 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcitation-based Voice Quality Analysis and Modification
Jan 02, 2020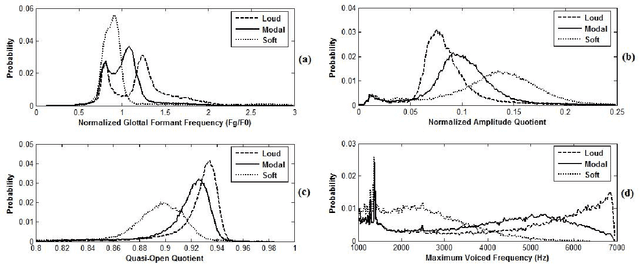
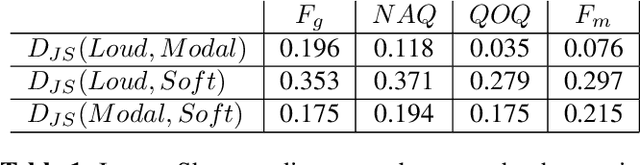
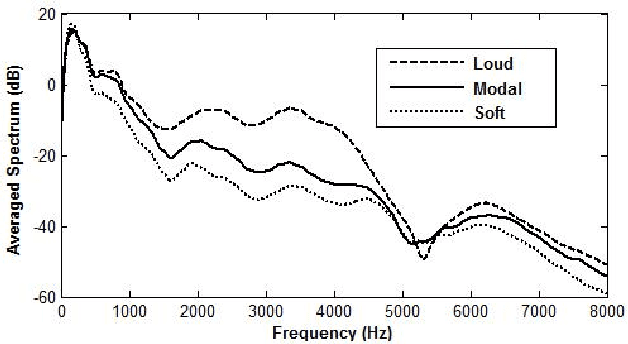

This paper investigates the differences occuring in the excitation for different voice qualities. Its goal is two-fold. First a large corpus containing three voice qualities (modal, soft and loud) uttered by the same speaker is analyzed and significant differences in characteristics extracted from the excitation are observed. Secondly rules of modification derived from the analysis are used to build a voice quality transformation system applied as a post-process to HMM-based speech synthesis. The system is shown to effectively achieve the transformations while maintaining the delivered quality.
Eigenresiduals for improved Parametric Speech Synthesis
Jan 02, 2020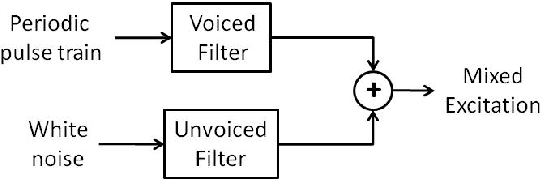
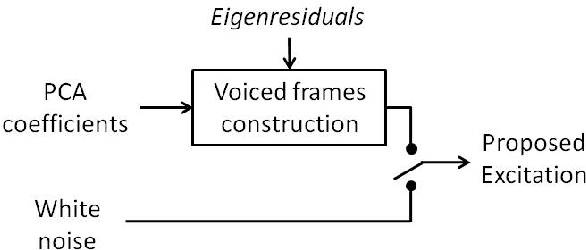
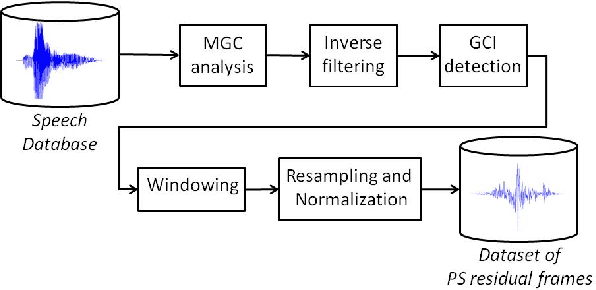
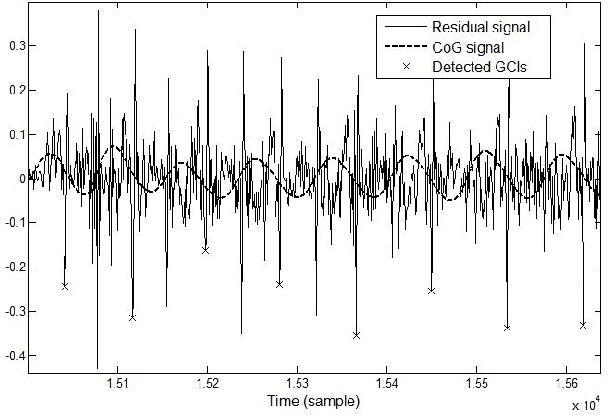
Statistical parametric speech synthesizers have recently shown their ability to produce natural-sounding and flexible voices. Unfortunately the delivered quality suffers from a typical buzziness due to the fact that speech is vocoded. This paper proposes a new excitation model in order to reduce this undesirable effect. This model is based on the decomposition of pitch-synchronous residual frames on an orthonormal basis obtained by Principal Component Analysis. This basis contains a limited number of eigenresiduals and is computed on a relatively small speech database. A stream of PCA-based coefficients is added to our HMM-based synthesizer and allows to generate the voiced excitation during the synthesis. An improvement compared to the traditional excitation is reported while the synthesis engine footprint remains under about 1Mb.
