 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaga: A Platform for Continuous Construction and Serving of Knowledge At Scale
Apr 15, 2022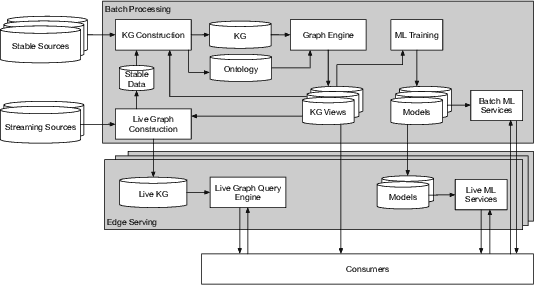
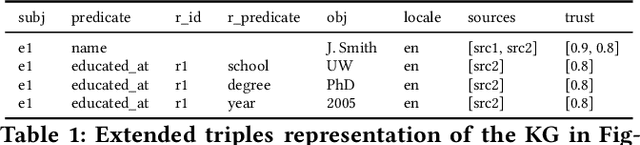
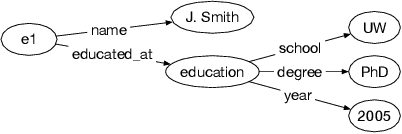
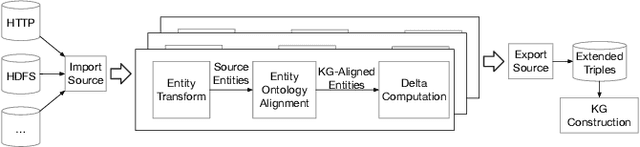
We introduce Saga, a next-generation knowledge construction and serving platform for powering knowledge-based applications at industrial scale. Saga follows a hybrid batch-incremental design to continuously integrate billions of facts about real-world entities and construct a central knowledge graph that supports multiple production use cases with diverse requirements around data freshness, accuracy, and availability. In this paper, we discuss the unique challenges associated with knowledge graph construction at industrial scale, and review the main components of Saga and how they address these challenges. Finally, we share lessons-learned from a wide array of production use cases powered by Saga.
Marius++: Large-Scale Training of Graph Neural Networks on a Single Machine
Feb 04, 2022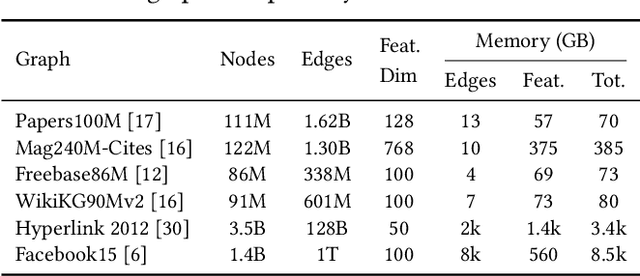
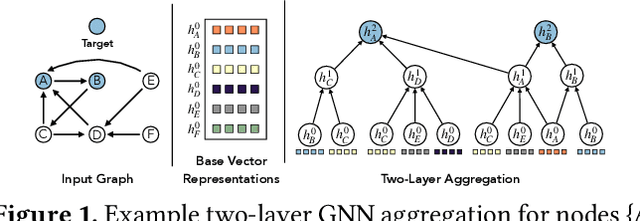
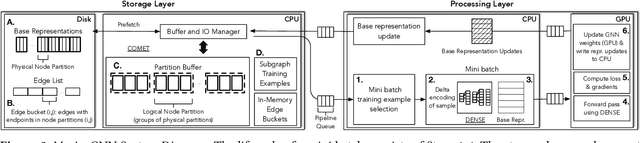
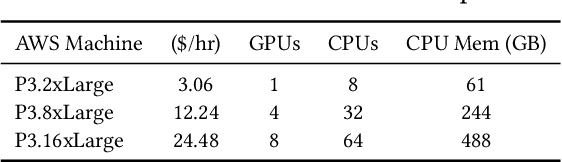
Graph Neural Networks (GNNs) have emerged as a powerful model for ML over graph-structured data. Yet, scalability remains a major challenge for using GNNs over billion-edge inputs. The creation of mini-batches used for training incurs computational and data movement costs that grow exponentially with the number of GNN layers as state-of-the-art models aggregate information from the multi-hop neighborhood of each input node. In this paper, we focus on scalable training of GNNs with emphasis on resource efficiency. We show that out-of-core pipelined mini-batch training in a single machine outperforms resource-hungry multi-GPU solutions. We introduce Marius++, a system for training GNNs over billion-scale graphs. Marius++ provides disk-optimized training for GNNs and introduces a series of data organization and algorithmic contributions that 1) minimize the memory-footprint and end-to-end time required for training and 2) ensure that models learned with disk-based training exhibit accuracy similar to those fully trained in mixed CPU/GPU settings. We evaluate Marius++ against PyTorch Geometric and Deep Graph Library using seven benchmark (model, data set) settings and find that Marius++ with one GPU can achieve the same level of model accuracy up to 8$\times$ faster than these systems when they are using up to eight GPUs. For these experiments, disk-based training allows Marius++ deployments to be up to 64$\times$ cheaper in monetary cost than those of the competing systems.
