 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Quality of a Synthesized Motion with the Fréchet Motion Distance
Apr 27, 2022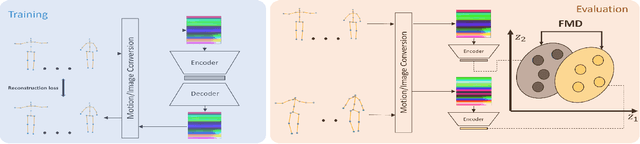

Evaluating the Quality of a Synthesized Motion with the Fr\'echet Motion Distance
Spatio-Temporal Analysis of Transformer based Architecture for Attention Estimation from EEG
Apr 04, 2022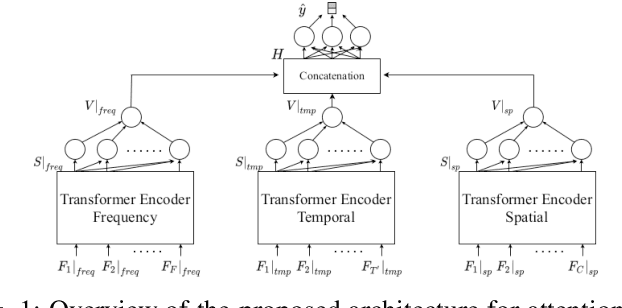
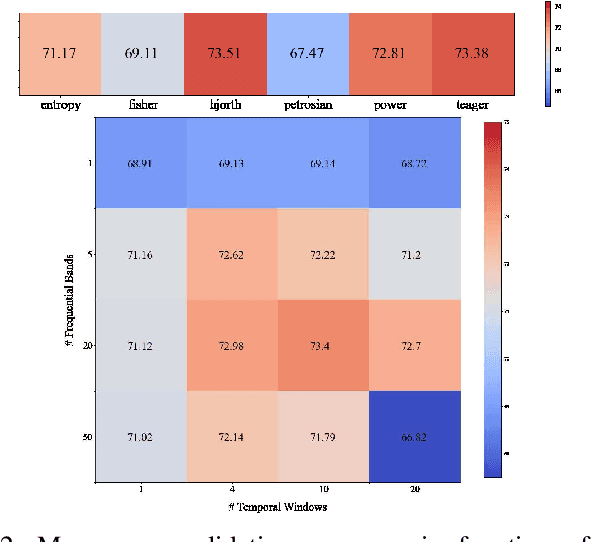
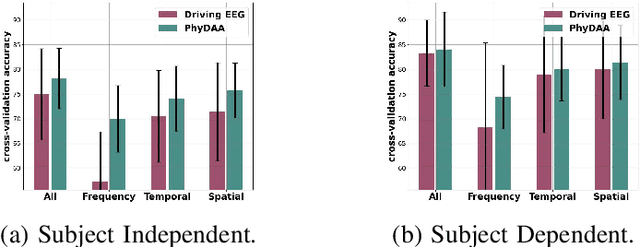
For many years now, understanding the brain mechanism has been a great research subject in many different fields. Brain signal processing and especially electroencephalogram (EEG) has recently known a growing interest both in academia and industry. One of the main examples is the increasing number of Brain-Computer Interfaces (BCI) aiming to link brains and computers. In this paper, we present a novel framework allowing us to retrieve the attention state, i.e degree of attention given to a specific task, from EEG signals. While previous methods often consider the spatial relationship in EEG through electrodes and process them in recurrent or convolutional based architecture, we propose here to also exploit the spatial and temporal information with a transformer-based network that has already shown its supremacy in many machine-learning (ML) related studies, e.g. machine translation. In addition to this novel architecture, an extensive study on the feature extraction methods, frequential bands and temporal windows length has also been carried out. The proposed network has been trained and validated on two public datasets and achieves higher results compared to state-of-the-art models. As well as proposing better results, the framework could be used in real applications, e.g. Attention Deficit Hyperactivity Disorder (ADHD) symptoms or vigilance during a driving assessment.