A Comparative Evaluation of Pitch Modification Techniques
Jan 02, 2020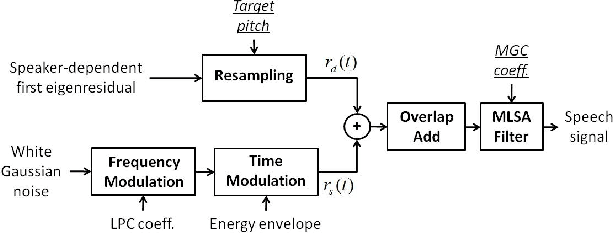
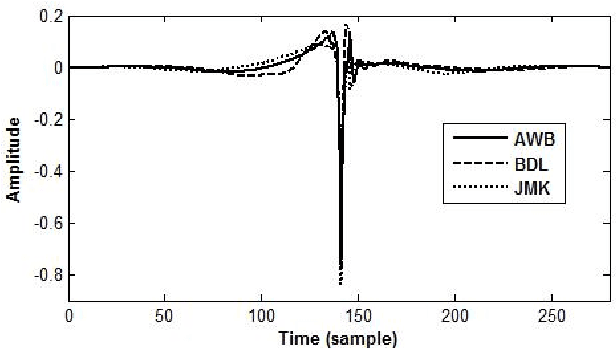
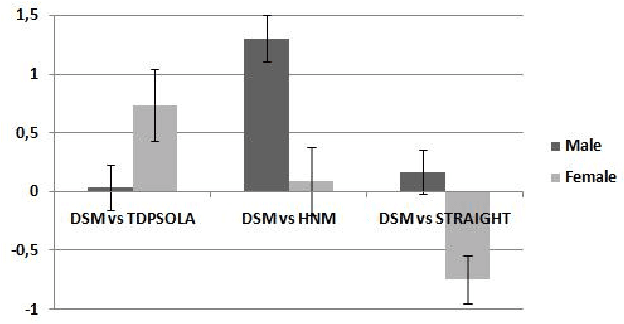
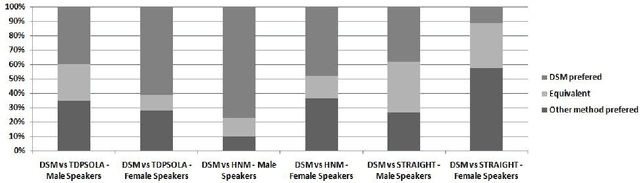
This paper addresses the problem of pitch modification, as an important module for an efficient voice transformation system. The Deterministic plus Stochastic Model of the residual signal we proposed in a previous work is compared to TDPSOLA, HNM and STRAIGHT. The four methods are compared through an important subjective test. The influence of the speaker gender and of the pitch modification ratio is analyzed. Despite its higher compression level, the DSM technique is shown to give similar or better results than other methods, especially for male speakers and important ratios of modification. The DSM turns out to be only outperformed by STRAIGHT for female voices.
