 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Errors Can Be Beneficial: A Categorization of Imperfect Rewards for Policy Gradient
Apr 28, 2026Training language models via reinforcement learning often relies on imperfect proxy rewards, since ground truth rewards that precisely define the intended behavior are rarely available. Standard metrics for assessing the quality of proxy rewards, such as ranking accuracy, treat incorrect rewards as strictly harmful. In this work, however, we highlight that not all deviations from the ground truth are equal. By theoretically analyzing which outputs attract probability during policy gradient optimization, we categorize reward errors according to their effect on the increase in ground truth reward. The analysis establishes that reward errors, though conventionally viewed as harmful, can also be benign or even beneficial by preventing the policy from stalling around outputs with mediocre ground truth reward. We then present two practical implications of our theory. First, for reinforcement learning from human feedback (RLHF), we develop reward model evaluation metrics that account for the harmfulness of reward errors. Compared to standard ranking accuracy, these metrics typically correlate better with the performance of a language model after RLHF, yet gaps remain in robustly evaluating reward models. Second, we provide insights for reward design in settings with verifiable rewards. A key theme underlying our results is that the effectiveness of a proxy reward function depends heavily on its interaction with the initial policy and learning algorithm.
Hardware-Efficient Attention for Fast Decoding
May 27, 2025

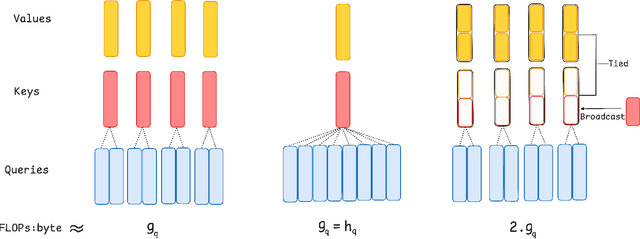

LLM decoding is bottlenecked for large batches and long contexts by loading the key-value (KV) cache from high-bandwidth memory, which inflates per-token latency, while the sequential nature of decoding limits parallelism. We analyze the interplay among arithmetic intensity, parallelization, and model quality and question whether current architectures fully exploit modern hardware. This work redesigns attention to perform more computation per byte loaded from memory to maximize hardware efficiency without trading off parallel scalability. We first propose Grouped-Tied Attention (GTA), a simple variant that combines and reuses key and value states, reducing memory transfers without compromising model quality. We then introduce Grouped Latent Attention (GLA), a parallel-friendly latent attention paired with low-level optimizations for fast decoding while maintaining high model quality. Experiments show that GTA matches Grouped-Query Attention (GQA) quality while using roughly half the KV cache and that GLA matches Multi-head Latent Attention (MLA) and is easier to shard. Our optimized GLA kernel is up to 2$\times$ faster than FlashMLA, for example, in a speculative decoding setting when the query length exceeds one. Furthermore, by fetching a smaller KV cache per device, GLA reduces end-to-end latency and increases throughput in online serving benchmarks by up to 2$\times$.
What Makes a Reward Model a Good Teacher? An Optimization Perspective
Mar 19, 2025The success of Reinforcement Learning from Human Feedback (RLHF) critically depends on the quality of the reward model. While this quality is primarily evaluated through accuracy, it remains unclear whether accuracy fully captures what makes a reward model an effective teacher. We address this question from an optimization perspective. First, we prove that regardless of how accurate a reward model is, if it induces low reward variance, then the RLHF objective suffers from a flat landscape. Consequently, even a perfectly accurate reward model can lead to extremely slow optimization, underperforming less accurate models that induce higher reward variance. We additionally show that a reward model that works well for one language model can induce low reward variance, and thus a flat objective landscape, for another. These results establish a fundamental limitation of evaluating reward models solely based on accuracy or independently of the language model they guide. Experiments using models of up to 8B parameters corroborate our theory, demonstrating the interplay between reward variance, accuracy, and reward maximization rate. Overall, our findings highlight that beyond accuracy, a reward model needs to induce sufficient variance for efficient optimization.