A Saliency based Feature Fusion Model for EEG Emotion Estimation
Jan 26, 2022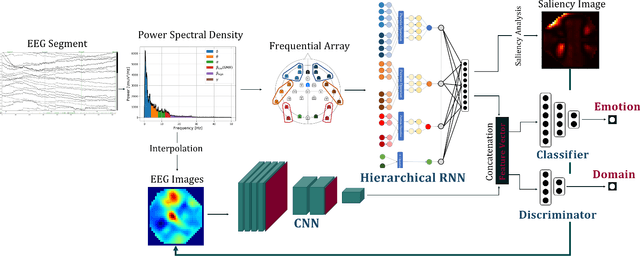

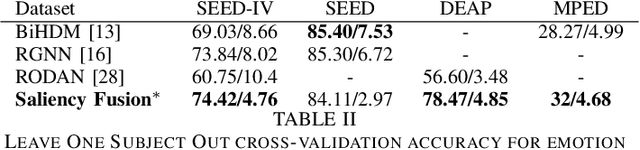
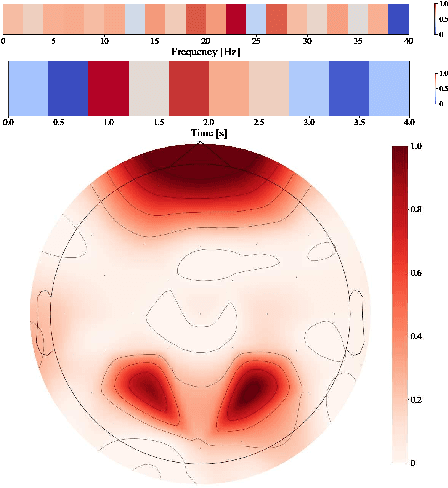
Among the different modalities to assess emotion, electroencephalogram (EEG), representing the electrical brain activity, achieved motivating results over the last decade. Emotion estimation from EEG could help in the diagnosis or rehabilitation of certain diseases. In this paper, we propose a dual model considering two different representations of EEG feature maps: 1) a sequential based representation of EEG band power, 2) an image-based representation of the feature vectors. We also propose an innovative method to combine the information based on a saliency analysis of the image-based model to promote joint learning of both model parts. The model has been evaluated on four publicly available datasets and achieves similar results to the state-of-the-art approaches. It outperforms results for two of the proposed datasets with a lower standard deviation that reflects higher stability. For sake of reproducibility, the codes and models proposed in this paper are available at https://github.com/VDelv/Emotion-EEG.
Towards Lightweight Neural Animation : Exploration of Neural Network Pruning in Mixture of Experts-based Animation Models
Jan 24, 2022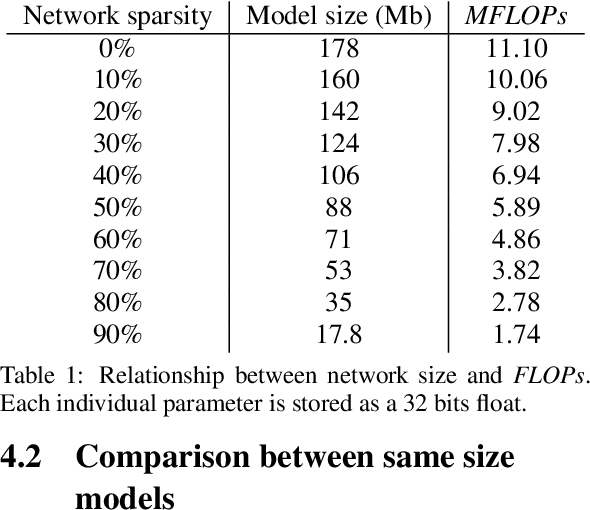
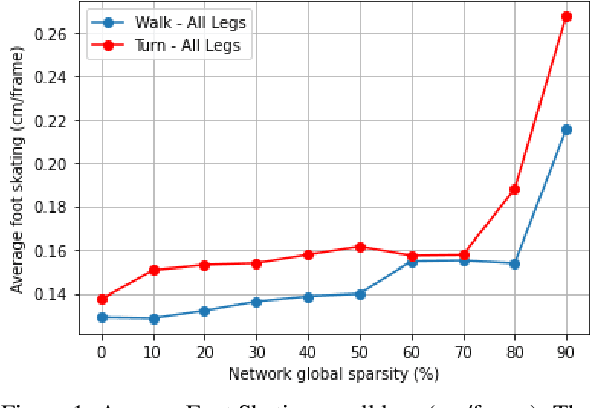


In the past few years, neural character animation has emerged and offered an automatic method for animating virtual characters. Their motion is synthesized by a neural network. Controlling this movement in real time with a user-defined control signal is also an important task in video games for example. Solutions based on fully-connected layers (MLPs) and Mixture-of-Experts (MoE) have given impressive results in