 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaintNet: 3D Learning of Pose Paths Generators for Robotic Spray Painting
Nov 13, 2022Optimization and planning methods for tasks involving 3D objects often rely on prior knowledge and ad-hoc heuristics. In this work, we target learning-based long-horizon path generation by leveraging recent advances in 3D deep learning. We present PaintNet, the first dataset for learning robotic spray painting of free-form 3D objects. PaintNet includes more than 800 object meshes and the associated painting strokes collected in a real industrial setting. We then introduce a novel 3D deep learning method to tackle this task and operate on unstructured input spaces -- point clouds -- and mix-structured output spaces -- unordered sets of painting strokes. Our extensive experimental analysis demonstrates the capabilities of our method to predict smooth output strokes that cover up to 95% of previously unseen object surfaces, with respect to ground-truth paint coverage. The PaintNet dataset and an implementation of our proposed approach will be released at https://gabrieletiboni.github.io/paintnet.
Towards Open Set 3D Learning: A Benchmark on Object Point Clouds
Jul 23, 2022
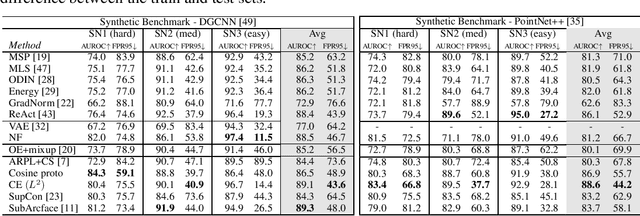


In the last years, there has been significant progress in the field of 3D learning on classification, detection and segmentation problems. The vast majority of the existing studies focus on canonical closed-set conditions, neglecting the intrinsic open nature of the real-world. This limits the abilities of autonomous systems involved in safety-critical applications that require managing novel and unknown signals. In this context exploiting 3D data can be a valuable asset since it conveys rich information about the geometry of sensed objects and scenes. This paper provides the first broad study on Open Set 3D learning. We introduce a novel testbed with settings of increasing difficulty in terms of category semantic shift and cover both in-domain (synthetic-to-synthetic) and cross-domain (synthetic-to-real) scenarios. Moreover, we investigate the related out-of-distribution and Open Set 2D literature to understand if and how their most recent approaches are effective on 3D data. Our extensive benchmark positions several algorithms in the same coherent picture, revealing their strengths and limitations. The results of our analysis may serve as a reliable foothold for future tailored Open Set 3D models.
Semantic Novelty Detection via Relational Reasoning
Jul 18, 2022
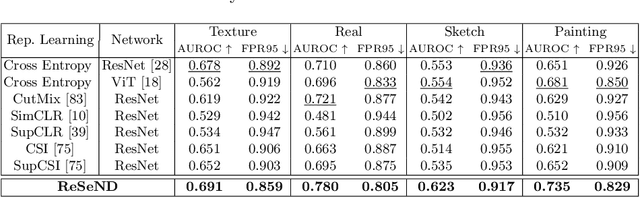
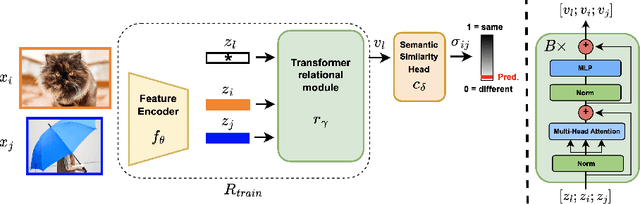
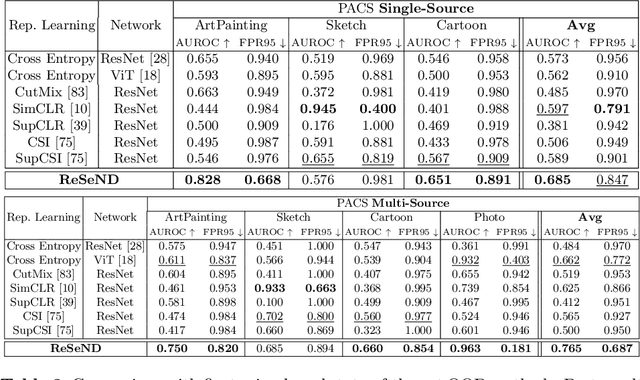
Semantic novelty detection aims at discovering unknown categories in the test data. This task is particularly relevant in safety-critical applications, such as autonomous driving or healthcare, where it is crucial to recognize unknown objects at deployment time and issue a warning to the user accordingly. Despite the impressive advancements of deep learning research, existing models still need a finetuning stage on the known categories in order to recognize the unknown ones. This could be prohibitive when privacy rules limit data access, or in case of strict memory and computational constraints (e.g. edge computing). We claim that a tailored representation learning strategy may be the right solution for effective and efficient semantic novelty detection. Besides extensively testing state-of-the-art approaches for this task, we propose a novel representation learning paradigm based on relational reasoning. It focuses on learning how to measure semantic similarity rather than recognizing known categories. Our experiments show that this knowledge is directly transferable to a wide range of scenarios, and it can be exploited as a plug-and-play module to convert closed-set recognition models into reliable open-set ones.