Using a Pitch-Synchronous Residual Codebook for Hybrid HMM/Frame Selection Speech Synthesis
Dec 30, 2019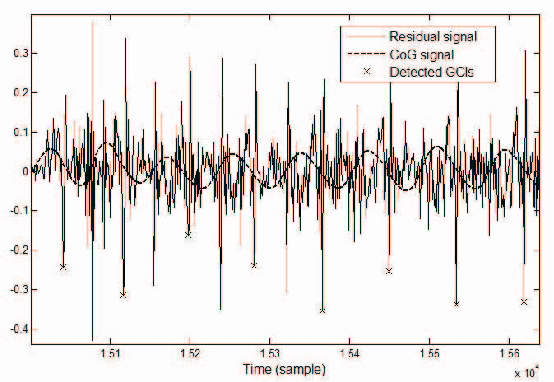
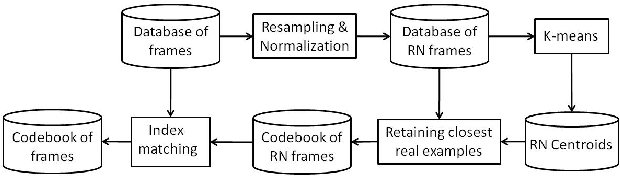
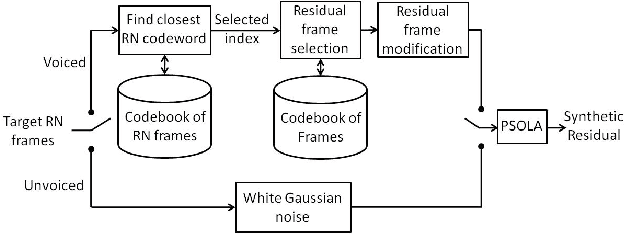
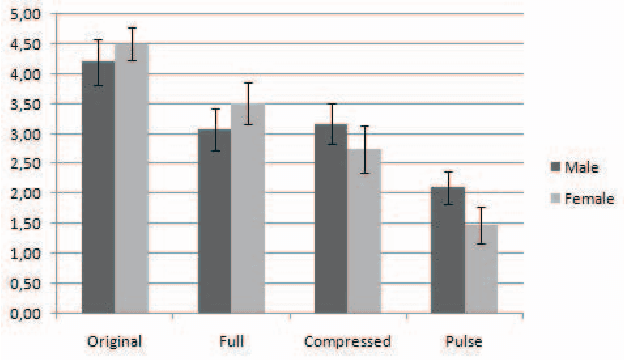
This paper proposes a method to improve the quality delivered by statistical parametric speech synthesizers. For this, we use a codebook of pitch-synchronous residual frames, so as to construct a more realistic source signal. First a limited codebook of typical excitations is built from some training database. During the synthesis part, HMMs are used to generate filter and source coefficients. The latter coefficients contain both the pitch and a compact representation of target residual frames. The source signal is obtained by concatenating excitation frames picked up from the codebook, based on a selection criterion and taking target residual coefficients as input. Subjective results show a relevant improvement compared to the basic technique.
Causal-Anticausal Decomposition of Speech using Complex Cepstrum for Glottal Source Estimation
Dec 30, 2019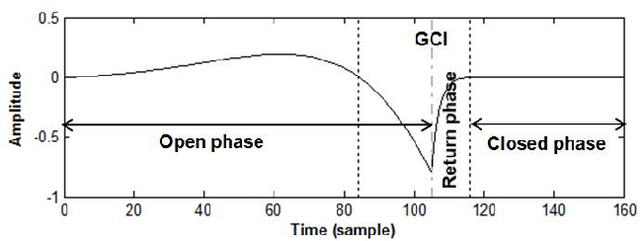
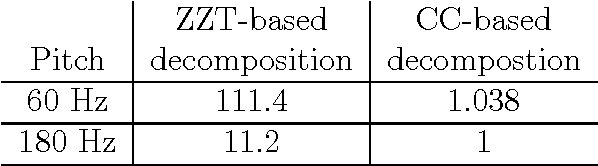
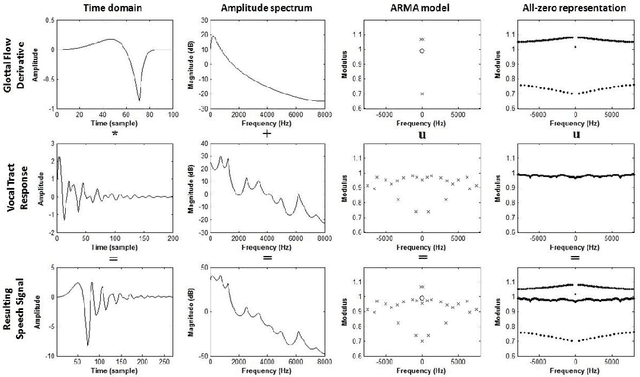

Complex cepstrum is known in the literature for linearly separating causal and anticausal components. Relying on advances achieved by the Zeros of the Z-Transform (ZZT) technique, we here investigate the possibility of using complex cepstrum for glottal flow estimation on a large-scale database. Via a systematic study of the windowing effects on the deconvolution quality, we show that the complex cepstrum causal-anticausal decomposition can be effectively used for glottal flow estimation when specific windowing criteria are met. It is also shown that this complex cepstral decomposition gives similar glottal estimates as obtained with the ZZT method. However, as complex cepstrum uses FFT operations instead of requiring the factoring of high-degree polynomials, the method benefits from a much higher speed. Finally in our tests on a large corpus of real expressive speech, we show that the proposed method has the potential to be used for voice quality analysis.
