 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaptioning Images with Novel Objects via Online Vocabulary Expansion
Mar 06, 2020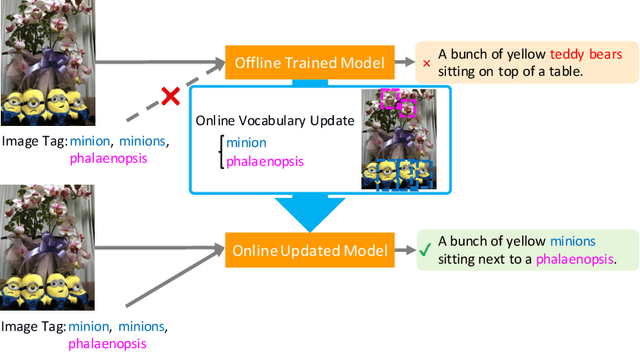

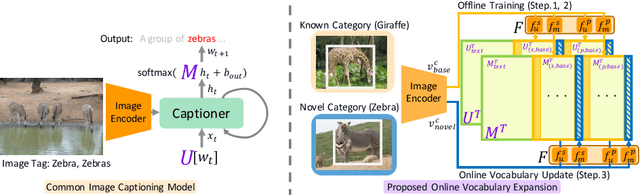

In this study, we introduce a low cost method for generating descriptions from images containing novel objects. Generally, constructing a model, which can explain images with novel objects, is costly because of the following: (1) collecting a large amount of data for each category, and (2) retraining the entire system. If humans see a small number of novel objects, they are able to estimate their properties by associating their appearance with known objects. Accordingly, we propose a method that can explain images with novel objects without retraining using the word embeddings of the objects estimated from only a small number of image features of the objects. The method can be integrated with general image-captioning models. The experimental results show the effectiveness of our approach.
Coronary Wall Segmentation in CCTA Scans via a Hybrid Net with Contours Regularization
Feb 27, 2020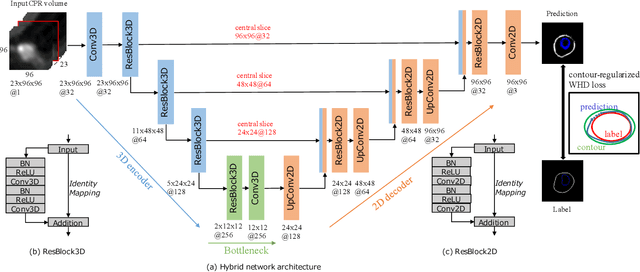
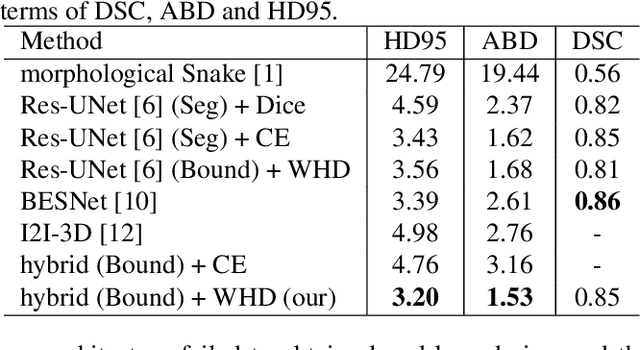

Providing closed and well-connected boundaries of coronary artery is essential to assist cardiologists in the diagnosis of coronary artery disease (CAD). Recently, several deep learning-based methods have been proposed for boundary detection and segmentation in a medical image. However, when applied to coronary wall detection, they tend to produce disconnected and inaccurate boundaries. In this paper, we propose a novel boundary detection method for coronary arteries that focuses on the continuity and connectivity of the boundaries. In order to model the spatial continuity of consecutive images, our hybrid architecture takes a volume (i.e., a segment of the coronary artery) as input and detects the boundary of the target slice (i.e., the central slice of the segment). Then, to ensure closed boundaries, we propose a contour-constrained weighted Hausdorff distance loss. We evaluate our method on a dataset of 34 patients of coronary CT angiography scans with curved planar reconstruction (CCTA-CPR) of the arteries (i.e., cross-sections). Experiment results show that our method can produce smooth closed boundaries outperforming the state-of-the-art accuracy.