Online vs. Offline Adaptive Domain Randomization Benchmark
Jun 29, 2022

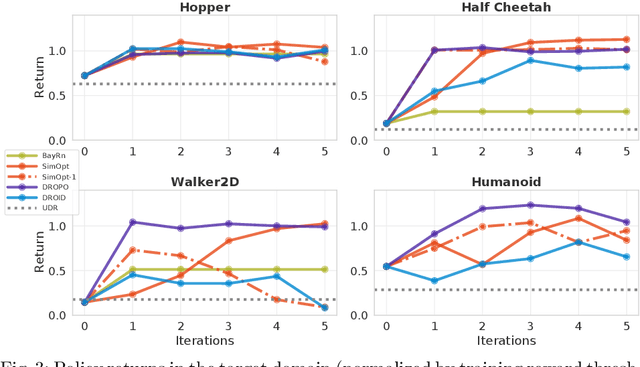
Physics simulators have shown great promise for conveniently learning reinforcement learning policies in safe, unconstrained environments. However, transferring the acquired knowledge to the real world can be challenging due to the reality gap. To this end, several methods have been recently proposed to automatically tune simulator parameters with posterior distributions given real data, for use with domain randomization at training time. These approaches have been shown to work for various robotic tasks under different settings and assumptions. Nevertheless, existing literature lacks a thorough comparison of existing adaptive domain randomization methods with respect to transfer performance and real-data efficiency. In this work, we present an open benchmark for both offline and online methods (SimOpt, BayRn, DROID, DROPO), to shed light on which are most suitable for each setting and task at hand. We found that online methods are limited by the quality of the currently learned policy for the next iteration, while offline methods may sometimes fail when replaying trajectories in simulation with open-loop commands. The code used will be released at https://github.com/gabrieletiboni/adr-benchmark.
Fault-Aware Design and Training to Enhance DNNs Reliability with Zero-Overhead
May 28, 2022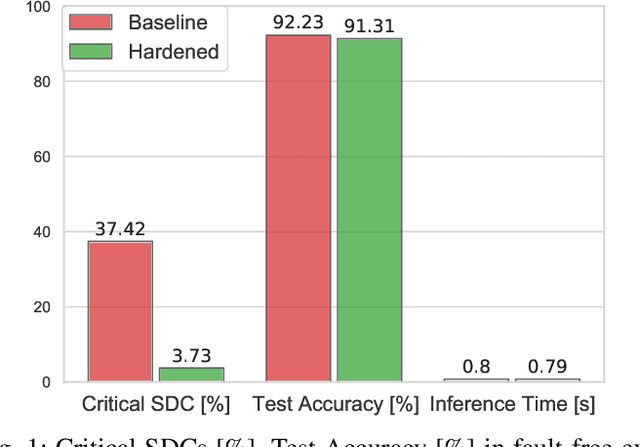
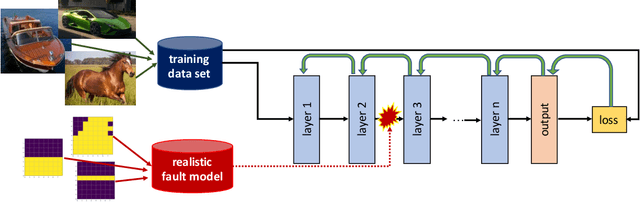
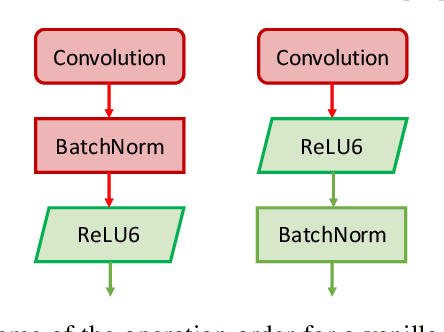
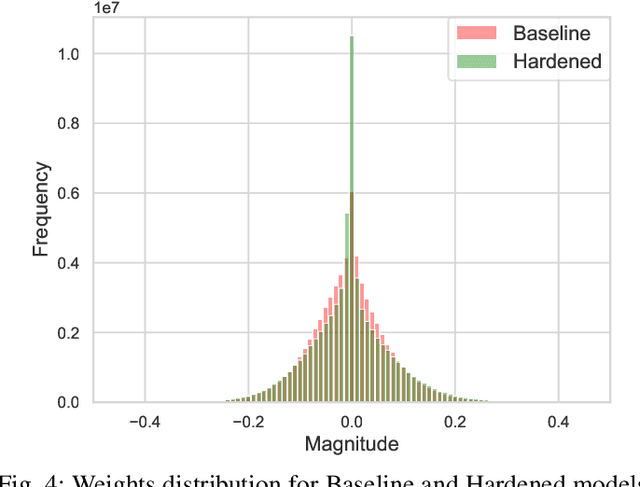
Deep Neural Networks (DNNs) enable a wide series of technological advancements, ranging from clinical imaging, to predictive industrial maintenance and autonomous driving. However, recent findings indicate that transient hardware faults may corrupt the models prediction dramatically. For instance, the radiation-induced