 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlottal source estimation robustness: A comparison of sensitivity of voice source estimation techniques
May 24, 2020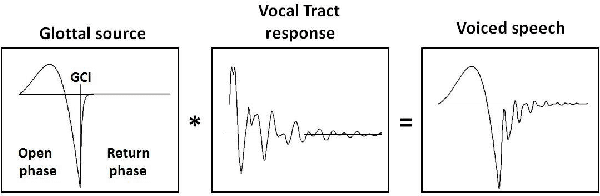

This paper addresses the problem of estimating the voice source directly from speech waveforms. A novel principle based on Anticausality Dominated Regions (ACDR) is used to estimate the glottal open phase. This technique is compared to two other state-of-the-art well-known methods, namely the Zeros of the Z-Transform (ZZT) and the Iterative Adaptive Inverse Filtering (IAIF) algorithms. Decomposition quality is assessed on synthetic signals through two objective measures: the spectral distortion and a glottal formant determination rate. Technique robustness is tested by analyzing the influence of noise and Glottal Closure Instant (GCI) location errors. Besides impacts of the fundamental frequency and the first formant on the performance are evaluated. Our proposed approach shows significant improvement in robustness, which could be of a great interest when decomposing real speech.
Oscillating Statistical Moments for Speech Polarity Detection
May 16, 2020
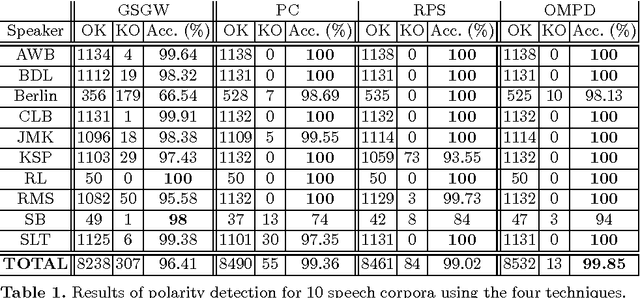
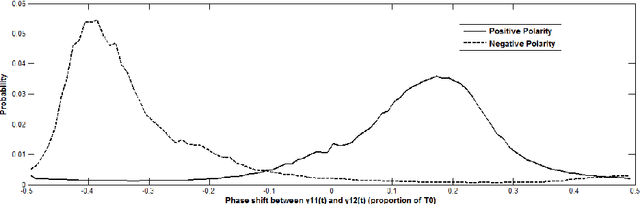
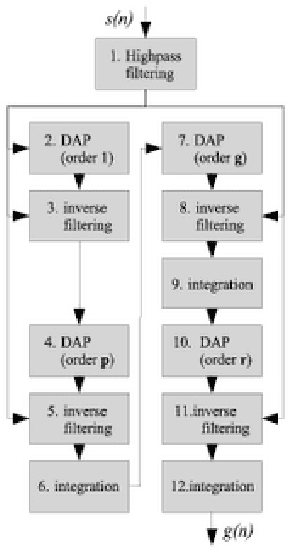
An inversion of the speech polarity may have a dramatic detrimental effect on the performance of various techniques of speech processing. An automatic method for determining the speech polarity (which is dependent upon the recording setup) is thus required as a preliminary step for ensuring the well-behaviour of such techniques. This paper proposes a new approach of polarity detection relying on oscillating statistical moments. These moments have the property to oscillate at the local fundamental frequency and to exhibit a phase shift which depends on the speech polarity. This dependency stems from the introduction of non-linearity or higher-order statistics in the moment calculation. The resulting method is shown on 10 speech corpora to provide a substantial improvement compared to state-of-the-art techniques.