Spherical Image Generation from a Single Normal Field of View Image by Considering Scene Symmetry
Jan 09, 2020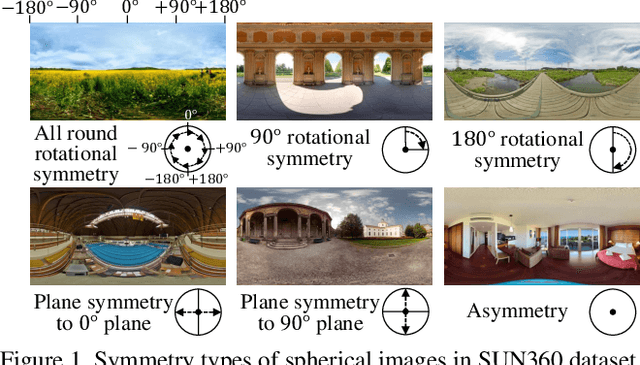
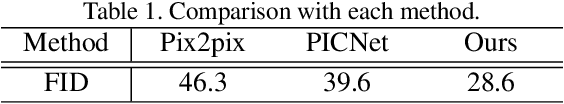
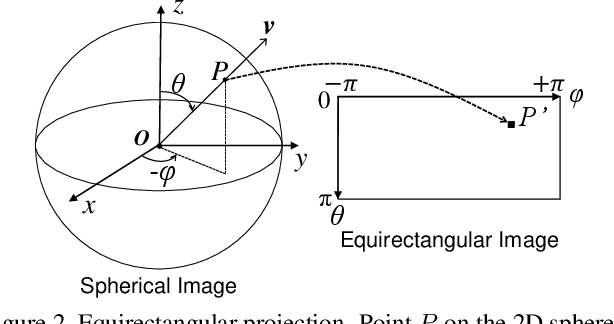

Spherical images taken in all directions (360 degrees) allow representing the surroundings of the subject and the space itself, providing an immersive experience to the viewers. Generating a spherical image from a single normal-field-of-view (NFOV) image is convenient and considerably expands the usage scenarios because there is no need to use a specific panoramic camera or take images from multiple directions; however, it is still a challenging and unsolved problem. The primary challenge is controlling the high degree of freedom involved in generating a wide area that includes the all directions of the desired plausible spherical image. On the other hand, scene symmetry is a basic property of the global structure of the spherical images, such as rotation symmetry, plane symmetry and asymmetry. We propose a method to generate spherical image from a single NFOV image, and control the degree of freedom of the generated regions using scene symmetry. We incorporate scene-symmetry parameters as latent variables into conditional variational autoencoders, following which we learn the conditional probability of spherical images for NFOV images and scene symmetry. Furthermore, the probability density functions are represented using neural networks, and scene symmetry is implemented using both circular shift and flip of the hidden variables. Our experiments show that the proposed method can generate various plausible spherical images, controlled from symmetric to asymmetric.
Noise Robust Generative Adversarial Networks
Nov 26, 2019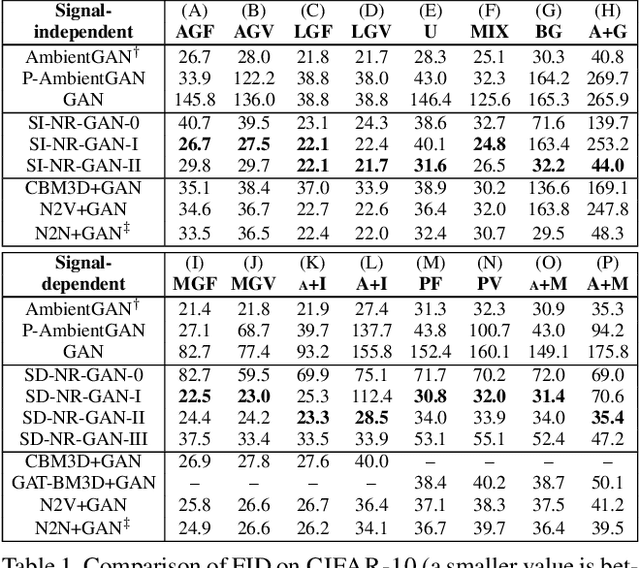

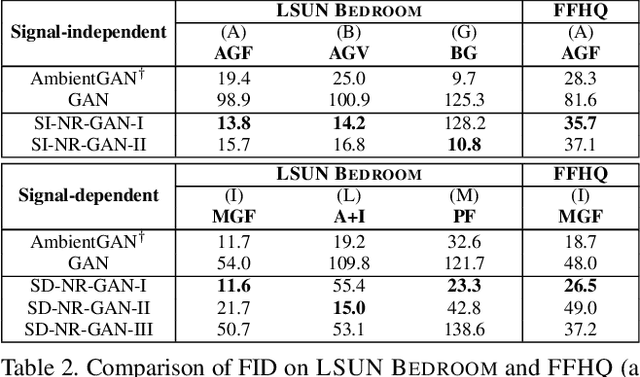
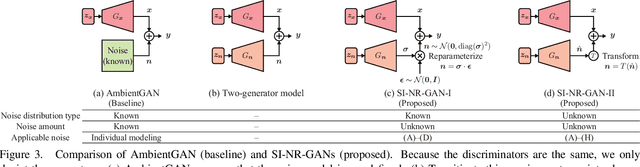
Generative adversarial networks (GANs) are neural networks that learn data distributions through adversarial training. In intensive studies, recent GANs have shown promising results for reproducing training data. However, in spite of noise, they reproduce data with fidelity. As an alternative, we propose a novel family of GANs called noise-robust GANs (NR-GANs), which can learn a clean image generator even when training data are noisy. In particular, NR-GANs can solve this problem without having complete noise information (e.g., the