 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Impact of CU: A Systematic Literature Review
Nov 10, 2025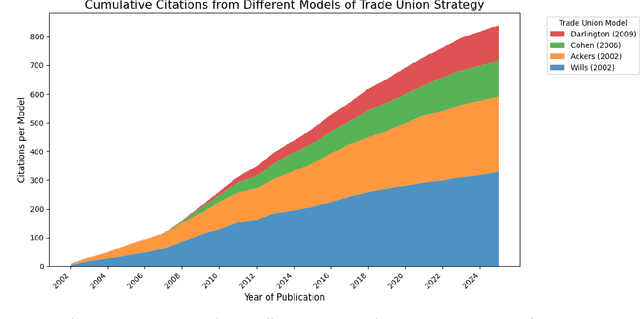
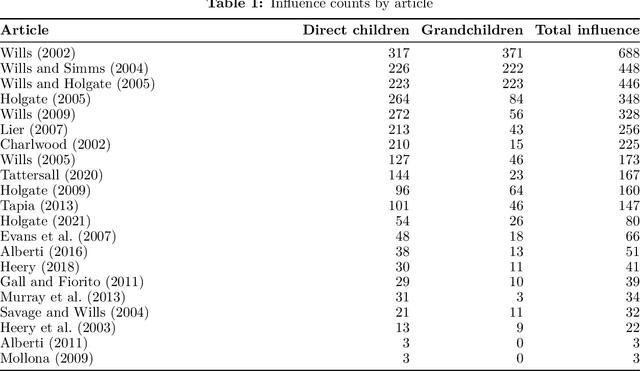
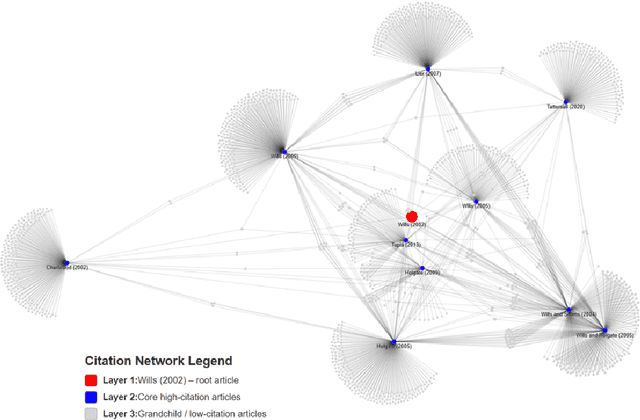
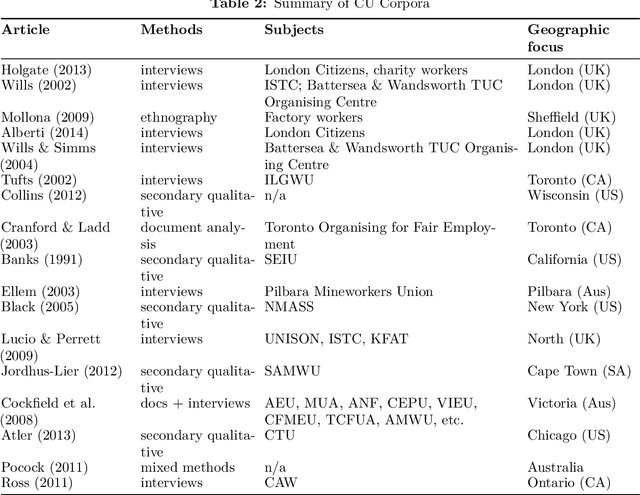
Community Unionism has served as a pivotal concept in debates on trade union renewal since the early 2000s, yet its theoretical coherence and political significance remain unresolved. This article investigates why CU has gained such prominence -- not by testing its efficacy, but by mapping how it is constructed, cited, and contested across the scholarly literature. Using two complementary systematic approaches -- a citation network analysis of 114 documents and a thematic review of 18 core CU case studies -- I examine how CU functions as both an empirical descriptor and a normative ideal. The analysis reveals CU's dual genealogy: positioned by British scholars as an indigenous return to historic rank-and-file practices, yet structurally aligned with transnational social movement unionism. Thematic coding shows near-universal emphasis on coalition-building and alliances, but deep ambivalence toward class politics. This tension suggests CU's significance lies less in operationalising a new union model, and more in managing contradictions -- between workplace and community, leadership and rank-and-file, reform and radicalism -- within a shrinking labour movement.
Beyond the Black Box: Integrating Lexical and Semantic Methods in Quantitative Discourse Analysis with BERTopic
Aug 26, 2025Quantitative Discourse Analysis has seen growing adoption with the rise of Large Language Models and computational tools. However, reliance on black box software such as MAXQDA and NVivo risks undermining methodological transparency and alignment with research goals. This paper presents a hybrid, transparent framework for QDA that combines lexical and semantic methods to enable triangulation, reproducibility, and interpretability. Drawing from a case study in historical political discourse, we demonstrate how custom Python pipelines using NLTK, spaCy, and Sentence Transformers allow fine-grained control over preprocessing, lemmatisation, and embedding generation. We further detail our iterative BERTopic modelling process, incorporating UMAP dimensionality reduction, HDBSCAN clustering, and c-TF-IDF keyword extraction, optimised through parameter tuning and multiple runs to enhance topic coherence and coverage. By juxtaposing precise lexical searches with context-aware semantic clustering, we argue for a multi-layered approach that mitigates the limitations of either method in isolation. Our workflow underscores the importance of code-level transparency, researcher agency, and methodological triangulation in computational discourse studies. Code and supplementary materials are available via GitHub.