misprediction probability can be so high to impede a safe deployment of DNNs models at scale, urging the need for efficient and effective hardening solutions. In this work, we propose to tackle the reliability issue both at training and model design time. First, we show that vanilla models are highly affected by transient faults, that can induce a performances drop up to 37%. Hence, we provide three zero-overhead solutions, based on DNN re-design and re-train, that can improve DNNs reliability to transient faults up to one order of magnitude. We complement our work with extensive ablation studies to quantify the gain in performances of each hardening component.
Contrastive Learning for Cross-Domain Open World Recognition
Mar 17, 2022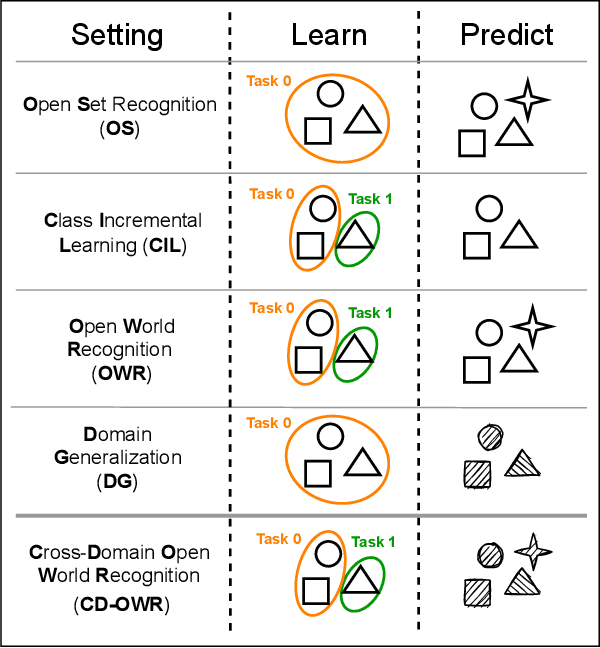
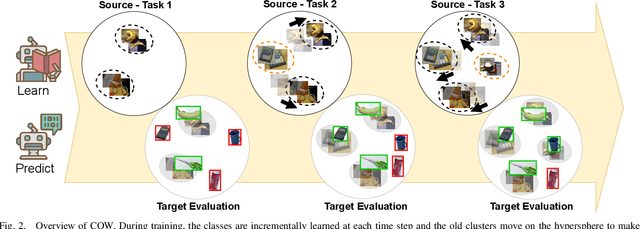
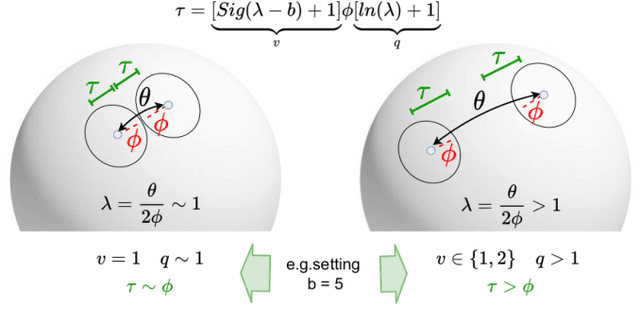
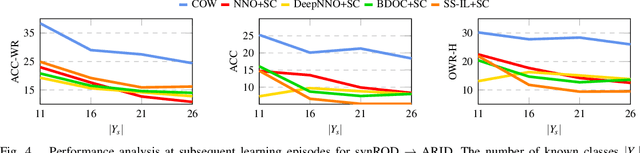
The ability to evolve is fundamental for any valuable autonomous agent whose knowledge cannot remain limited to that injected by the manufacturer. Consider for example a home assistant robot: it should be able to incrementally learn new object categories when requested, but also to recognize the same objects in different environments (rooms) and poses (hand-held/on the floor/above furniture), while rejecting unknown ones. Despite its importance, this scenario has started to raise interest in the robotic community only recently and the related research is still in its infancy, with existing experimental testbeds but no tailored methods. With this work, we propose the first learning approach that deals with all the previously mentioned challenges at once by exploiting a single contrastive objective. We show how it learns a feature space perfectly suitable to incrementally include new classes and is able to capture knowledge which generalizes across a variety of visual domains. Our method is