Ember: No-Code Context Enrichment via Similarity-Based Keyless Joins
Jun 02, 2021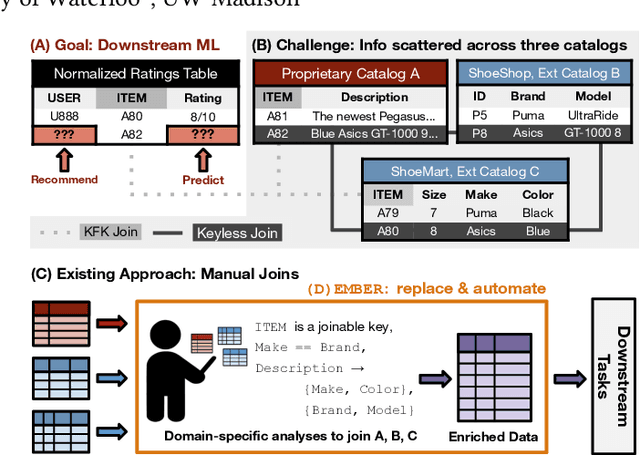
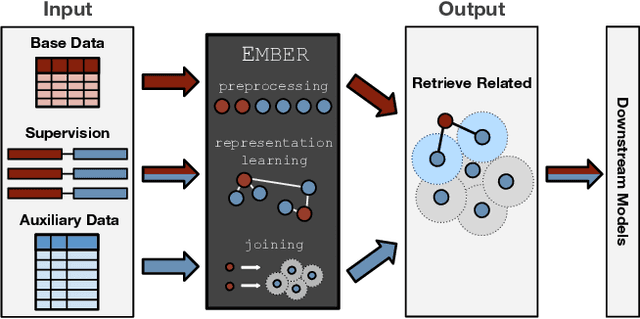
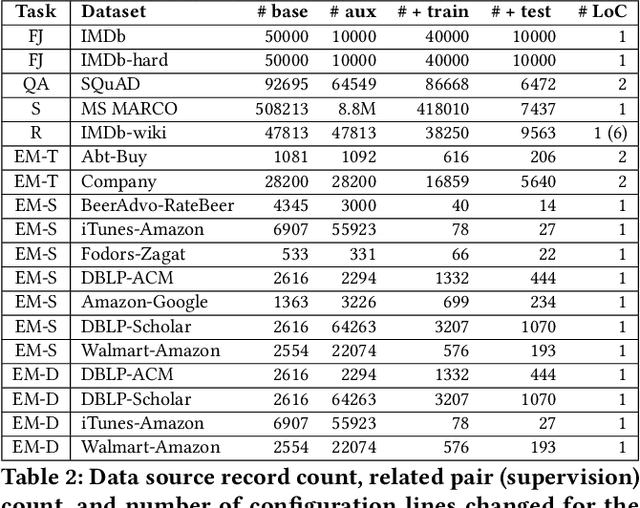
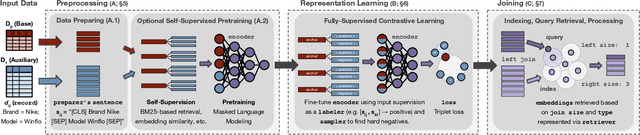
Structured data, or data that adheres to a pre-defined schema, can suffer from fragmented context: information describing a single entity can be scattered across multiple datasets or tables tailored for specific business needs, with no explicit linking keys (e.g., primary key-foreign key relationships or heuristic functions). Context enrichment, or rebuilding fragmented context, using keyless joins is an implicit or explicit step in machine learning (ML) pipelines over structured data sources. This process is tedious, domain-specific, and lacks support in now-prevalent no-code ML systems that let users create ML pipelines using just input data and high-level configuration files. In response, we propose Ember, a system that abstracts and automates keyless joins to generalize context enrichment. Our key insight is that Ember can enable a general keyless join operator by constructing an index populated with task-specific embeddings. Ember learns these embeddings by leveraging Transformer-based representation learning techniques. We describe our core architectural principles and operators when developing Ember, and empirically demonstrate that Ember allows users to develop no-code pipelines for five domains, including search, recommendation and question answering, and can exceed alternatives by up to 39% recall, with as little as a single line configuration change.
