 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Guided Ansätze Design for Quantum Circuit Born Machines in Financial Generative Modeling
Sep 10, 2025Quantum generative modeling using quantum circuit Born machines (QCBMs) shows promising potential for practical quantum advantage. However, discovering ans\"atze that are both expressive and hardware-efficient remains a key challenge, particularly on noisy intermediate-scale quantum (NISQ) devices. In this work, we introduce a prompt-based framework that leverages large language models (LLMs) to generate hardware-aware QCBM architectures. Prompts are conditioned on qubit connectivity, gate error rates, and hardware topology, while iterative feedback, including Kullback-Leibler (KL) divergence, circuit depth, and validity, is used to refine the circuits. We evaluate our method on a financial modeling task involving daily changes in Japanese government bond (JGB) interest rates. Our results show that the LLM-generated ans\"atze are significantly shallower and achieve superior generative performance compared to the standard baseline when executed on real IBM quantum hardware using 12 qubits. These findings demonstrate the practical utility of LLM-driven quantum architecture search and highlight a promising path toward robust, deployable generative models for near-term quantum devices.
QuProFS: An Evolutionary Training-free Approach to Efficient Quantum Feature Map Search
Aug 09, 2025The quest for effective quantum feature maps for data encoding presents significant challenges, particularly due to the flat training landscapes and lengthy training processes associated with parameterised quantum circuits. To address these issues, we propose an evolutionary training-free quantum architecture search (QAS) framework that employs circuit-based heuristics focused on trainability, hardware robustness, generalisation ability, expressivity, complexity, and kernel-target alignment. By ranking circuit architectures with various proxies, we reduce evaluation costs and incorporate hardware-aware circuits to enhance robustness against noise. We evaluate our approach on classification tasks (using quantum support vector machine) across diverse datasets using both artificial and quantum-generated datasets. Our approach demonstrates competitive accuracy on both simulators and real quantum hardware, surpassing state-of-the-art QAS methods in terms of sampling efficiency and achieving up to a 2x speedup in architecture search runtime.
Communication Cost Reduction for Subgraph Counting under Local Differential Privacy via Hash Functions
Dec 12, 2023We suggest the use of hash functions to cut down the communication costs when counting subgraphs under edge local differential privacy. While various algorithms exist for computing graph statistics, including the count of subgraphs, under the edge local differential privacy, many suffer with high communication costs, making them less efficient for large graphs. Though data compression is a typical approach in differential privacy, its application in local differential privacy requires a form of compression that every node can reproduce. In our study, we introduce linear congruence hashing. With a sampling rate of $s$, our method can cut communication costs by a factor of $s^2$, albeit at the cost of increasing variance in the published graph statistic by a factor of $s$. The experimental results indicate that, when matched for communication costs, our method achieves a reduction in the $\ell_2$-error for triangle counts by up to 1000 times compared to the performance of leading algorithms.
Analyzing the Effect of Multi-task Learning for Biomedical Named Entity Recognition
Nov 01, 2020



Developing high-performing systems for detecting biomedical named entities has major implications. State-of-the-art deep-learning based solutions for entity recognition often require large annotated datasets, which is not available in the biomedical domain. Transfer learning and multi-task learning have been shown to improve performance for low-resource domains. However, the applications of these methods are relatively scarce in the biomedical domain, and a theoretical understanding of why these methods improve the performance is lacking. In this study, we performed an extensive analysis to understand the transferability between different biomedical entity datasets. We found useful measures to predict transferability between these datasets. Besides, we propose combining transfer learning and multi-task learning to improve the performance of biomedical named entity recognition systems, which is not applied before to the best of our knowledge.