Glottal Source Estimation using an Automatic Chirp Decomposition
May 16, 2020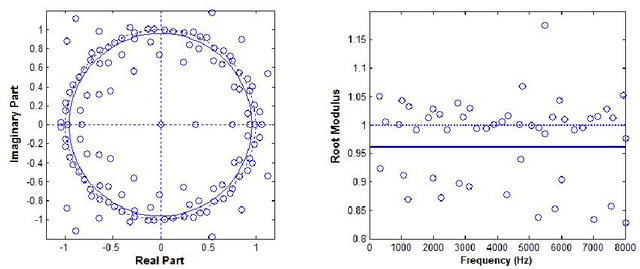

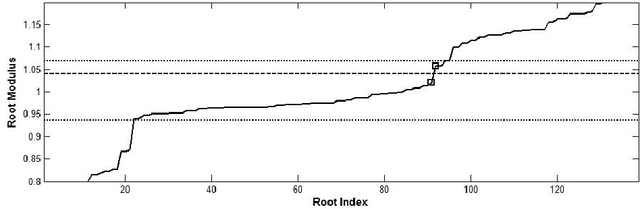
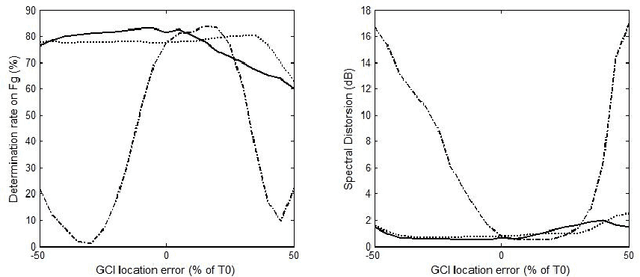
In a previous work, we showed that the glottal source can be estimated from speech signals by computing the Zeros of the Z-Transform (ZZT). Decomposition was achieved by separating the roots inside (causal contribution) and outside (anticausal contribution) the unit circle. In order to guarantee a correct deconvolution, time alignment on the Glottal Closure Instants (GCIs) was shown to be essential. This paper extends the formalism of ZZT by evaluating the Z-transform on a contour possibly different from the unit circle. A method is proposed for determining automatically this contour by inspecting the root distribution. The derived Zeros of the Chirp Z-Transform (ZCZT)-based technique turns out to be much more robust to GCI location errors.
Chirp Complex Cepstrum-based Decomposition for Asynchronous Glottal Analysis
May 10, 2020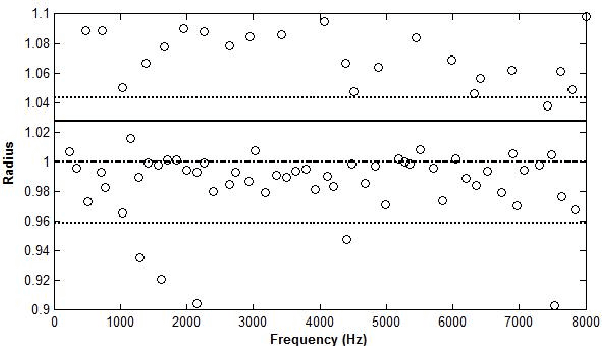
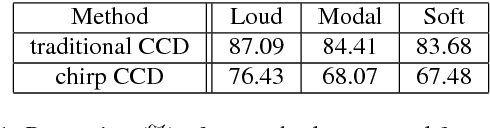
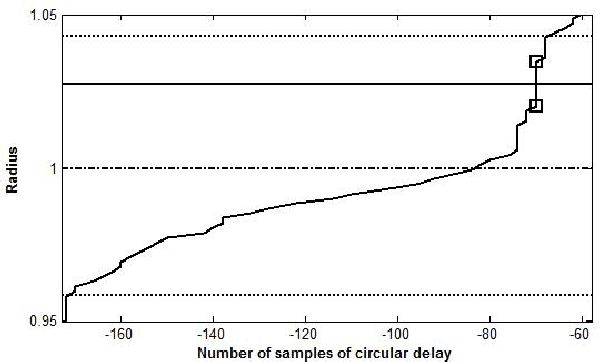
It was recently shown that complex cepstrum can be effectively used for glottal flow estimation by separating the causal and anticausal components of speech. In order to guarantee a correct estimation, some constraints on the window have been derived. Among these, the window has to be synchronized on a Glottal Closure Instant. This paper proposes an extension of the complex cepstrum-based decomposition by incorporating a chirp analysis. The resulting method is shown to give a reliable estimation of the glottal flow wherever the window is located. This technique is then suited for its integration in usual speech processing systems, which generally operate in an asynchronous way. Besides its potential for automatic voice quality analysis is highlighted.