noise distribution type, noise amount, or signal-noise relation). To achieve this, we introduce a noise generator and train it along with a clean image generator. As it is difficult to generate an image and a noise separately without constraints, we propose distribution and transformation constraints that encourage the noise generator to capture only the noise-specific components. In particular, considering such constraints under different assumptions, we devise two variants of NR-GANs for signal-independent noise and three variants of NR-GANs for signal-dependent noise. On three benchmark datasets, we demonstrate the effectiveness of NR-GANs in noise robust image generation. Furthermore, we show the applicability of NR-GANs in image denoising.
Unsupervised Keyword Extraction for Full-sentence VQA
Nov 23, 2019
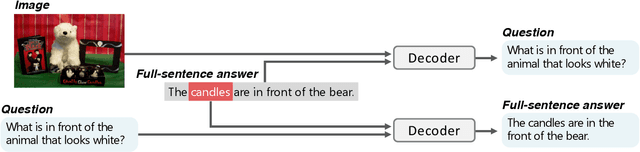
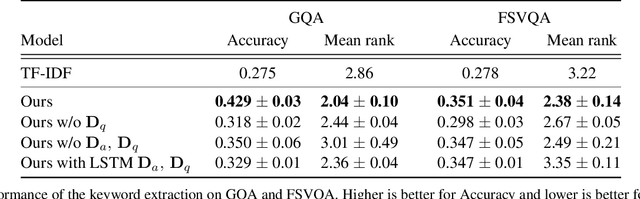
In existing studies on Visual Question Answering (VQA), which aims to train an intelligent system to be able to answer questions about images, the answers corresponding to the questions consists of short, almost single words. However, considering the natural conversation with humans, the answers would more likely to be sentences, rather than single words. In such a situation, the system needs to focus on a keyword, i.e., the most important word in the sentence, to answer the question. Therefore, we have proposed a novel keyword extraction method for VQA. Because collecting keywords and full-sentence annotations for VQA can be highly costly, we perform the keyword extraction in an unsupervised manner. Our key insight is that the full-sentence answer can be decomposed into two parts: the part contains new information for the question and the part only contains information already included in the question. Since the keyword is considered as the part which contains new information as the answer, we need to identify which words in the full-sentence answer are the part of new information and which words are not. To ensure such decomposition, we extracted two features from the full-sentence answers, and designed discriminative decoders to make each feature to include the information of the question and answers respectively. We conducted experiments on existing VQA datasets, which contains full-sentence annotations, and show that our proposed model can correctly extract the keyword without any keyword annotations.