Learning Massive Graph Embeddings on a Single Machine
Jan 20, 2021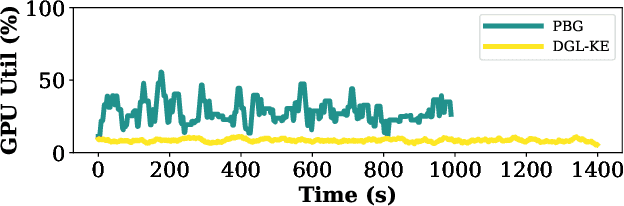

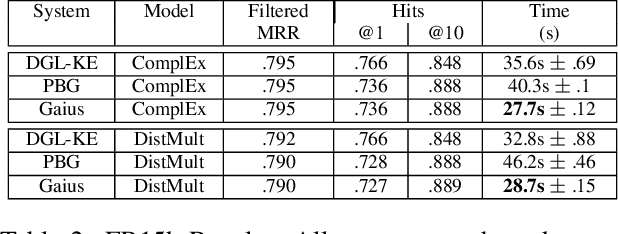
We propose a new framework for computing the embeddings of large-scale graphs on a single machine. A graph embedding is a fixed length vector representation for each node (and/or edge-type) in a graph and has emerged as the de-facto approach to apply modern machine learning on graphs. We identify that current systems for learning the embeddings of large-scale graphs are bottlenecked by data movement, which results in poor resource utilization and inefficient training. These limitations require state-of-the-art systems to distribute training across multiple machines. We propose Gaius, a system for efficient training of graph embeddings that leverages partition caching and buffer-aware data orderings to minimize disk access and interleaves data movement with computation to maximize utilization. We compare Gaius against two state-of-the-art industrial systems on a diverse array of benchmarks. We demonstrate that Gaius achieves the same level of accuracy but is up to one order-of magnitude faster. We also show that Gaius can scale training to datasets an order of magnitude beyond a single machine's GPU and CPU memory capacity, enabling training of configurations with more than a billion edges and 550GB of total parameters on a single AWS P3.2xLarge instance.