endowed with a tailored effective stopping criterion for each learning episode and exploits a novel self-paced thresholding strategy that provides the classifier with a reliable rejection option. Both these contributions are based on the observation of the data statistics and do not need manual tuning. An extensive experimental analysis confirms the effectiveness of the proposed approach establishing the new state-of-the-art. The code is available at https://github.com/FrancescoCappio/Contrastive_Open_World.
End-to-End Learning to Grasp from Object Point Clouds
Mar 10, 2022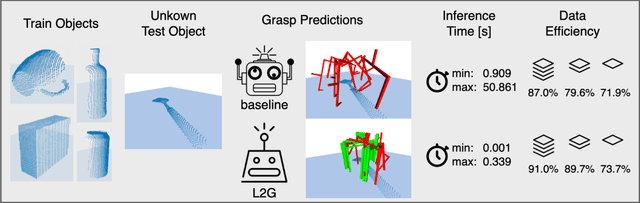
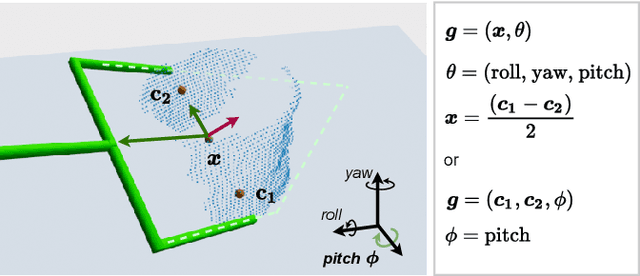
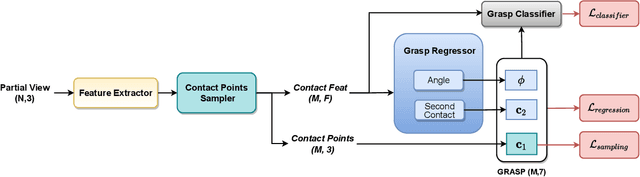
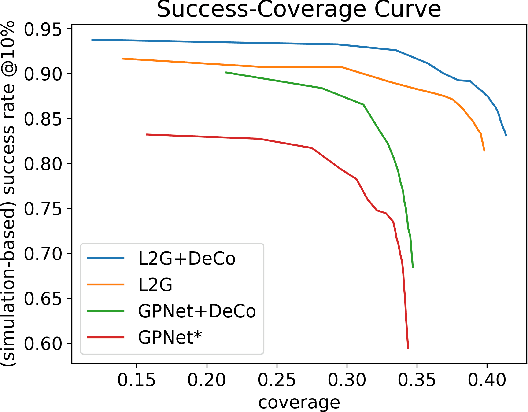
The ability to grasp objects is an essential skill that enables many robotic manipulation tasks. Recent works have studied point cloud-based methods for object grasping by starting from simulated datasets and have shown promising performance in real-world scenarios. Nevertheless, many of them still strongly rely on ad-hoc geometric heuristics to generate grasp candidates, which fail to generalize to objects with significantly different shapes with respect to those observed during training. Moreover, these methods are generally inefficient with respect to the number of training samples and the time needed during deployment. In this paper, we propose an end-to-end learning solution to generate 6-DOF parallel-jaw grasps starting from the partial view of the object. Our Learning to Grasp (L2G) method takes as input object point clouds and is guided by a principled multi-task optimization objective that generates a diverse set of grasps combining contact point sampling, grasp regression, and grasp evaluation. With a thorough experimental analysis, we show the effectiveness of the proposed method as well as its robustness and generalization abilities.