Self-supervised Learning of 3D Objects from Natural Images
Nov 20, 2019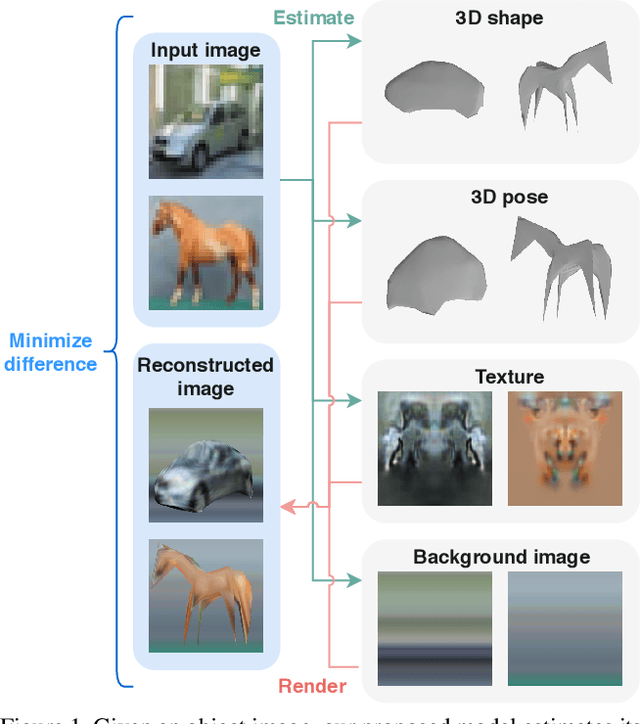
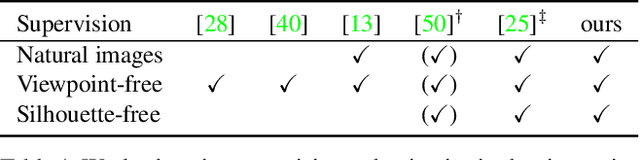
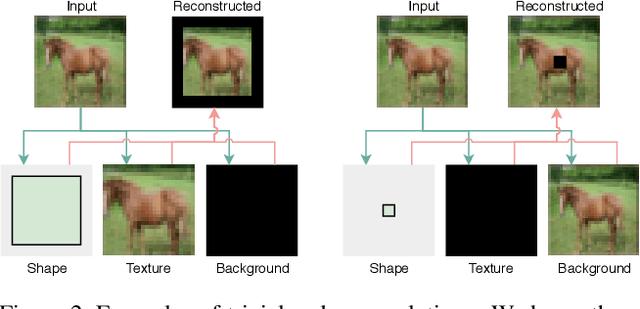
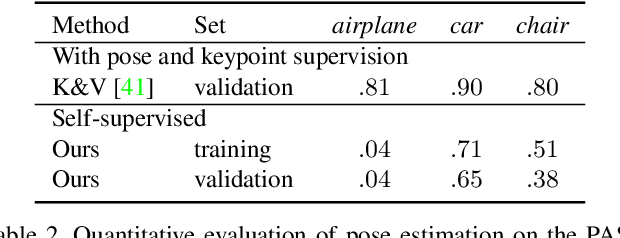
We present a method to learn single-view reconstruction of the 3D shape, pose, and texture of objects from categorized natural images in a self-supervised manner. Since this is a severely ill-posed problem, carefully designing a training method and introducing constraints are essential. To avoid the difficulty of training all elements at the same time, we propose training category-specific base shapes with fixed pose distribution and simple textures first, and subsequently training poses and textures using the obtained shapes. Another difficulty is that shapes and backgrounds sometimes become excessively complicated to mistakenly reconstruct textures on object surfaces. To suppress it, we propose using strong regularization and constraints on object surfaces and background images. With these two techniques, we demonstrate that we can use natural image collections such as CIFAR-10 and PASCAL objects for training, which indicates the possibility to realize 3D object reconstruction on diverse object categories beyond synthetic datasets.