Glottal Source Processing: from Analysis to Applications
Dec 29, 2019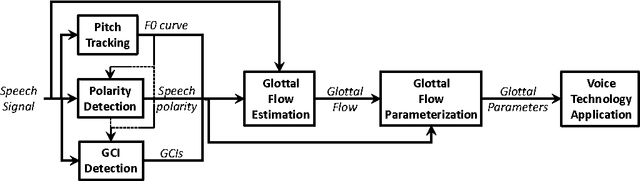
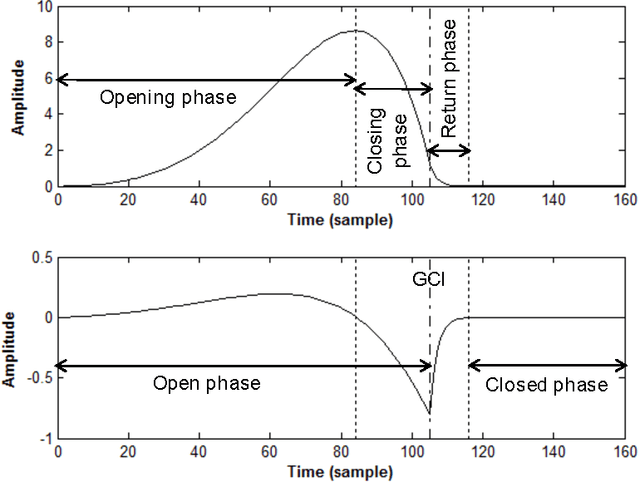
The great majority of current voice technology applications relies on acoustic features characterizing the vocal tract response, such as the widely used MFCC of LPC parameters. Nonetheless, the airflow passing through the vocal folds, and called glottal flow, is expected to exhibit a relevant complementarity. Unfortunately, glottal analysis from speech recordings requires specific and more complex processing operations, which explains why it has been generally avoided. This review gives a general overview of techniques which have been designed for glottal source processing. Starting from fundamental analysis tools of pitch tracking, glottal closure instant detection, glottal flow estimation and modelling, this paper then highlights how these solutions can be properly integrated within various voice technology applications.
