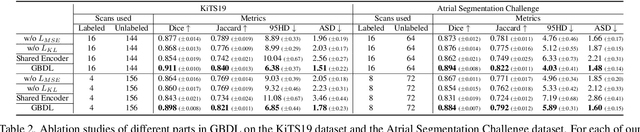
Recently, several Bayesian deep learning methods have been proposed for semi-supervised medical image segmentation. Although they have achieved promising results on medical benchmarks, some problems are still existing. Firstly, their overall architectures belong to the discriminative models, and hence, in the early stage of training, they only use labeled data for training, which might make them overfit to the labeled data. Secondly, in fact, they are only partially based on Bayesian deep learning, as their overall architectures are not designed under the Bayesian framework. However, unifying the overall architecture under the Bayesian perspective can make the architecture have a rigorous theoretical basis, so that each part of the architecture can have a clear probabilistic interpretation. Therefore, to solve the problems, we propose a new generative Bayesian deep learning (GBDL) architecture. GBDL belongs to the generative models, whose target is to estimate the joint distribution of input medical volumes and their corresponding labels. Estimating the joint distribution implicitly involves the distribution of data, so both labeled and unlabeled data can be utilized in the early stage of training, which alleviates the potential overfitting problem. Besides, GBDL is completely designed under the Bayesian framework, and thus we give its full Bayesian formulation, which lays a theoretical probabilistic foundation for our architecture. Extensive experiments show that our GBDL outperforms previous state-of-the-art methods in terms of four commonly used evaluation indicators on three public medical datasets.
Backpropagation at the Infinitesimal Inference Limit of Energy-Based Models: Unifying Predictive Coding, Equilibrium Propagation, and Contrastive Hebbian Learning
May 31, 2022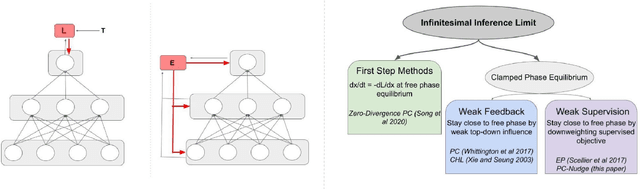
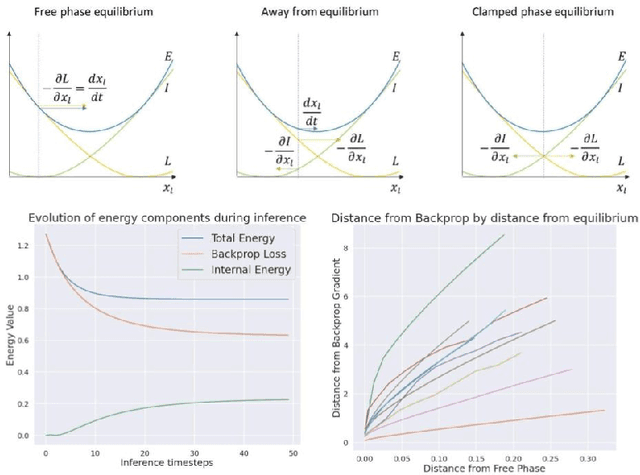
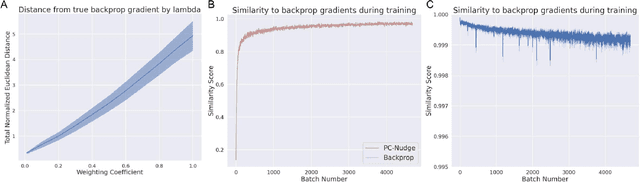
How the brain performs credit assignment is a fundamental unsolved problem in neuroscience. Many `biologically plausible' algorithms have been proposed, which compute gradients that approximate those computed by backpropagation (BP), and which operate in ways that more closely satisfy the constraints imposed by neural circuitry. Many such algorithms utilize the framework of energy-based models (EBMs), in which all free variables in the model are optimized to minimize a global energy function. However, in the literature, these algorithms exist in isolation and no unified theory exists linking them together. Here, we provide a comprehensive theory of the conditions under which EBMs can approximate BP, which lets us unify many of the BP approximation results in the literature (namely, predictive coding, equilibrium propagation, and contrastive Hebbian learning) and demonstrate that their approximation to BP arises from a simple and general mathematical property of EBMs at free-phase equilibrium. This property can then be exploited in different ways with different energy functions, and these specific choices yield a family of BP-approximating algorithms, which both includes the known results in the literature and can be used to derive new ones.