Hierarchical Multi Task Learning with Subword Contextual Embeddings for Languages with Rich Morphology
Apr 25, 2020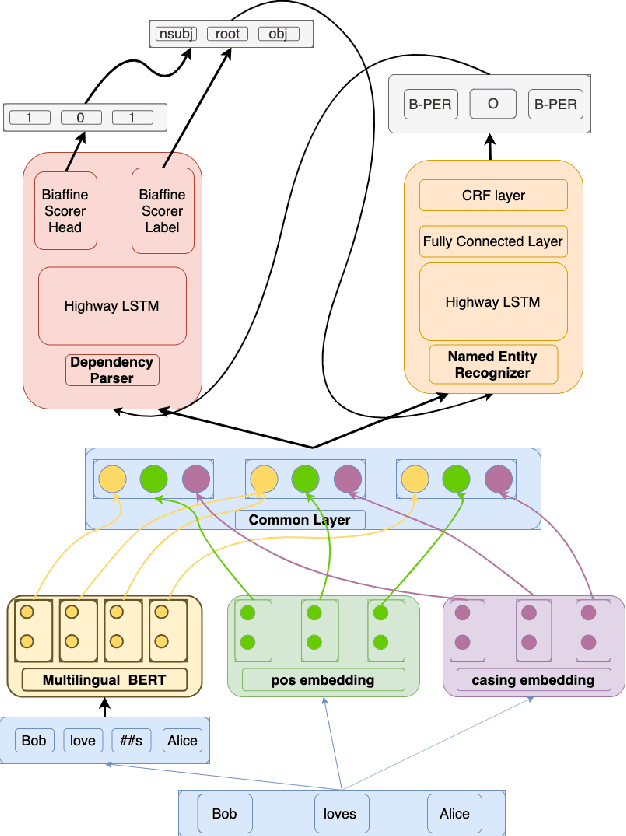

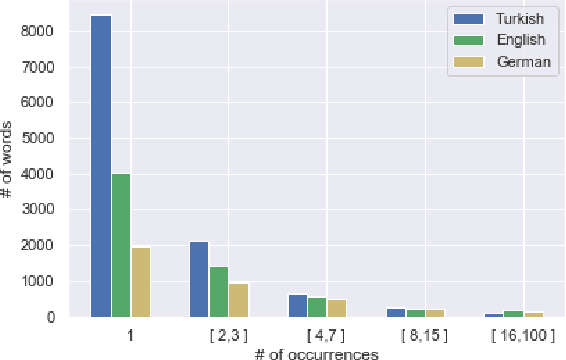
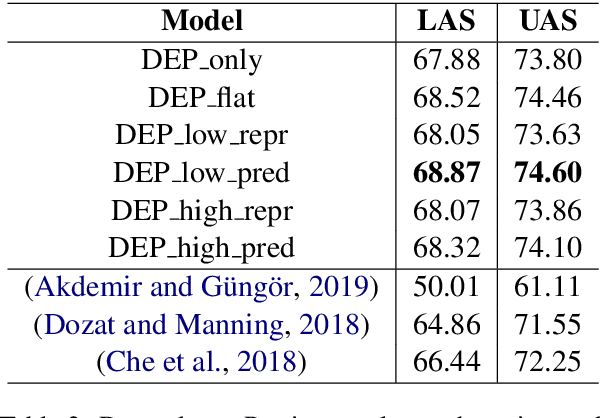
Morphological information is important for many sequence labeling tasks in Natural Language Processing (NLP). Yet, existing approaches rely heavily on manual annotations or external software to capture this information. In this study, we propose using subword contextual embeddings to capture the morphological information for languages with rich morphology. In addition, we incorporate these embeddings in a hierarchical multi-task setting which is not employed before, to the best of our knowledge. Evaluated on Dependency Parsing (DEP) and Named Entity Recognition (NER) tasks, which are shown to benefit greatly from morphological information, our final model outperforms previous state-of-the-art models on both tasks for the Turkish language. Besides, we show a net improvement of 18.86% and 4.61% F-1 over the previously proposed multi-task learner in the same setting for the DEP and the NER tasks, respectively. Empirical results for five different MTL settings show that incorporating subword contextual embeddings brings significant improvements for both tasks. In addition, we observed that multi-task learning consistently improves the performance of the DEP component.