generating and controlling various movements with close-range interactions between the environment and the virtual character. However, a major shortcoming of fully-connected layers is their computational and memory cost which may lead to sub-optimized solution. In this work, we apply pruning algorithms to compress an MLP- MoE neural network in the context of interactive character animation, which reduces its number of parameters and accelerates its computation time with a trade-off between this acceleration and the synthesized motion quality. This work demonstrates that, with the same number of experts and parameters, the pruned model produces less motion artifacts than the dense model and the learned high-level motion features are similar for both
Where Is My Mind ? Predicting Visual Attention from Brain Activity
Jan 11, 2022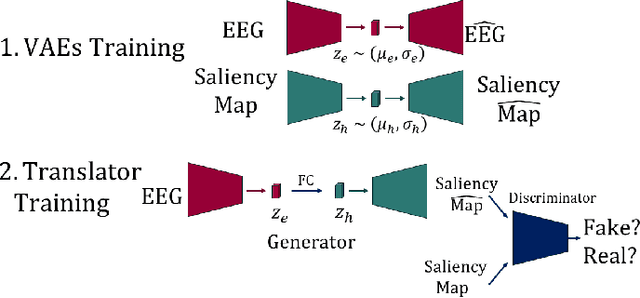
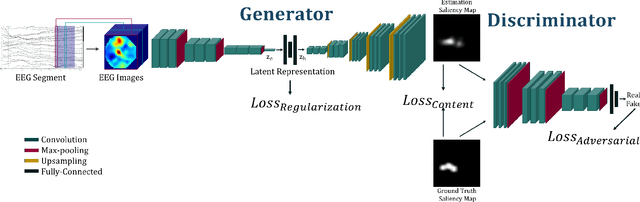

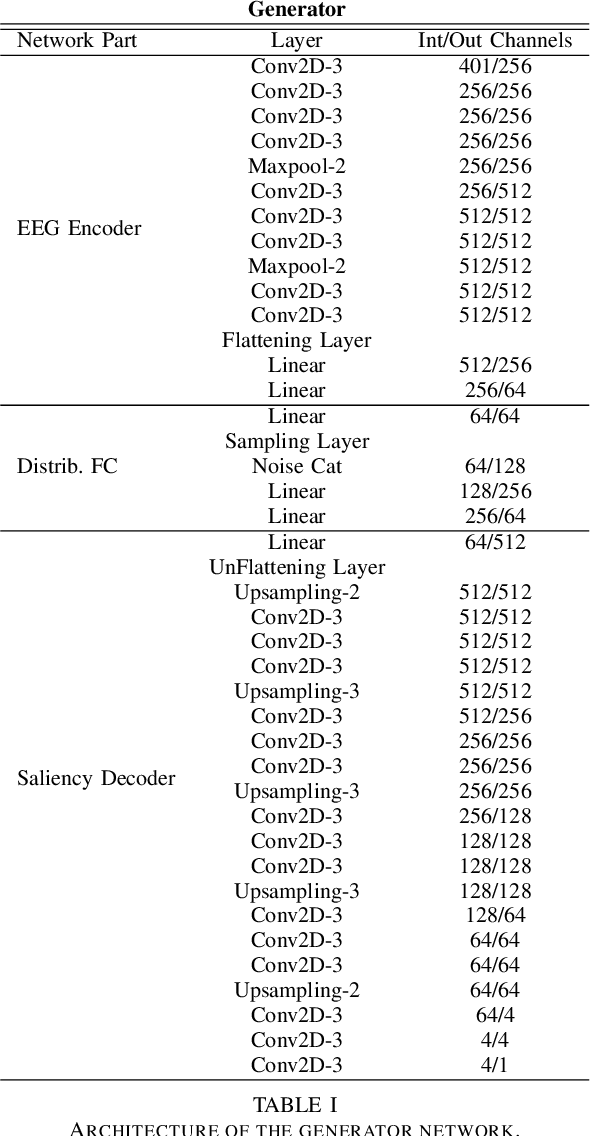
Visual attention estimation is an active field of research at the crossroads of different disciplines: computer vision, artificial intelligence and medicine. One of the most common approaches to estimate a saliency map representing attention is based on the observed images. In this paper, we show that visual attention can be retrieved from EEG acquisition. The results are comparable to traditional predictions from observed images, which is of great interest. For this purpose, a set of signals has been recorded and different models have been developed to study the relationship between visual attention and brain activity. The results are encouraging and comparable with other approaches estimating attention with other modalities. The codes and dataset considered in this paper have been made available at \url{https://figshare.com/s/3e353bd1c621962888ad} to promote research in the field.