Domain Generalization Using a Mixture of Multiple Latent Domains
Nov 18, 2019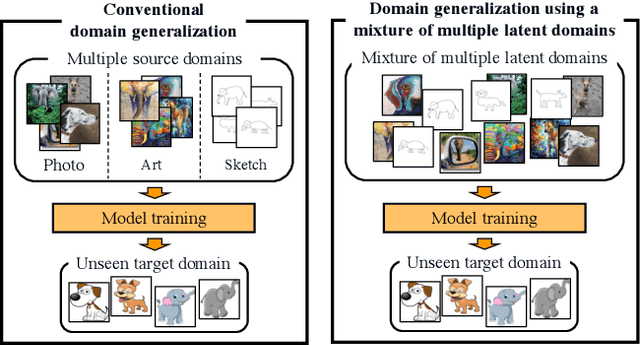
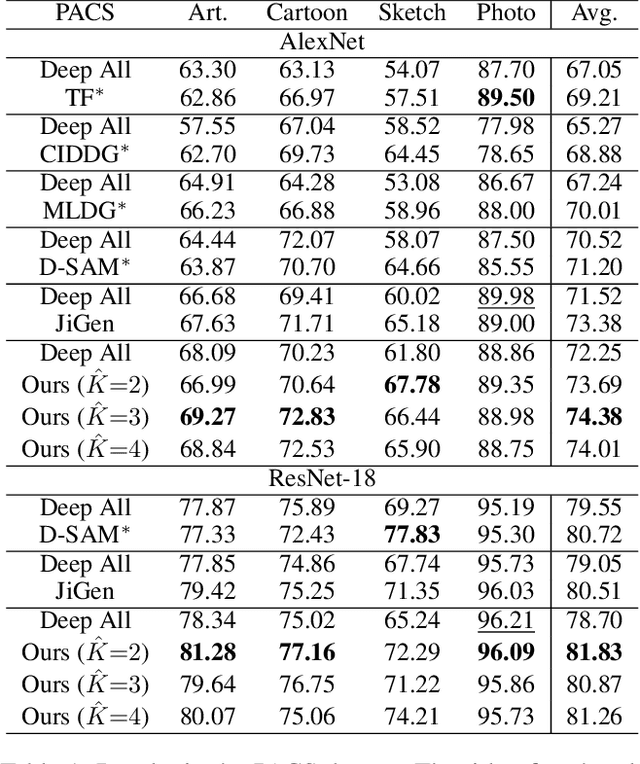
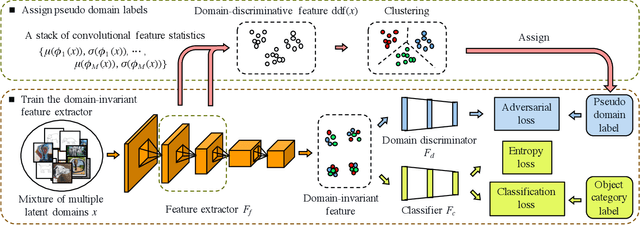
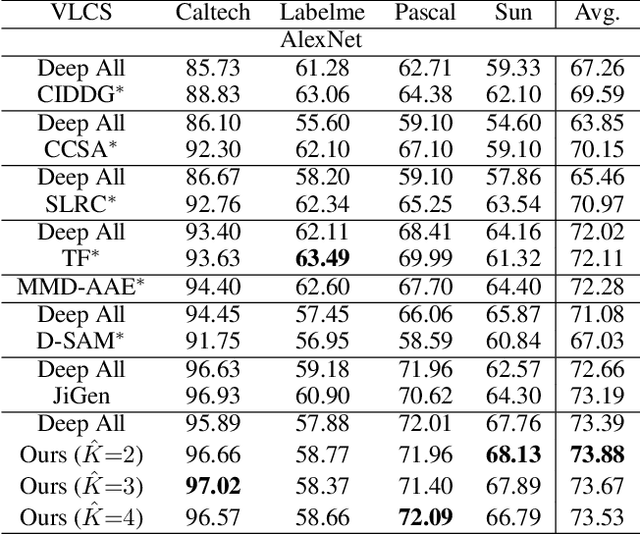
When domains, which represent underlying data distributions, vary during training and testing processes, deep neural networks suffer a drop in their performance. Domain generalization allows improvements in the generalization performance for unseen target domains by using multiple source domains. Conventional methods assume that the domain to which each sample belongs is known in training. However, many datasets, such as those collected via web crawling, contain a mixture of multiple latent domains, in which the domain of each sample is unknown. This paper introduces domain generalization using a mixture of multiple latent domains as a novel and more realistic scenario, where we try to train a domain-generalized model without using domain labels. To address this scenario, we propose a method that iteratively divides samples into latent domains via clustering, and which trains the domain-invariant feature extractor shared among the divided latent domains via adversarial learning. We assume that the latent domain of images is reflected in their style, and thus, utilize style features for clustering. By using these features, our proposed method successfully discovers latent domains and achieves domain generalization even if the domain labels are not given. Experiments show that our proposed method can train a domain-generalized model without using domain labels. Moreover, it outperforms conventional domain generalization methods, including those that utilize domain labels.