On the Mutual Information between Source and Filter Contributions for Voice Pathology Detection
Jan 02, 2020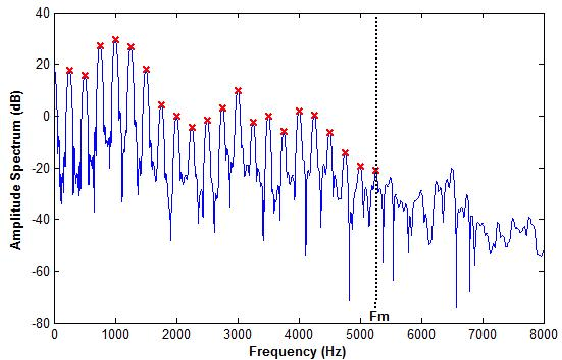
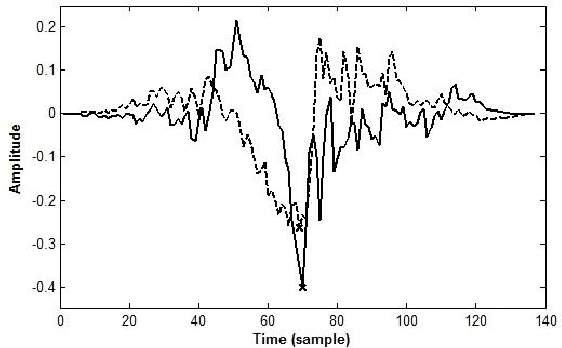
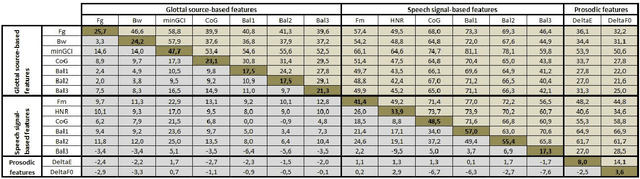
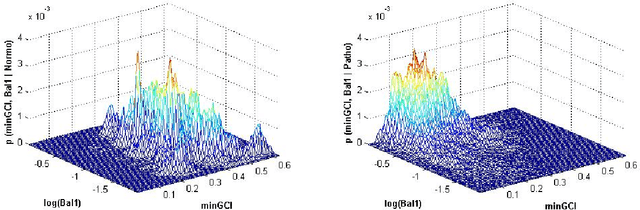
This paper addresses the problem of automatic detection of voice pathologies directly from the speech signal. For this, we investigate the use of the glottal source estimation as a means to detect voice disorders. Three sets of features are proposed, depending on whether they are related to the speech or the glottal signal, or to prosody. The relevancy of these features is assessed through mutual information-based measures. This allows an intuitive interpretation in terms of discrimation power and redundancy between the features, independently of any subsequent classifier. It is discussed which characteristics are interestingly informative or complementary for detecting voice pathologies.
Phase-based Information for Voice Pathology Detection
Jan 02, 2020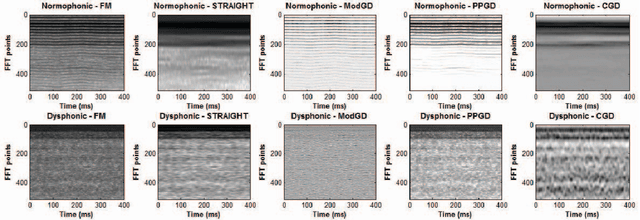


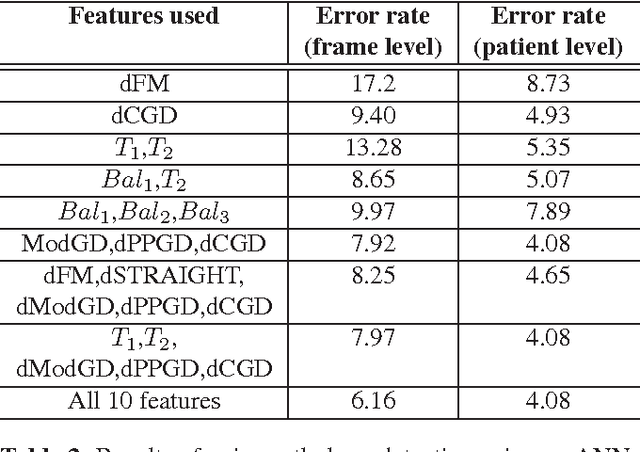
In most current approaches of speech processing, information is extracted from the magnitude spectrum. However recent perceptual studies have underlined the importance of the phase component. The goal of this paper is to investigate the potential of using phase-based features for automatically detecting voice disorders. It is shown that group delay functions are appropriate for characterizing irregularities in the phonation. Besides the respect of the mixed-phase model of speech is discussed. The proposed phase-based features are evaluated and compared to other parameters derived from the magnitude spectrum. Both streams are shown to be interestingly complementary. Furthermore phase-based features turn out to convey a great amount of relevant information, leading to high discrimination performance.