Analysis and Assessment of Controllability of an Expressive Deep Learning-based TTS system
Mar 06, 2021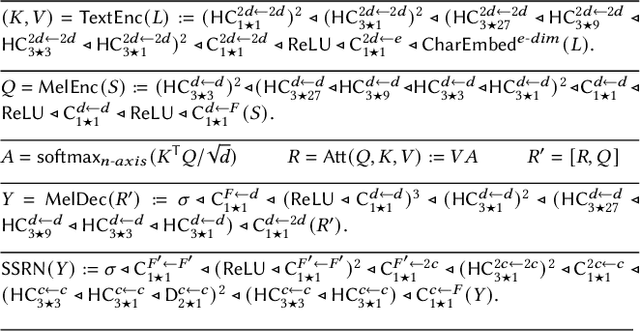


In this paper, we study the controllability of an Expressive TTS system trained on a dataset for a continuous control. The dataset is the Blizzard 2013 dataset based on audiobooks read by a female speaker containing a great variability in styles and expressiveness. Controllability is evaluated with both an objective and a subjective experiment. The objective assessment is based on a measure of correlation between acoustic features and the dimensions of the latent space representing expressiveness. The subjective assessment is based on a perceptual experiment in which users are shown an interface for Controllable Expressive TTS and asked to retrieve a synthetic utterance whose expressiveness subjectively corresponds to that a reference utterance.
ICE-Talk: an Interface for a Controllable Expressive Talking Machine
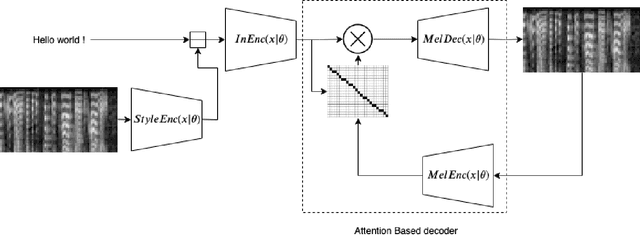
Aug 25, 2020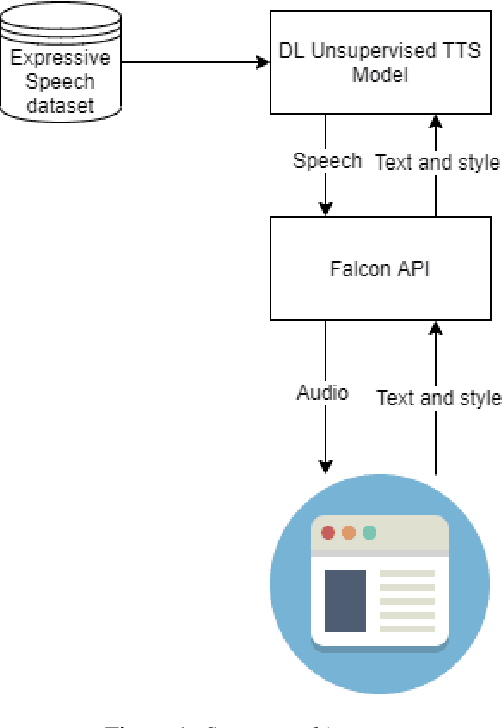
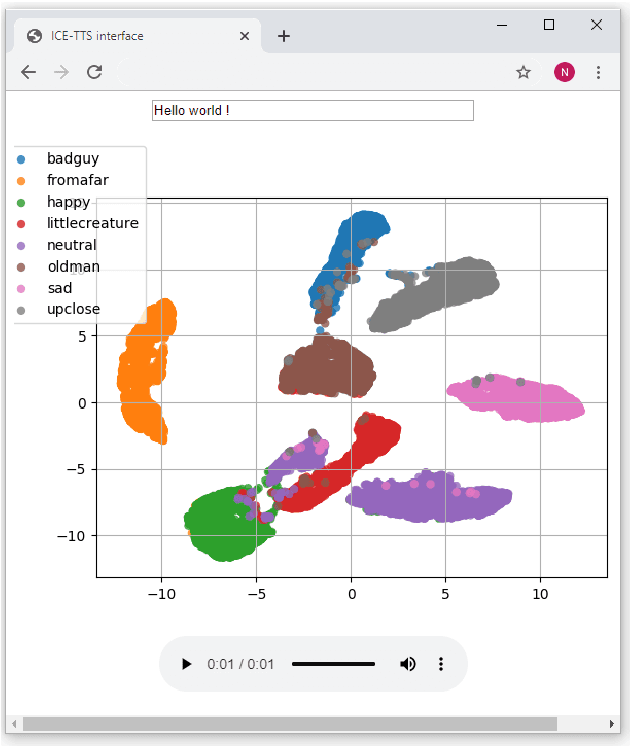
ICE-Talk is an open source web-based GUI that allows the use of a TTS system with controllable parameters via a text field and a clickable 2D plot. It enables the study of latent spaces for controllable TTS. Moreover it is implemented as a module that can be used as part of a Human-Agent interaction.