Unsupervised Relation Extraction from Language Models using Constrained Cloze Completion
Oct 14, 2020
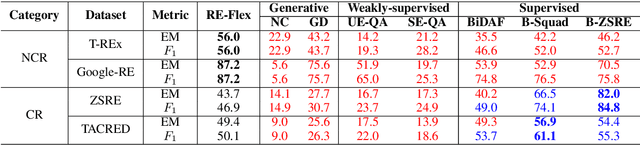
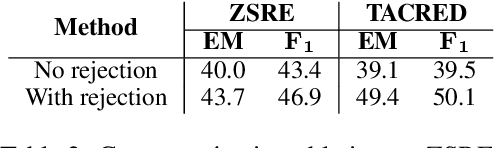
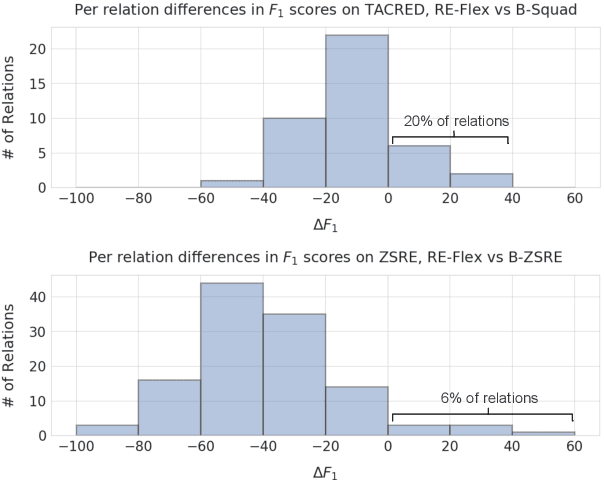
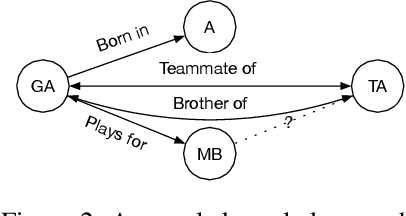
We show that state-of-the-art self-supervised language models can be readily used to extract relations from a corpus without the need to train a fine-tuned extractive head. We introduce RE-Flex, a simple framework that performs constrained cloze completion over pretrained language models to perform unsupervised relation extraction. RE-Flex uses contextual matching to ensure that language model predictions matches supporting evidence from the input corpus that is relevant to a target relation. We perform an extensive experimental study over multiple relation extraction benchmarks and demonstrate that RE-Flex outperforms competing unsupervised relation extraction methods based on pretrained language models by up to 27.8 $F_1$ points compared to the next-best method. Our results show that constrained inference queries against a language model can enable accurate unsupervised relation extraction.
Principal Component Networks: Parameter Reduction Early in Training
Jun 23, 2020

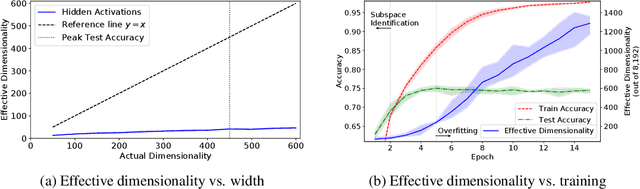
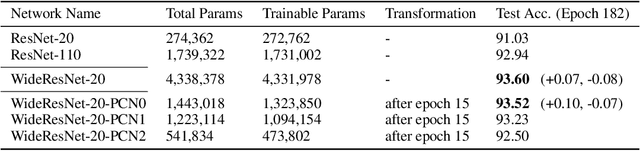
Recent works show that overparameterized networks contain small subnetworks that exhibit comparable accuracy to the full model when trained in isolation. These results highlight the potential to reduce training costs of deep neural networks without sacrificing generalization performance. However, existing approaches for finding these small networks rely on expensive multi-round train-and-prune procedures and are non-practical for large data sets and models. In this paper, we show how to find small networks that exhibit the same performance as their overparameterized counterparts after only a few training epochs. We find that hidden layer activations in overparameterized networks exist primarily in subspaces smaller than the actual model width. Building on this observation, we use PCA to find a basis of high variance for layer inputs and represent layer weights using these directions. We eliminate all weights not relevant to the found PCA basis and term these network architectures Principal Component Networks. On CIFAR-10 and ImageNet, we show that PCNs train faster and use less energy than overparameterized models, without accuracy loss. We find that our transformation leads to networks with up to 23.8x fewer parameters, with equal or higher end-model accuracy---in some cases we observe improvements up to 3%. We also show that ResNet-20 PCNs outperform deep ResNet-110 networks while training faster.