Excitation-based Voice Quality Analysis and Modification
Jan 02, 2020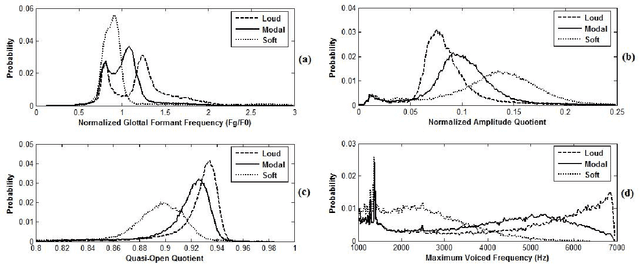
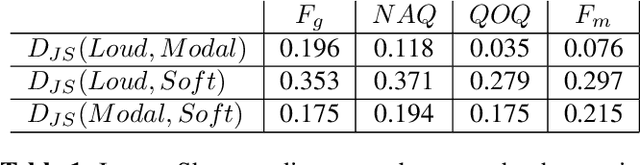
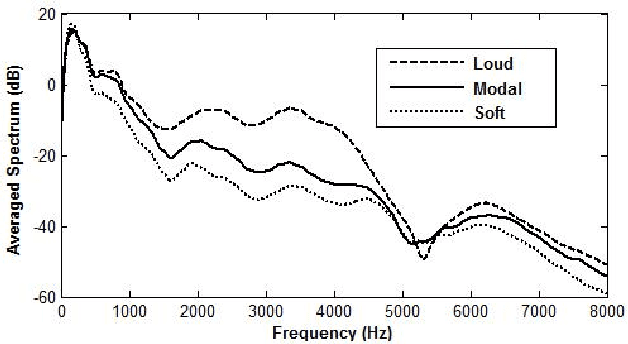

This paper investigates the differences occuring in the excitation for different voice qualities. Its goal is two-fold. First a large corpus containing three voice qualities (modal, soft and loud) uttered by the same speaker is analyzed and significant differences in characteristics extracted from the excitation are observed. Secondly rules of modification derived from the analysis are used to build a voice quality transformation system applied as a post-process to HMM-based speech synthesis. The system is shown to effectively achieve the transformations while maintaining the delivered quality.