Laughter Synthesis: Combining Seq2seq modeling with Transfer Learning
Aug 20, 2020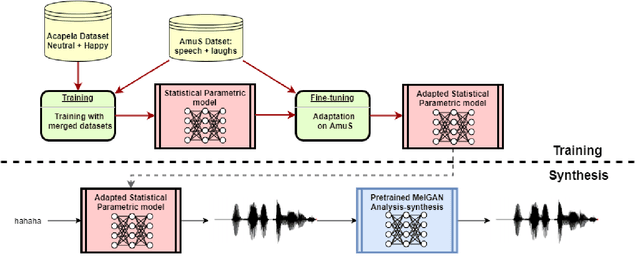
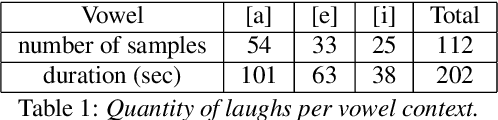
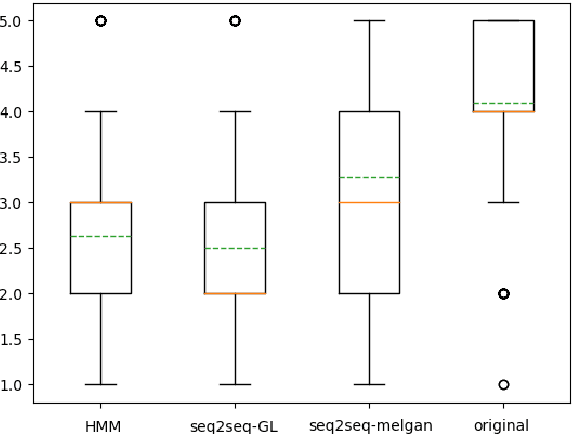
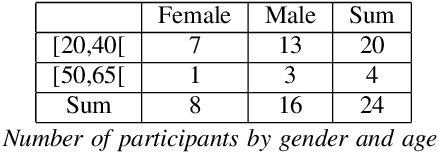
Despite the growing interest for expressive speech synthesis, synthesis of nonverbal expressions is an under-explored area. In this paper we propose an audio laughter synthesis system based on a sequence-to-sequence TTS synthesis system. We leverage transfer learning by training a deep learning model to learn to generate both speech and laughs from annotations. We evaluate our model with a listening test, comparing its performance to an HMM-based laughter synthesis one and assess that it reaches higher perceived naturalness. Our solution is a first step towards a TTS system that would be able to synthesize speech with a control on amusement level with laughter integration.