Record fusion: A learning approach
Jun 18, 2020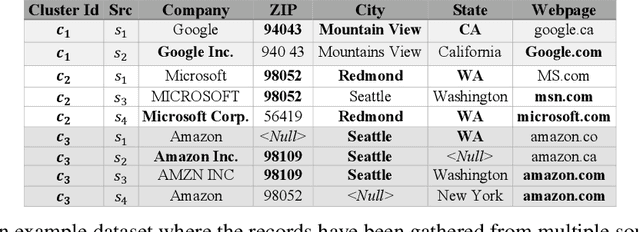
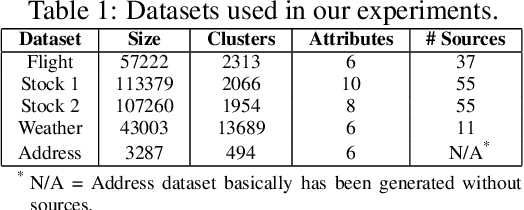
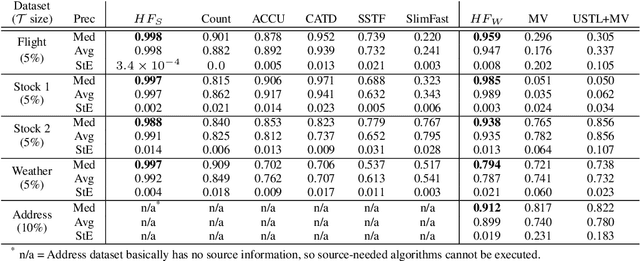
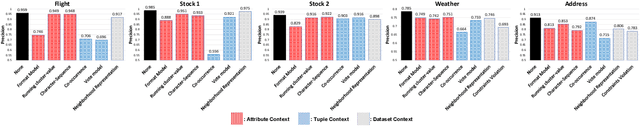
Record fusion is the task of aggregating multiple records that correspond to the same real-world entity in a database. We can view record fusion as a machine learning problem where the goal is to predict the "correct" value for each attribute for each entity. Given a database, we use a combination of attribute-level, recordlevel, and database-level signals to construct a feature vector for each cell (or (row, col)) of that database. We use this feature vector alongwith the ground-truth information to learn a classifier for each of the attributes of the database. Our learning algorithm uses a novel stagewise additive model. At each stage, we construct a new feature vector by combining a part of the original feature vector with features computed by the predictions from the previous stage. We then learn a softmax classifier over the new feature space. This greedy stagewise approach can be viewed as a deep model where at each stage, we are adding more complicated non-linear transformations of the original feature vector. We show that our approach fuses records with an average precision of ~98% when source information of records is available, and ~94% without source information across a diverse array of real-world datasets. We compare our approach to a comprehensive collection of data fusion and entity consolidation methods considered in the literature. We show that our approach can achieve an average precision improvement of ~20%/~45% with/without source information respectively.
An Empirical Analysis of the Impact of Data Augmentation on Knowledge Distillation
Jun 09, 2020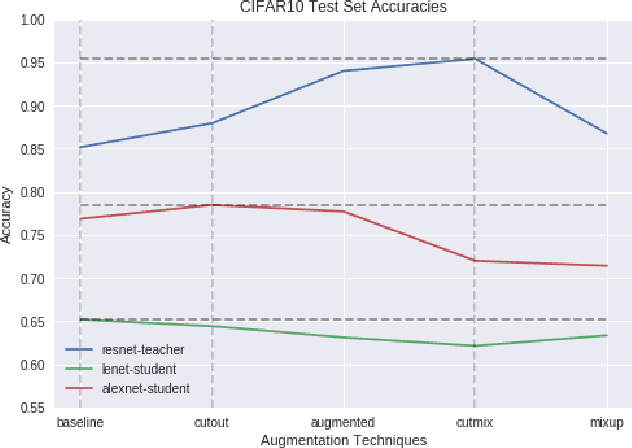
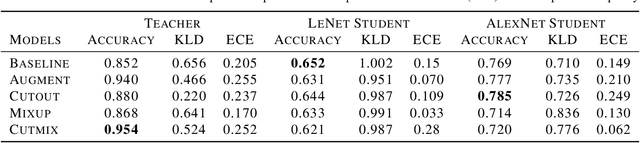


Generalization Performance of Deep Learning models trained using Empirical Risk Minimization can be improved significantly by using Data Augmentation strategies such as simple transformations, or using Mixed Samples. We attempt to empirically analyze the impact of such strategies on the transfer of generalization between teacher and student models in a distillation setup. We observe that if a teacher is trained using any of the mixed sample augmentation strategies, such as MixUp or CutMix, the student model distilled from it is impaired in its generalization capabilities. We hypothesize that such strategies limit a model's capability to learn example-specific features, leading to a loss in quality of the supervision signal during distillation. We present a novel Class-Discrimination metric to quantitatively measure this dichotomy in performance and link it to the discriminative capacity induced by the different strategies on a network's latent space.