Complex Cepstrum-based Decomposition of Speech for Glottal Source Estimation
Dec 29, 2019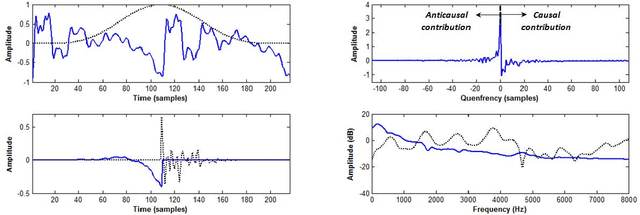
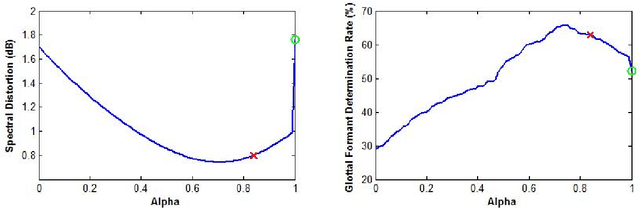
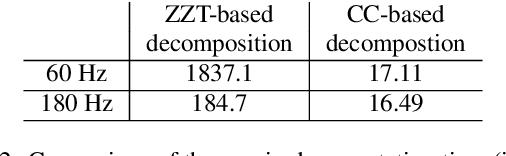
Homomorphic analysis is a well-known method for the separation of non-linearly combined signals. More particularly, the use of complex cepstrum for source-tract deconvolution has been discussed in various articles. However there exists no study which proposes a glottal flow estimation methodology based on cepstrum and reports effective results. In this paper, we show that complex cepstrum can be effectively used for glottal flow estimation by separating the causal and anticausal components of a windowed speech signal as done by the Zeros of the Z-Transform (ZZT) decomposition. Based on exactly the same principles presented for ZZT decomposition, windowing should be applied such that the windowed speech signals exhibit mixed-phase characteristics which conform the speech production model that the anticausal component is mainly due to the glottal flow open phase. The advantage of the complex cepstrum-based approach compared to the ZZT decomposition is its much higher speed.
The Deterministic plus Stochastic Model of the Residual Signal and its Applications
Dec 29, 2019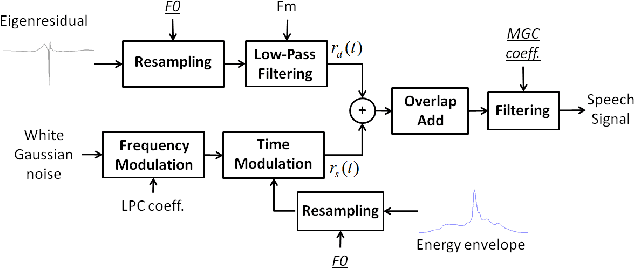
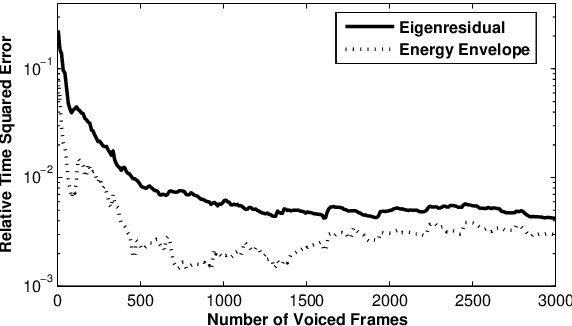
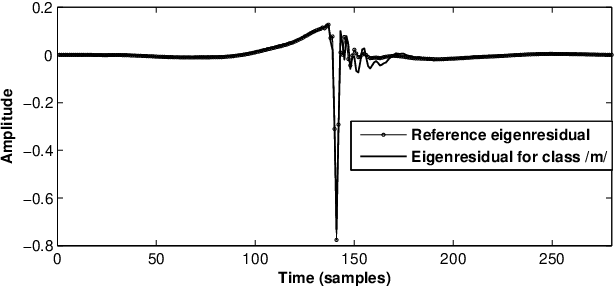
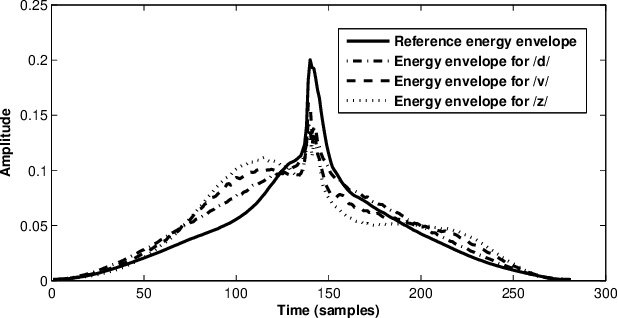
The modeling of speech production often relies on a source-filter approach. Although methods parameterizing the filter have nowadays reached a certain maturity, there is still a lot to be gained for several speech processing applications in finding an appropriate excitation model. This manuscript presents a Deterministic plus Stochastic Model (DSM) of the residual signal. The DSM consists of two contributions acting in two distinct spectral bands delimited by a maximum voiced frequency. Both components are extracted from an analysis performed on a speaker-dependent dataset of pitch-synchronous residual frames. The deterministic part models the low-frequency contents and arises from an orthonormal decomposition of these frames. As for the stochastic component, it is a high-frequency noise modulated both in time and frequency. Some interesting phonetic and computational properties of the DSM are also highlighted. The applicability of the DSM in two fields of speech processing is then studied. First, it is shown that incorporating the DSM vocoder in HMM-based speech synthesis enhances the delivered quality. The proposed approach turns out to significantly outperform the traditional pulse excitation and provides a quality equivalent to STRAIGHT. In a second application, the potential of glottal signatures derived from the proposed DSM is investigated for speaker identification purpose. Interestingly, these signatures are shown to lead to better recognition rates than other glottal-based methods.
