 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Real-Time Rendered Scenes as 3D Gaussians
Apr 03, 2026Cloud rendering is widely used in gaming and XR to overcome limited client-side GPU resources and to support heterogeneous devices. Existing systems typically deliver the rendered scene as a 2D video stream, which tightly couples the transmitted content to the server-rendered viewpoint and limits latency compensation to image-space reprojection or warping. In this paper, we investigate an alternative approach based on streaming a live 3D Gaussian Splatting (3DGS) scene representation instead of only rendered video. We present a Unity-based prototype in which a server constructs and continuously optimizes a 3DGS model from real-time rendered reference views, while streaming the evolving representation to remote clients using full model snapshots and incremental updates supporting relighting and rigid object dynamics. The clients reconstruct the streamed Gaussian model locally and render their current viewpoint from the received representation. This approach aims to improve viewpoint flexibility for latency compensation and to better amortize server-side scene modeling across multiple users than per-user rendering and video streaming. We describe the system design, evaluate it, and compare it with conventional image warping.
Neural Network Assisted Depth Map Packing for Compression Using Standard Hardware Video Codecs
Jun 30, 2022



Depth maps are needed by various graphics rendering and processing operations. Depth map streaming is often necessary when such operations are performed in a distributed system and it requires in most cases fast performing compression, which is why video codecs are often used. Hardware implementations of standard video codecs enable relatively high resolution and framerate combinations, even on resource constrained devices, but unfortunately those implementations do not currently support RGB+depth extensions. However, they can be used for depth compression by first packing the depth maps into RGB or YUV frames. We investigate depth map compression using a combination of depth map packing followed by encoding with a standard video codec. We show that the precision at which depth maps are packed has a large and nontrivial impact on the resulting error caused by the combination of the packing scheme and lossy compression when bitrate is constrained. Consequently, we propose a variable precision packing scheme assisted by a neural network model that predicts the optimal precision for each depth map given a bitrate constraint. We demonstrate that the model yields near optimal predictions and that it can be integrated into a game engine with very low overhead using modern hardware.
Latency and Throughput Characterization of Convolutional Neural Networks for Mobile Computer Vision
Mar 26, 2018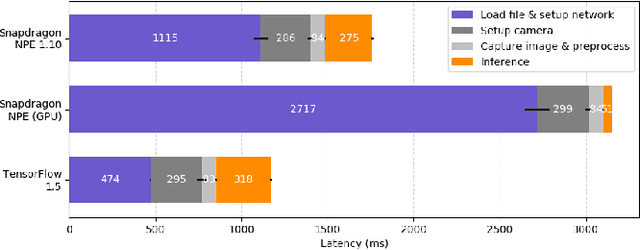
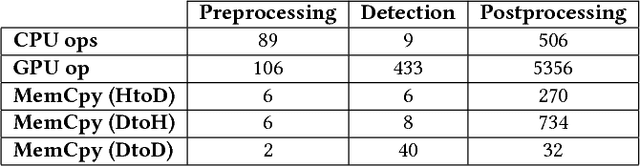
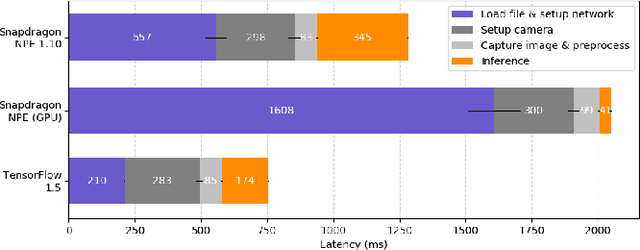
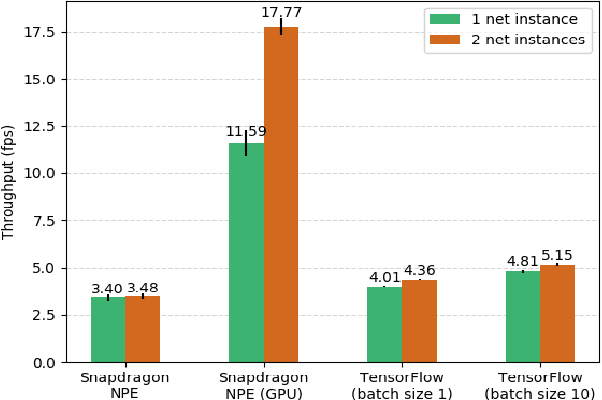
We study performance characteristics of convolutional neural networks (CNN) for mobile computer vision systems. CNNs have proven to be a powerful and efficient approach to implement such systems. However, the system performance depends largely on the utilization of hardware accelerators, which are able to speed up the execution of the underlying mathematical operations tremendously through massive parallelism. Our contribution is performance characterization of multiple CNN-based models for object recognition and detection with several different hardware platforms and software frameworks, using both local (on-device) and remote (network-side server) computation. The measurements are conducted using real workloads and real processing platforms. On the platform side, we concentrate especially on TensorFlow and TensorRT. Our measurements include embedded processors found on mobile devices and high-performance processors that can be used on the network side of mobile systems. We show that there exists significant latency--throughput trade-offs but the behavior is very complex. We demonstrate and discuss several factors that affect the performance and yield this complex behavior.