Multi-Stage Pathological Image Classification using Semantic Segmentation
Oct 10, 2019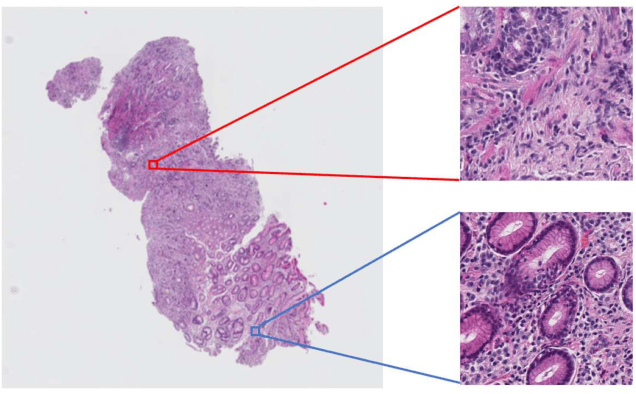
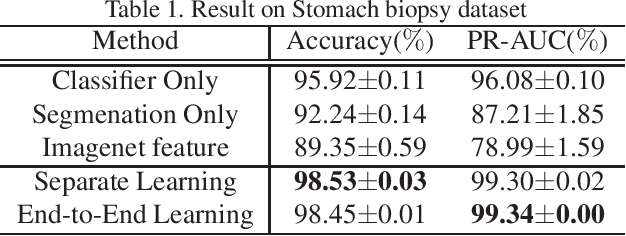
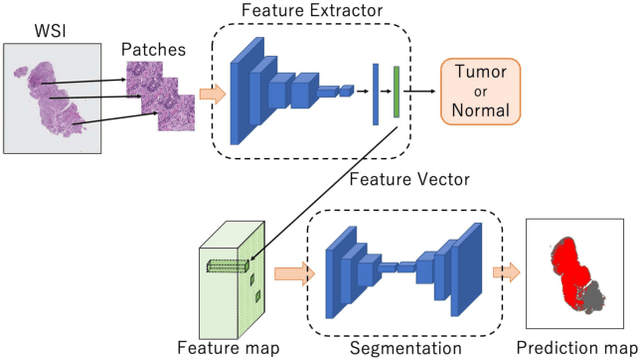
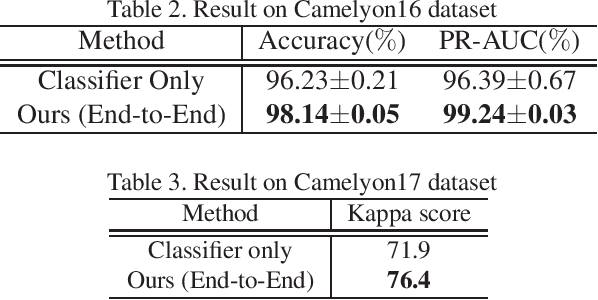
Histopathological image analysis is an essential process for the discovery of diseases such as cancer. However, it is challenging to train CNN on whole slide images (WSIs) of gigapixel resolution considering the available memory capacity. Most of the previous works divide high resolution WSIs into small image patches and separately input them into the model to classify it as a tumor or a normal tissue. However, patch-based classification uses only patch-scale local information but ignores the relationship between neighboring patches. If we consider the relationship of neighboring patches and global features, we can improve the classification performance. In this paper, we propose a new model structure combining the patch-based classification model and whole slide-scale segmentation model in order to improve the prediction performance of automatic pathological diagnosis. We extract patch features from the classification model and input them into the segmentation model to obtain a whole slide tumor probability heatmap. The classification model considers patch-scale local features, and the segmentation model can take global information into account. We also propose a new optimization method that retains gradient information and trains the model partially for end-to-end learning with limited GPU memory capacity. We apply our method to the tumor/normal prediction on WSIs and the classification performance is improved compared with the conventional patch-based method.