Distance-based Hyperspherical Classification for Multi-source Open-Set Domain Adaptation
Jul 14, 2021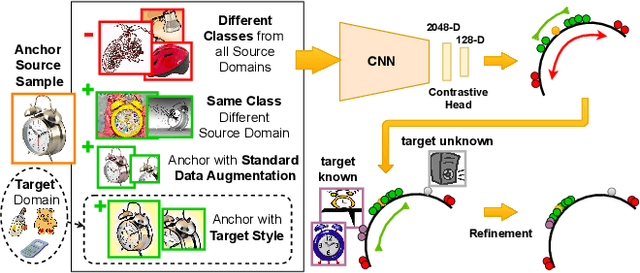
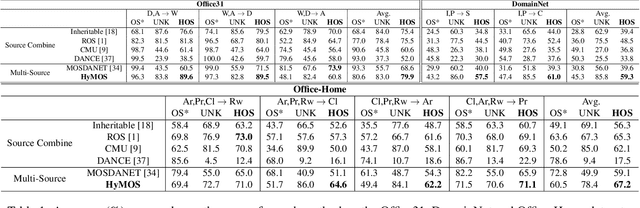
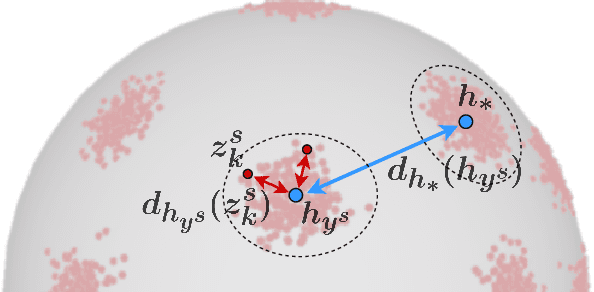
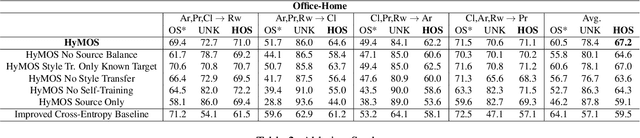
Vision systems trained in closed-world scenarios will inevitably fail when presented with new environmental conditions, new data distributions and novel classes at deployment time. How to move towards open-world learning is a long standing research question, but the existing solutions mainly focus on specific aspects of the problem (single domain Open-Set, multi-domain Closed-Set), or propose complex strategies which combine multiple losses and manually tuned hyperparameters. In this work we tackle multi-source Open-Set domain adaptation by introducing HyMOS: a straightforward supervised model that exploits the power of contrastive learning and the properties of its hyperspherical feature space to correctly predict known labels on the target, while rejecting samples belonging to any unknown class. HyMOS includes a tailored data balancing to enforce cross-source alignment and introduces style transfer among the instance transformations of contrastive learning for source-target adaptation, avoiding the risk of negative transfer. Finally a self-training strategy refines the model without the need for handcrafted thresholds. We validate our method over three challenging datasets and provide an extensive quantitative and qualitative experimental analysis. The obtained results show that HyMOS outperforms several Open-Set and universal domain adaptation approaches, defining the new state-of-the-art.