A Deterministic plus Stochastic Model of the Residual Signal for Improved Parametric Speech Synthesis
Dec 29, 2019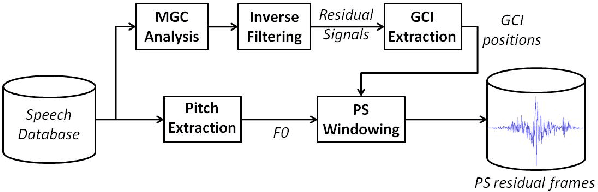
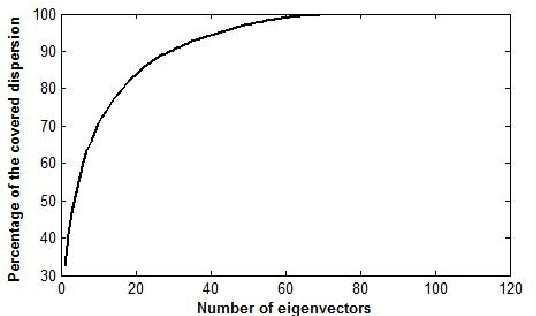
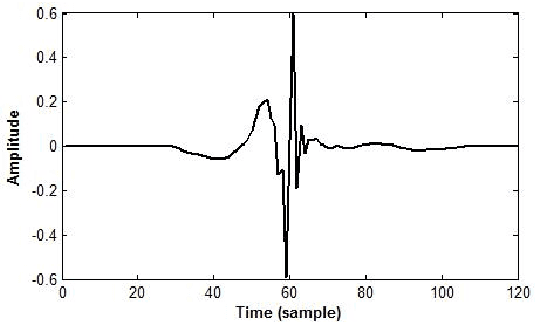
Speech generated by parametric synthesizers generally suffers from a typical buzziness, similar to what was encountered in old LPC-like vocoders. In order to alleviate this problem, a more suited modeling of the excitation should be adopted. For this, we hereby propose an adaptation of the Deterministic plus Stochastic Model (DSM) for the residual. In this model, the excitation is divided into two distinct spectral bands delimited by the maximum voiced frequency. The deterministic part concerns the low-frequency contents and consists of a decomposition of pitch-synchronous residual frames on an orthonormal basis obtained by Principal Component Analysis. The stochastic component is a high-pass filtered noise whose time structure is modulated by an energy-envelope, similarly to what is done in the Harmonic plus Noise Model (HNM). The proposed residual model is integrated within a HMM-based speech synthesizer and is compared to the traditional excitation through a subjective test. Results show a significative improvement for both male and female voices. In addition the proposed model requires few computational load and memory, which is essential for its integration in commercial applications.