Eigenresiduals for improved Parametric Speech Synthesis
Jan 02, 2020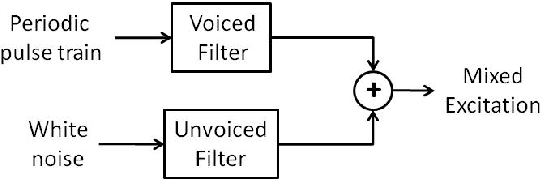
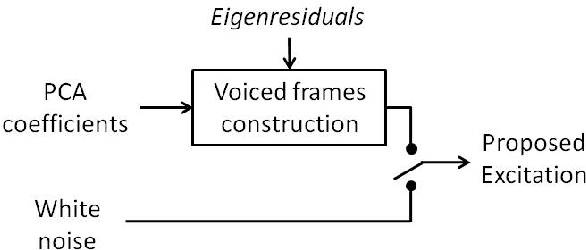
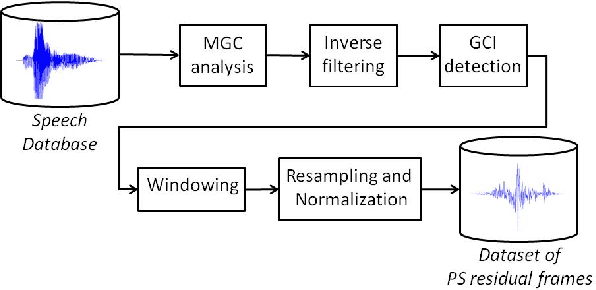
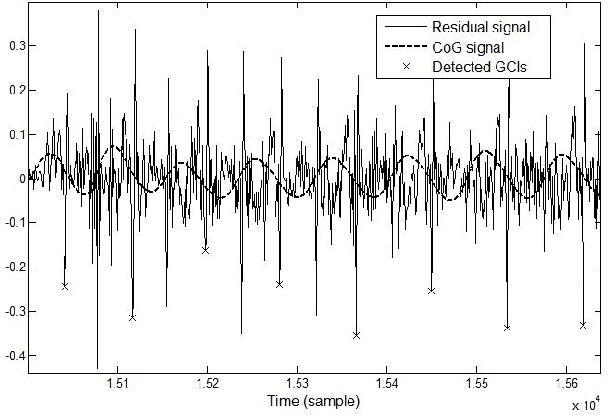
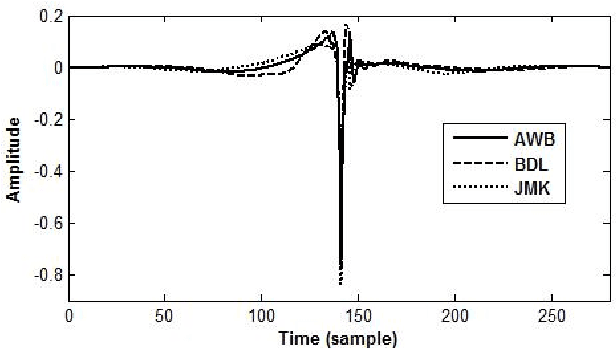
Statistical parametric speech synthesizers have recently shown their ability to produce natural-sounding and flexible voices. Unfortunately the delivered quality suffers from a typical buzziness due to the fact that speech is vocoded. This paper proposes a new excitation model in order to reduce this undesirable effect. This model is based on the decomposition of pitch-synchronous residual frames on an orthonormal basis obtained by Principal Component Analysis. This basis contains a limited number of eigenresiduals and is computed on a relatively small speech database. A stream of PCA-based coefficients is added to our HMM-based synthesizer and allows to generate the voiced excitation during the synthesis. An improvement compared to the traditional excitation is reported while the synthesis engine footprint remains under about 1Mb.
A Comparative Evaluation of Pitch Modification Techniques
Jan 02, 2020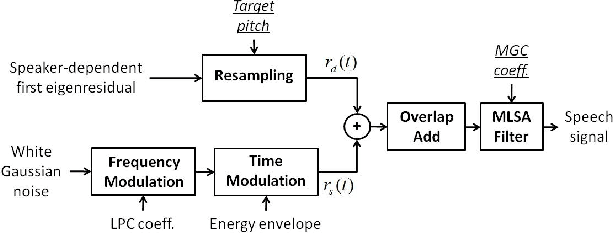
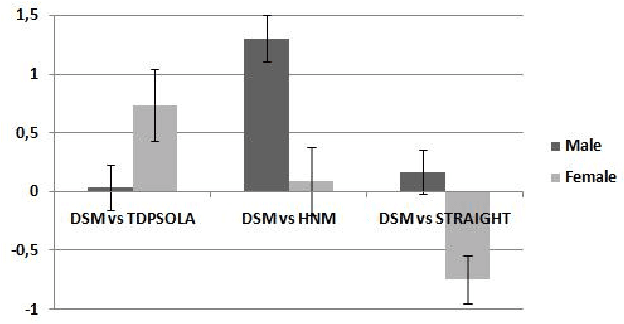
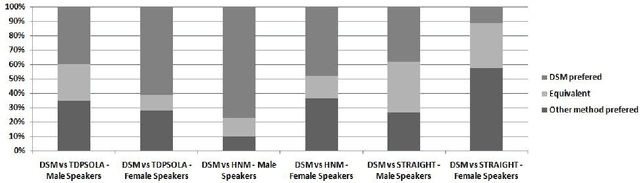
This paper addresses the problem of pitch modification, as an important module for an efficient voice transformation system. The Deterministic plus Stochastic Model of the residual signal we proposed in a previous work is compared to TDPSOLA, HNM and STRAIGHT. The four methods are compared through an important subjective test. The influence of the speaker gender and of the pitch modification ratio is analyzed. Despite its higher compression level, the DSM technique is shown to give similar or better results than other methods, especially for male speakers and important ratios of modification. The DSM turns out to be only outperformed by STRAIGHT for female voices.