Parametric Representation for Singing Voice Synthesis: a Comparative Evaluation
Jun 07, 2020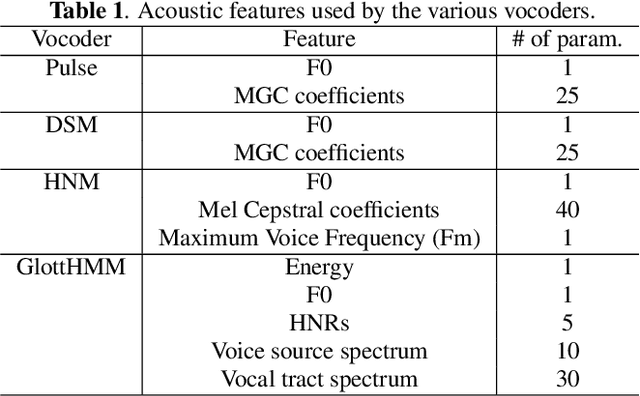
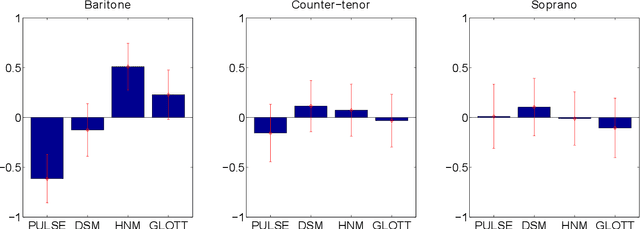
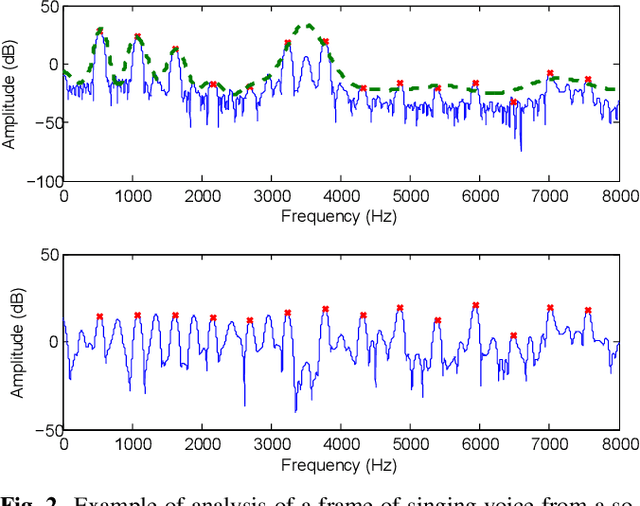
Various parametric representations have been proposed to model the speech signal. While the performance of such vocoders is well-known in the context of speech processing, their extrapolation to singing voice synthesis might not be straightforward. The goal of this paper is twofold. First, a comparative subjective evaluation is performed across four existing techniques suitable for statistical parametric synthesis: traditional pulse vocoder, Deterministic plus Stochastic Model, Harmonic plus Noise Model and GlottHMM. The behavior of these techniques as a function of the singer type (baritone, counter-tenor and soprano) is studied. Secondly, the artifacts occurring in high-pitched voices are discussed and possible approaches to overcome them are suggested.
Analysis and Synthesis of Hypo and Hyperarticulated Speech
Jun 07, 2020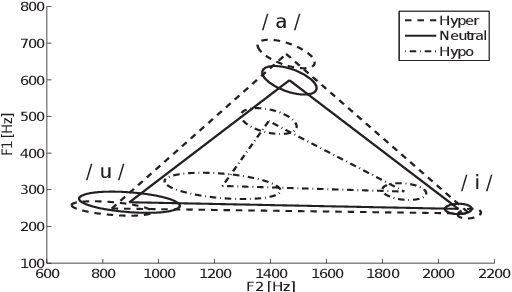

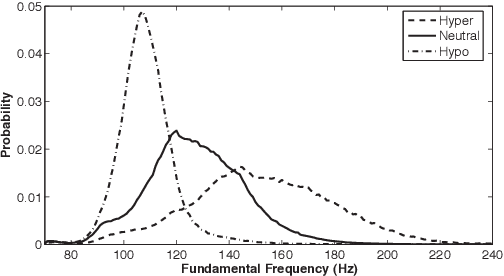
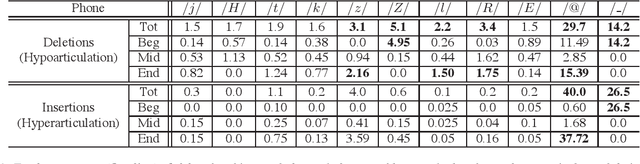
This paper focuses on the analysis and synthesis of hypo and hyperarticulated speech in the framework of HMM-based speech synthesis. First of all, a new French database matching our needs was created, which contains three identical sets, pronounced with three different degrees of articulation: neutral, hypo and hyperarticulated speech. On that basis, acoustic and phonetic analyses were performed. It is shown that the degrees of articulation significantly influence, on one hand, both vocal tract and glottal characteristics, and on the other hand, speech rate, phone durations, phone variations and the presence of glottal stops. Finally, neutral, hypo and hyperarticulated speech are synthesized using HMM-based speech synthesis and both objective and subjective tests aiming at assessing the generated speech quality are performed. These tests show that synthesized hypoarticulated speech seems to be less naturally rendered than neutral and hyperarticulated speech.