Picket: Self-supervised Data Diagnostics for ML Pipelines
Jun 08, 2020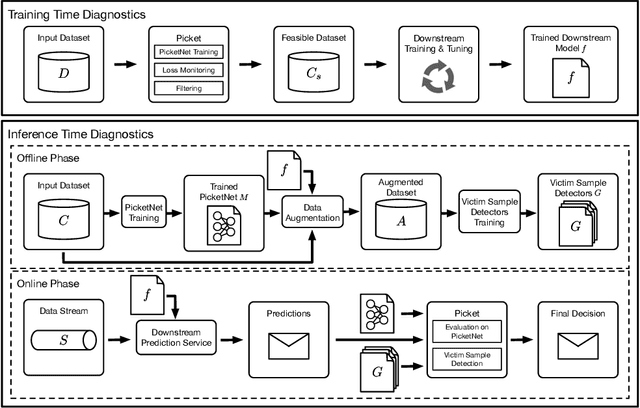
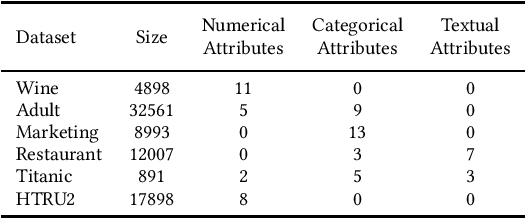
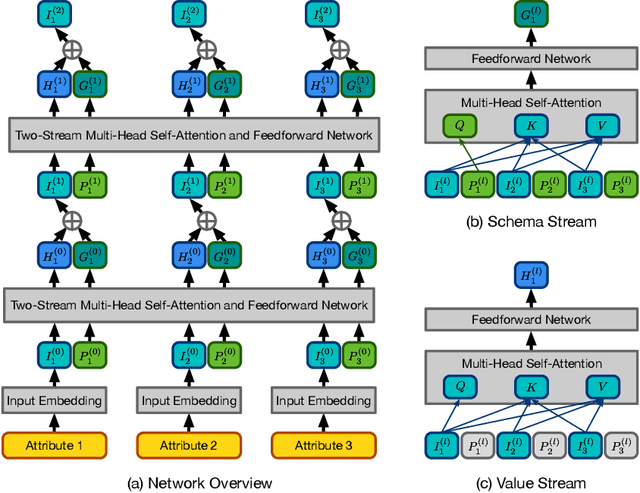
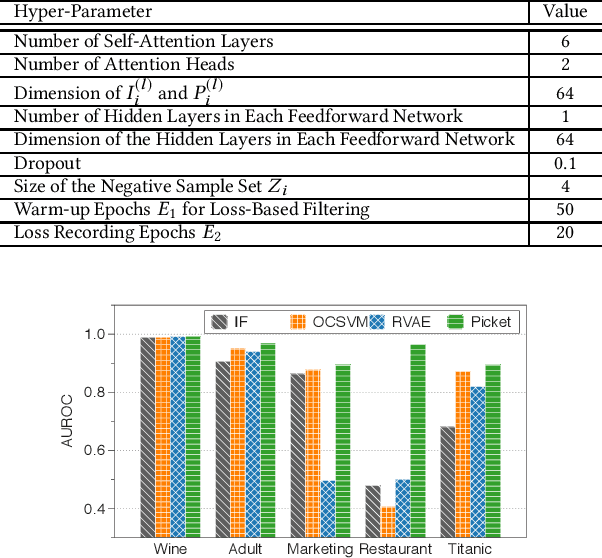
Data corruption is an impediment to modern machine learning deployments. Corrupted data can severely bias the learned model and can also lead to invalid inference. We present, Picket, a first-of-its-kind system that enables data diagnostics for machine learning pipelines over tabular data. Picket can safeguard against data corruptions that lead to degradation either during training or deployment. For the training stage, Picket identifies erroneous training examples that can result in a biased model, while for the deployment stage, Picket flags corrupted query points to a trained machine learning model that due to noise will result to incorrect predictions. Picket is built around a novel self-supervised deep learning model for mixed-type tabular data. Learning this model is fully unsupervised to minimize the burden of deployment, and Picket is designed as a plugin that can increase the robustness of any machine learning pipeline. We evaluate Picket on a diverse array of real-world data considering different corruption models that include systematic and adversarial noise. We show that Picket offers consistently accurate diagnostics during both training and deployment of various models ranging from SVMs to neural networks, beating competing methods of data quality validation in machine learning pipelines.