Clinical outcome prediction under hypothetical interventions -- a representation learning framework for counterfactual reasoning
May 15, 2022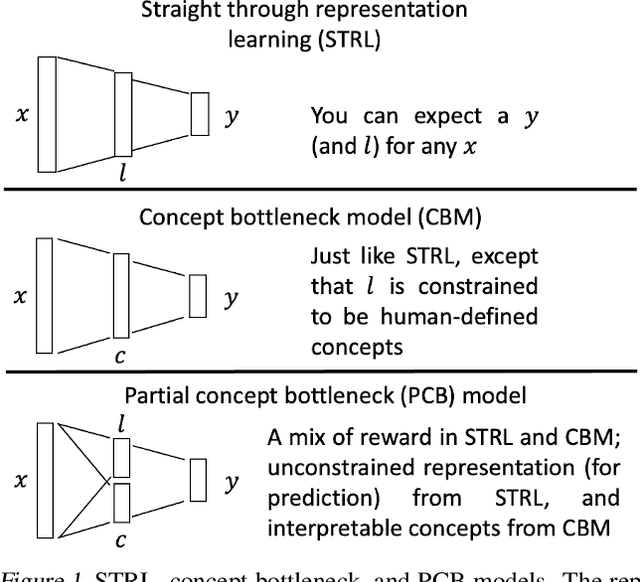
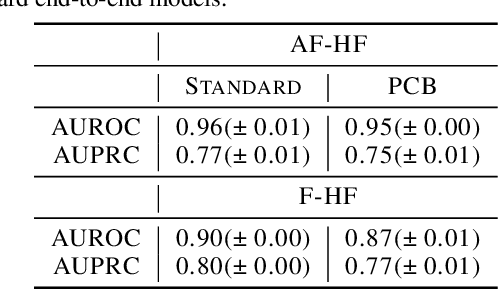
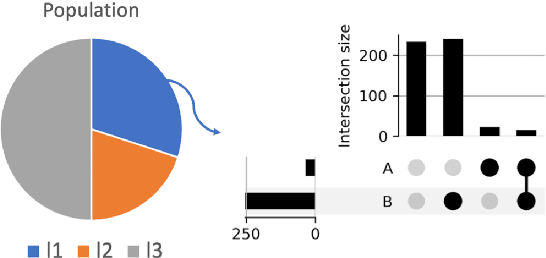
Most machine learning (ML) models are developed for prediction only; offering no option for causal interpretation of their predictions or parameters/properties. This can hamper the health systems' ability to employ ML models in clinical decision-making processes, where the need and desire for predicting outcomes under hypothetical investigations (i.e., counterfactual reasoning/explanation) is high. In this research, we introduce a new representation learning framework (i.e., partial concept bottleneck), which considers the provision of counterfactual explanations as an embedded property of the risk model. Despite architectural changes necessary for jointly optimising for prediction accuracy and counterfactual reasoning, the accuracy of our approach is comparable to prediction-only models. Our results suggest that our proposed framework has the potential to help researchers and clinicians improve personalised care (e.g., by investigating the hypothetical differential effects of interventions)
Beyond Distributional Hypothesis: Let Language Models Learn Meaning-Text Correspondence
May 08, 2022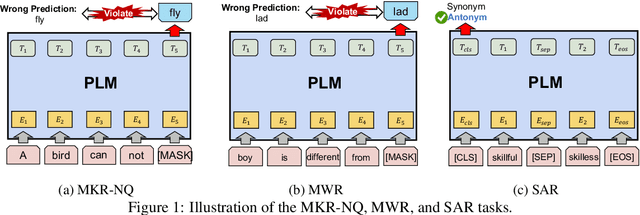
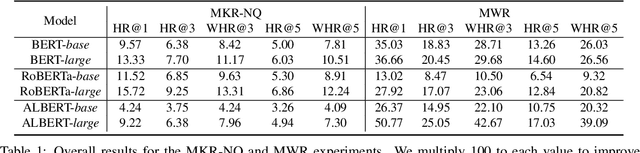
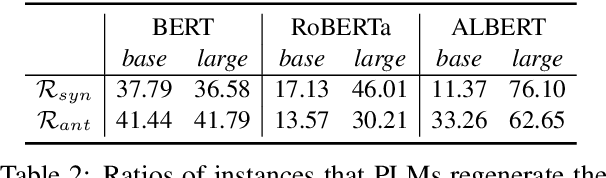
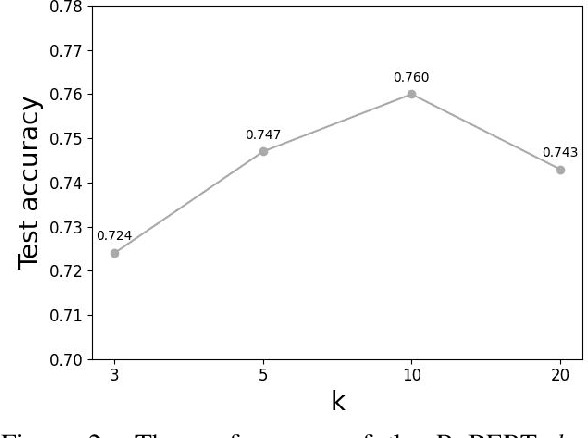
The logical negation property (LNP), which implies generating different predictions for semantically opposite inputs, is an important property that a trustworthy language model must satisfy. However, much recent evidence shows that large-size pre-trained language models (PLMs) do not satisfy this property. In this paper, we perform experiments using probing tasks to assess PLM's LNP understanding. Unlike previous studies that only examined negation expressions, we expand the boundary of the investigation to lexical semantics. Through experiments, we observe that PLMs violate the LNP frequently. To alleviate the issue, we propose a novel intermediate training task, names meaning-matching, designed to directly learn a meaning-text correspondence, instead of relying on the distributional hypothesis. Through multiple experiments, we find that the task enables PLMs to learn lexical semantic information. Also, through fine-tuning experiments on 7 GLUE tasks, we confirm that it is a safe intermediate task that guarantees a similar or better performance of downstream tasks. Finally, we observe that our proposed approach outperforms our previous counterparts despite its time and resource efficiency.