A General Upper Bound for Unsupervised Domain Adaptation
Oct 04, 2019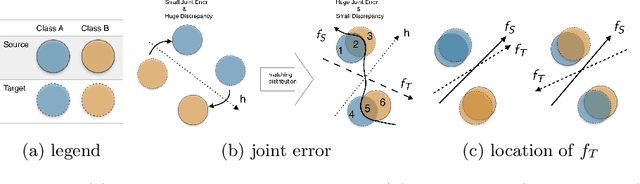
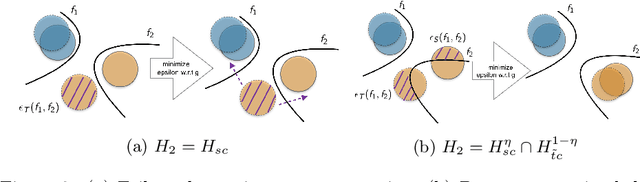

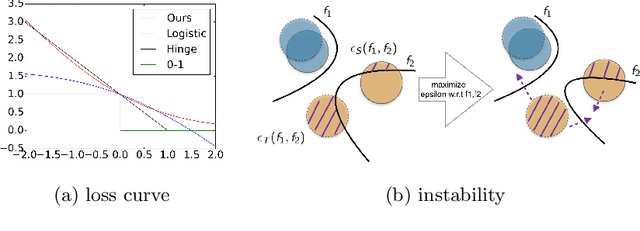
In this work, we present a novel upper bound of target error to address the problem for unsupervised domain adaptation. Recent studies reveal that a deep neural network can learn transferable features which generalize well to novel tasks. Furthermore, a theory proposed by Ben-David et al. (2010) provides a upper bound for target error when transferring the knowledge, which can be summarized as minimizing the source error and distance between marginal distributions simultaneously. However, common methods based on the theory usually ignore the joint error such that samples from different classes might be mixed together when matching marginal distribution. And in such case, no matter how we minimize the marginal discrepancy, the target error is not bounded due to an increasing joint error. To address this problem, we propose a general upper bound taking joint error into account, such that the undesirable case can be properly penalized. In addition, we utilize constrained hypothesis space to further formalize a tighter bound as well as a novel cross margin discrepancy to measure the dissimilarity between hypotheses which alleviates instability during adversarial learning. Extensive empirical evidence shows that our proposal outperforms related approaches in image classification error rates on standard domain adaptation benchmarks.
Revisiting Fine-tuning for Few-shot Learning
Oct 03, 2019
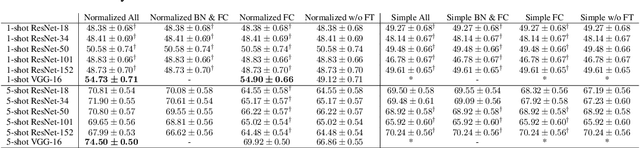
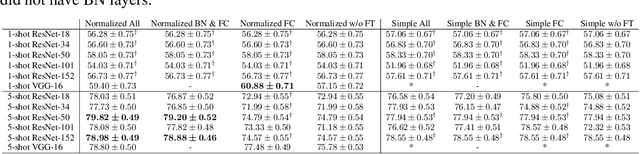
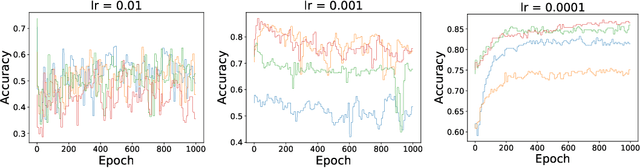
Few-shot learning is the process of learning novel classes using only a few examples and it remains a challenging task in machine learning. Many sophisticated few-shot learning algorithms have been proposed based on the notion that networks can easily overfit to novel examples if they are simply fine-tuned using only a few examples. In this study, we show that in the commonly used low-resolution mini-ImageNet dataset, the fine-tuning method achieves higher accuracy than common few-shot learning algorithms in the 1-shot task and nearly the same accuracy as that of the state-of-the-art algorithm in the 5-shot task. We then evaluate our method with more practical tasks, namely the high-resolution single-domain and cross-domain tasks. With both tasks, we show that our method achieves higher accuracy than common few-shot learning algorithms. We further analyze the experimental results and show that: 1) the retraining process can be stabilized by employing a low learning rate, 2) using adaptive gradient optimizers during fine-tuning can increase test accuracy, and 3) test accuracy can be improved by updating the entire network when a large domain-shift exists between base and novel classes.