Towards Fairness Certification in Artificial Intelligence
Jun 04, 2021Thanks to the great progress of machine learning in the last years, several Artificial Intelligence (AI) techniques have been increasingly moving from the controlled research laboratory settings to our everyday life. AI is clearly supportive in many decision-making scenarios, but when it comes to sensitive areas such as health care, hiring policies, education, banking or justice, with major impact on individuals and society, it becomes crucial to establish guidelines on how to design, develop, deploy and monitor this technology. Indeed the decision rules elaborated by machine learning models are data-driven and there are multiple ways in which discriminatory biases can seep into data. Algorithms trained on those data incur the risk of amplifying prejudices and societal stereotypes by over associating protected attributes such as gender, ethnicity or disabilities with the prediction task. Starting from the extensive experience of the National Metrology Institute on measurement standards and certification roadmaps, and of Politecnico di Torino on machine learning as well as methods for domain bias evaluation and mastering, we propose a first joint effort to define the operational steps needed for AI fairness certification. Specifically we will overview the criteria that should be met by an AI system before coming into official service and the conformity assessment procedures useful to monitor its functioning for fair decisions.
Denoise and Contrast for Category Agnostic Shape Completion
Mar 30, 2021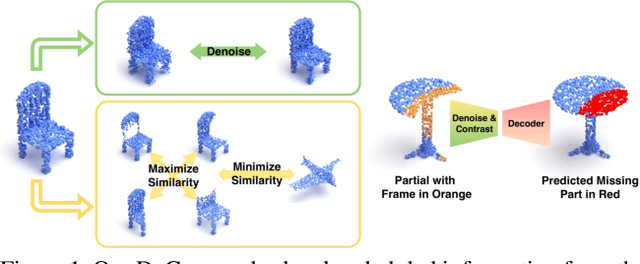
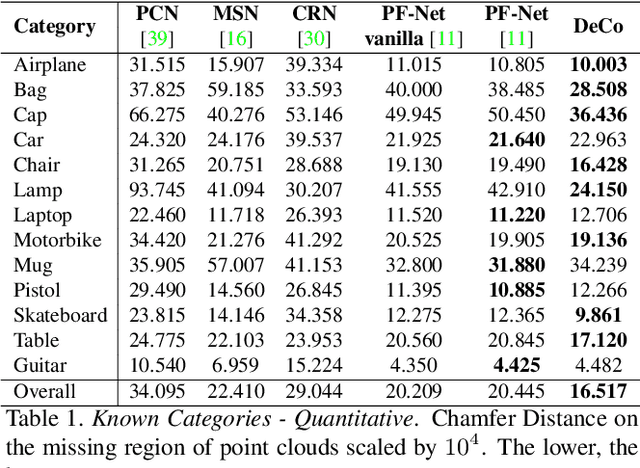
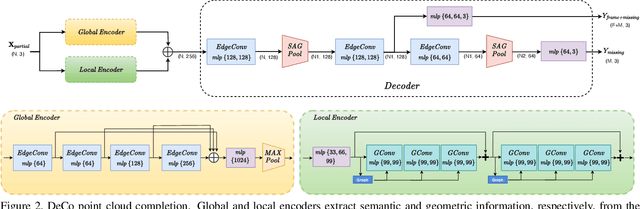
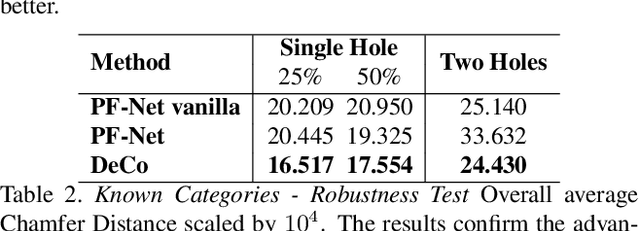
In this paper, we present a deep learning model that exploits the power of self-supervision to perform 3D point cloud completion, estimating the missing part and a context region around it. Local and global information are encoded in a combined embedding. A denoising pretext task provides the network with the needed local cues, decoupled from the high-level semantics and naturally shared over multiple classes. On the other hand, contrastive learning maximizes the agreement between variants of the same shape with different missing portions, thus producing a representation which captures the global appearance of the shape. The combined embedding inherits category-agnostic properties from the chosen pretext tasks. Differently from existing approaches, this allows to better generalize the completion properties to new categories unseen at training time. Moreover, while decoding the obtained joint representation, we better blend the reconstructed missing part with the partial shape by paying attention to its known surrounding region and reconstructing this frame as auxiliary objective. Our extensive experiments and detailed ablation on the ShapeNet dataset show the effectiveness of each part of the method with new state of the art results. Our quantitative and qualitative analysis confirms how our approach is able to work on novel categories without relying neither on classification and shape symmetry priors, nor on adversarial training procedures.