Deep Learning with Logical Constraints
May 01, 2022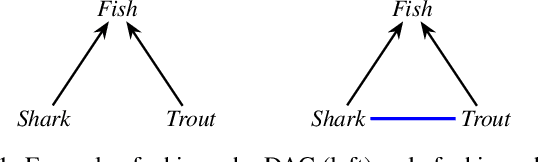

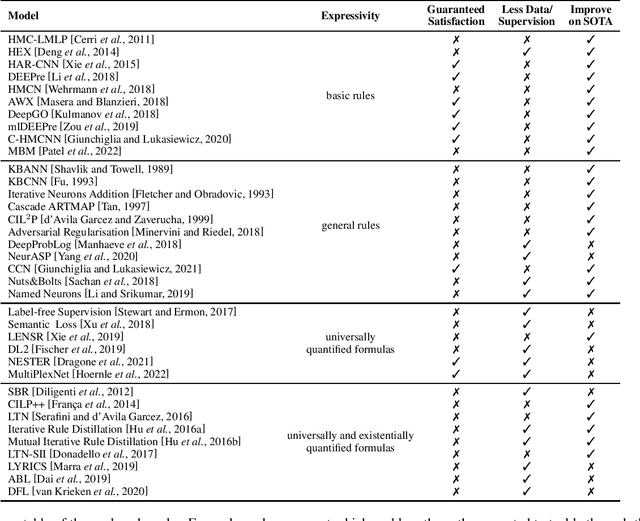
In recent years, there has been an increasing interest in exploiting logically specified background knowledge in order to obtain neural models (i) with a better performance, (ii) able to learn from less data, and/or (iii) guaranteed to be compliant with the background knowledge itself, e.g., for safety-critical applications. In this survey, we retrace such works and categorize them based on (i) the logical language that they use to express the background knowledge and (ii) the goals that they achieve.
Predictive Coding: Towards a Future of Deep Learning beyond Backpropagation?
Feb 18, 2022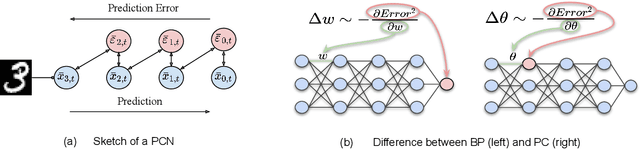
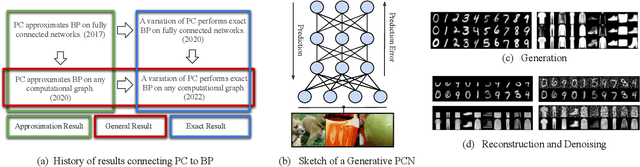


The backpropagation of error algorithm used to train deep neural networks has been fundamental to the successes of deep learning. However, it requires sequential backward updates and non-local computations, which make it challenging to parallelize at scale and is unlike how learning works in the brain. Neuroscience-inspired learning algorithms, however, such as \emph{predictive coding}, which utilize local learning, have the potential to overcome these limitations and advance beyond current deep learning technologies. While predictive coding originated in theoretical neuroscience as a model of information processing in the cortex, recent work has developed the idea into a general-purpose algorithm able to train neural networks using only local computations. In this survey, we review works that have contributed to this perspective and demonstrate the close theoretical connections between predictive coding and backpropagation, as well as works that highlight the multiple advantages of using predictive coding models over backpropagation-trained neural networks. Specifically, we show the substantially greater flexibility of predictive coding networks against equivalent deep neural networks, which can function as classifiers, generators, and associative memories simultaneously, and can be defined on arbitrary graph topologies. Finally, we review direct benchmarks of predictive coding networks on machine learning classification tasks, as well as its close connections to control theory and applications in robotics.