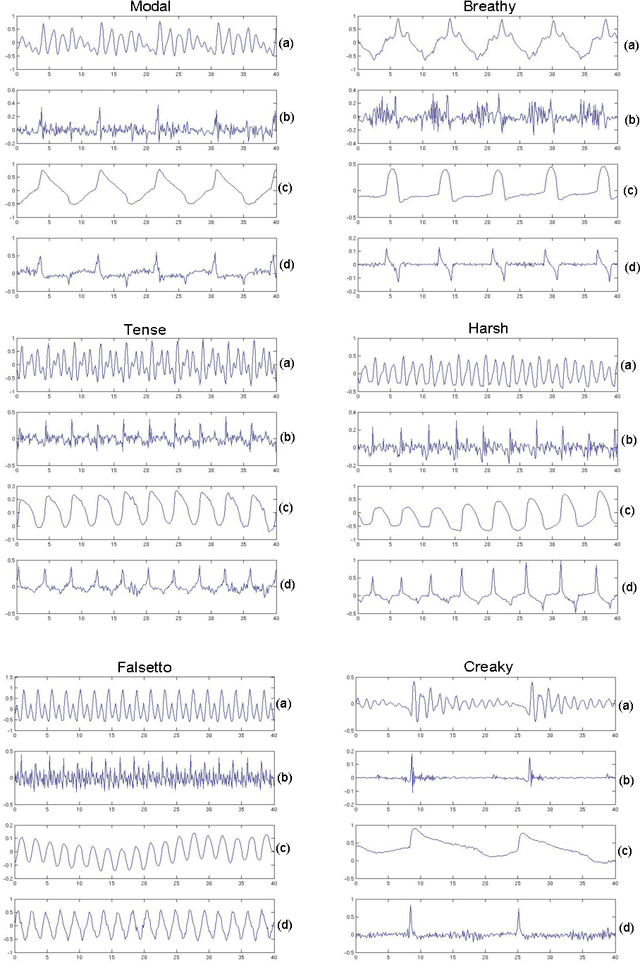
A Comparative Study of Glottal Source Estimation Techniques
Dec 28, 2019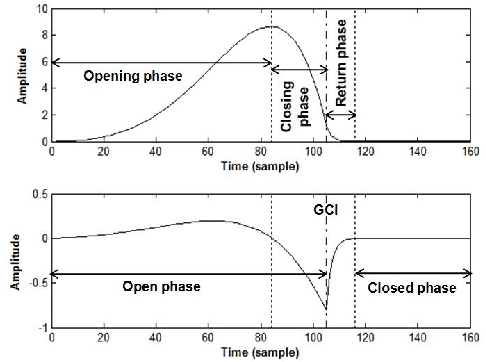

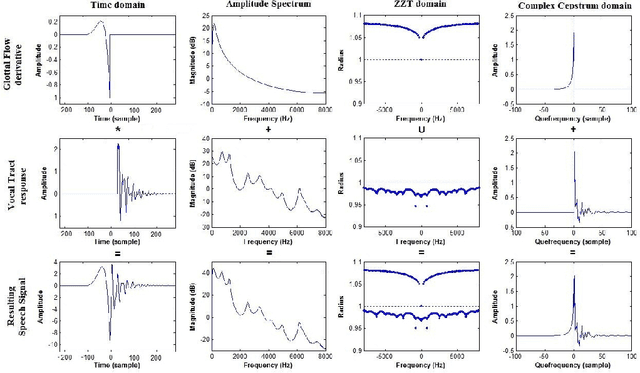
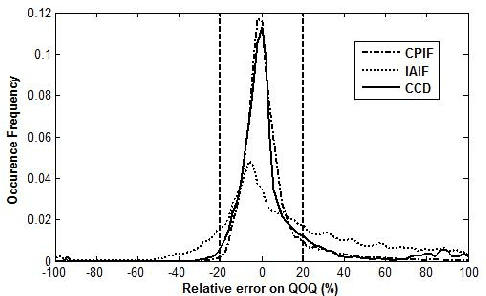
Source-tract decomposition (or glottal flow estimation) is one of the basic problems of speech processing. For this, several techniques have been proposed in the literature. However studies comparing different approaches are almost nonexistent. Besides, experiments have been systematically performed either on synthetic speech or on sustained vowels. In this study we compare three of the main representative state-of-the-art methods of glottal flow estimation: closed-phase inverse filtering, iterative and adaptive inverse filtering, and mixed-phase decomposition. These techniques are first submitted to an objective assessment test on synthetic speech signals. Their sensitivity to various factors affecting the estimation quality, as well as their robustness to noise are studied. In a second experiment, their ability to label voice quality (tensed, modal, soft) is studied on a large corpus of real connected speech. It is shown that changes of voice quality are reflected by significant modifications in glottal feature distributions. Techniques based on the mixed-phase decomposition and on a closed-phase inverse filtering process turn out to give the best results on both clean synthetic and real speech signals. On the other hand, iterative and adaptive inverse filtering is recommended in noisy environments for its high robustness.