Robust Mean Estimation under Coordinate-level Corruption
Feb 10, 2020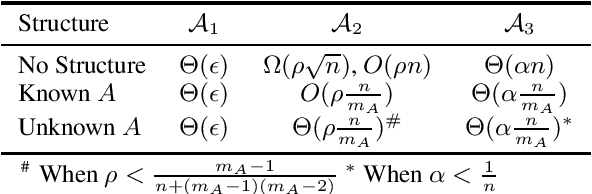
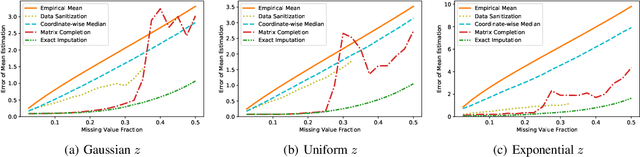
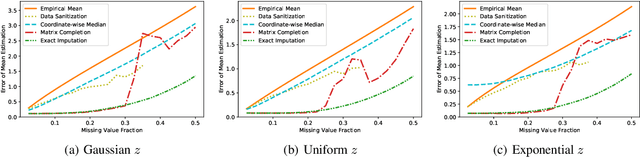
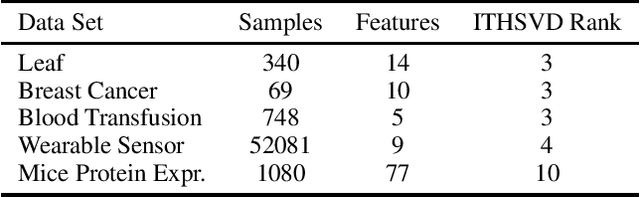
Data corruption, systematic or adversarial, may skew statistical estimation severely. Recent work provides computationally efficient estimators that nearly match the information-theoretic optimal statistic. Yet the corruption model they consider measures sample-level corruption and is not fine-grained enough for many real-world applications. In this paper, we propose a coordinate-level metric of distribution shift over high-dimensional settings with n coordinates. We introduce and analyze robust mean estimation techniques against an adversary who may hide individual coordinates of samples while being bounded by that metric. We show that for structured distribution settings, methods that leverage structure to fill in missing entries before mean estimation can improve the estimation accuracy by a factor of approximately n compared to structure-agnostic methods. We also leverage recent progress in matrix completion to obtain estimators for recovering the true mean of the samples in settings of unknown structure. We demonstrate with real-world data that our methods can capture the dependencies across attributes and provide accurate mean estimation even in high-magnitude corruption settings.