Using a Pitch-Synchronous Residual Codebook for Hybrid HMM/Frame Selection Speech Synthesis
Dec 30, 2019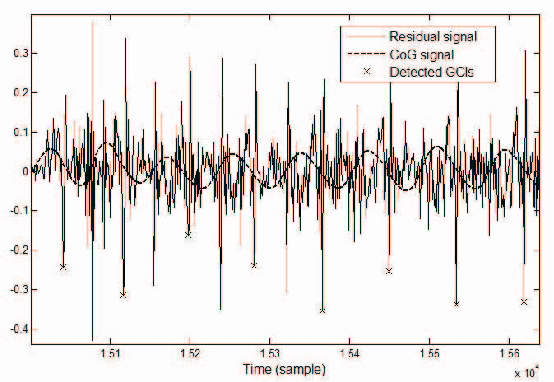
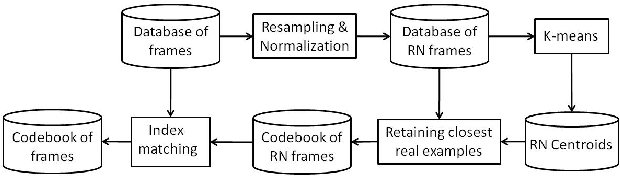
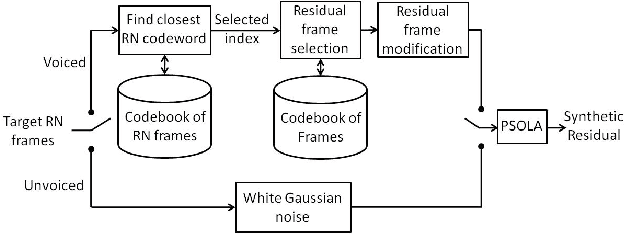
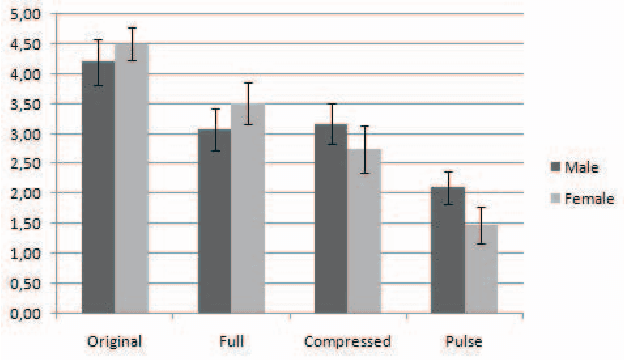
This paper proposes a method to improve the quality delivered by statistical parametric speech synthesizers. For this, we use a codebook of pitch-synchronous residual frames, so as to construct a more realistic source signal. First a limited codebook of typical excitations is built from some training database. During the synthesis part, HMMs are used to generate filter and source coefficients. The latter coefficients contain both the pitch and a compact representation of target residual frames. The source signal is obtained by concatenating excitation frames picked up from the codebook, based on a selection criterion and taking target residual coefficients as input. Subjective results show a relevant improvement compared to the basic technique.