 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashAttention-4: Algorithm and Kernel Pipelining Co-Design for Asymmetric Hardware Scaling
Mar 05, 2026Attention, as a core layer of the ubiquitous Transformer architecture, is the bottleneck for large language models and long-context applications. While FlashAttention-3 optimized attention for Hopper GPUs through asynchronous execution and warp specialization, it primarily targets the H100 architecture. The AI industry has rapidly transitioned to deploying Blackwell-based systems such as the B200 and GB200, which exhibit fundamentally different performance characteristics due to asymmetric hardware scaling: tensor core throughput doubles while other functional units (shared memory bandwidth, exponential units) scale more slowly or remain unchanged. We develop several techniques to address these shifting bottlenecks on Blackwell GPUs: (1) redesigned pipelines that exploit fully asynchronous MMA operations and larger tile sizes, (2) software-emulated exponential and conditional softmax rescaling that reduces non-matmul operations, and (3) leveraging tensor memory and the 2-CTA MMA mode to reduce shared memory traffic and atomic adds in the backward pass. We demonstrate that our method, FlashAttention-4, achieves up to 1.3$\times$ speedup over cuDNN 9.13 and 2.7$\times$ over Triton on B200 GPUs with BF16, reaching up to 1613 TFLOPs/s (71% utilization). Beyond algorithmic innovations, we implement FlashAttention-4 entirely in CuTe-DSL embedded in Python, achieving 20-30$\times$ faster compile times compared to traditional C++ template-based approaches while maintaining full expressivity.
Hardware-Efficient Attention for Fast Decoding
May 27, 2025

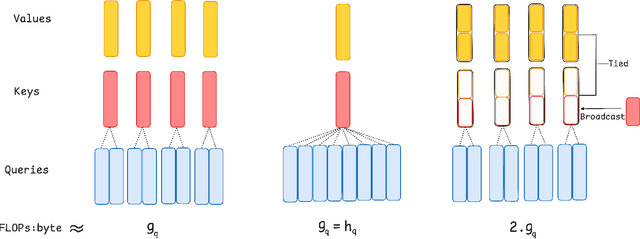

LLM decoding is bottlenecked for large batches and long contexts by loading the key-value (KV) cache from high-bandwidth memory, which inflates per-token latency, while the sequential nature of decoding limits parallelism. We analyze the interplay among arithmetic intensity, parallelization, and model quality and question whether current architectures fully exploit modern hardware. This work redesigns attention to perform more computation per byte loaded from memory to maximize hardware efficiency without trading off parallel scalability. We first propose Grouped-Tied Attention (GTA), a simple variant that combines and reuses key and value states, reducing memory transfers without compromising model quality. We then introduce Grouped Latent Attention (GLA), a parallel-friendly latent attention paired with low-level optimizations for fast decoding while maintaining high model quality. Experiments show that GTA matches Grouped-Query Attention (GQA) quality while using roughly half the KV cache and that GLA matches Multi-head Latent Attention (MLA) and is easier to shard. Our optimized GLA kernel is up to 2$\times$ faster than FlashMLA, for example, in a speculative decoding setting when the query length exceeds one. Furthermore, by fetching a smaller KV cache per device, GLA reduces end-to-end latency and increases throughput in online serving benchmarks by up to 2$\times$.
Pushing Mixture of Experts to the Limit: Extremely Parameter Efficient MoE for Instruction Tuning
Sep 11, 2023



The Mixture of Experts (MoE) is a widely known neural architecture where an ensemble of specialized sub-models optimizes overall performance with a constant computational cost. However, conventional MoEs pose challenges at scale due to the need to store all experts in memory. In this paper, we push MoE to the limit. We propose extremely parameter-efficient MoE by uniquely combining MoE architecture with lightweight experts.Our MoE architecture outperforms standard parameter-efficient fine-tuning (PEFT) methods and is on par with full fine-tuning by only updating the lightweight experts -- less than 1% of an 11B parameters model. Furthermore, our method generalizes to unseen tasks as it does not depend on any prior task knowledge. Our research underscores the versatility of the mixture of experts architecture, showcasing its ability to deliver robust performance even when subjected to rigorous parameter constraints. Our code used in all the experiments is publicly available here: https://github.com/for-ai/parameter-efficient-moe.
High Probability Bounds for Stochastic Continuous Submodular Maximization
Mar 20, 2023



We consider maximization of stochastic monotone continuous submodular functions (CSF) with a diminishing return property. Existing algorithms only guarantee the performance \textit{in expectation}, and do not bound the probability of getting a bad solution. This implies that for a particular run of the algorithms, the solution may be much worse than the provided guarantee in expectation. In this paper, we first empirically verify that this is indeed the case. Then, we provide the first \textit{high-probability} analysis of the existing methods for stochastic CSF maximization, namely PGA, boosted PGA, SCG, and SCG++. Finally, we provide an improved high-probability bound for SCG, under slightly stronger assumptions, with a better convergence rate than that of the expected solution. Through extensive experiments on non-concave quadratic programming (NQP) and optimal budget allocation, we confirm the validity of our bounds and show that even in the worst-case, PGA converges to $OPT/2$, and boosted PGA, SCG, SCG++ converge to $(1 - 1/e)OPT$, but at a slower rate than that of the expected solution.