 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompletely random measures for modeling power laws in sparse graphs
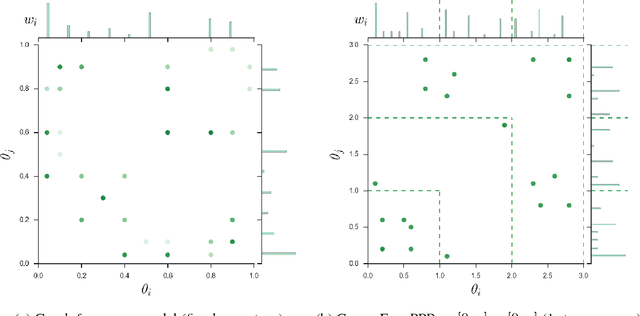
Mar 22, 2016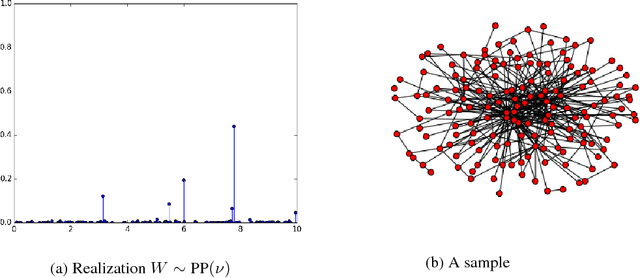
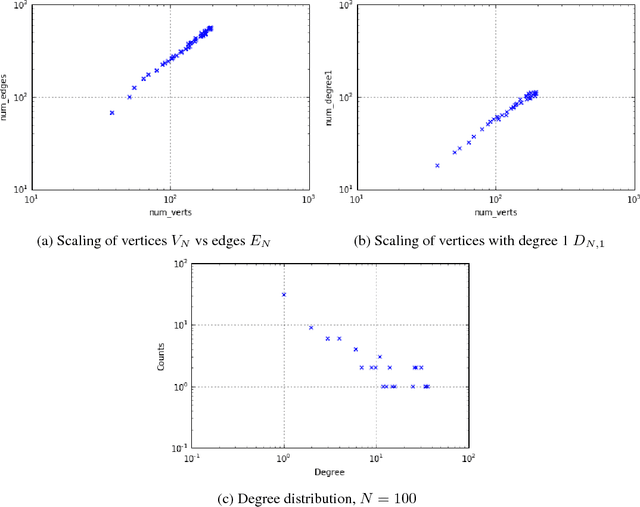
Network data appear in a number of applications, such as online social networks and biological networks, and there is growing interest in both developing models for networks as well as studying the properties of such data. Since individual network datasets continue to grow in size, it is necessary to develop models that accurately represent the real-life scaling properties of networks. One behavior of interest is having a power law in the degree distribution. However, other types of power laws that have been observed empirically and considered for applications such as clustering and feature allocation models have not been studied as frequently in models for graph data. In this paper, we enumerate desirable asymptotic behavior that may be of interest for modeling graph data, including sparsity and several types of power laws. We outline a general framework for graph generative models using completely random measures; by contrast to the pioneering work of Caron and Fox (2015), we consider instantiating more of the existing atoms of the random measure as the dataset size increases rather than adding new atoms to the measure. We see that these two models can be complementary; they respectively yield interpretations as (1) time passing among existing members of a network and (2) new individuals joining a network. We detail a particular instance of this framework and show simulated results that suggest this model exhibits some desirable asymptotic power-law behavior.
Edge-exchangeable graphs and sparsity
Mar 22, 2016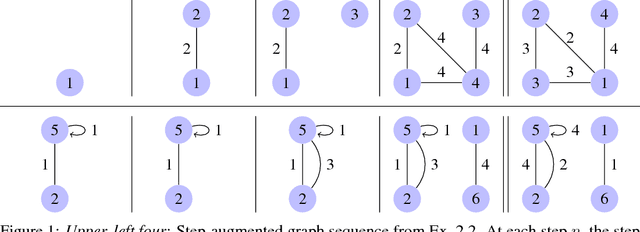
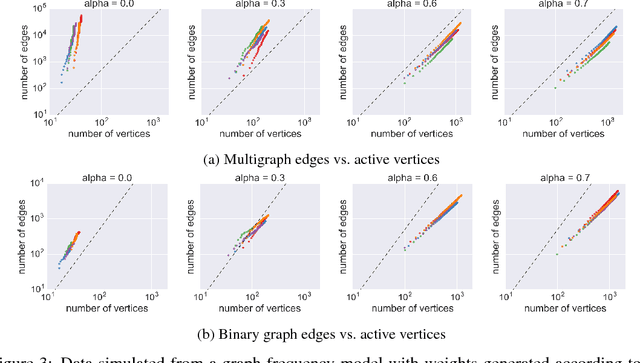
A known failing of many popular random graph models is that the Aldous-Hoover Theorem guarantees these graphs are dense with probability one; that is, the number of edges grows quadratically with the number of nodes. This behavior is considered unrealistic in observed graphs. We define a notion of edge exchangeability for random graphs in contrast to the established notion of infinite exchangeability for random graphs --- which has traditionally relied on exchangeability of nodes (rather than edges) in a graph. We show that, unlike node exchangeability, edge exchangeability encompasses models that are known to provide a projective sequence of random graphs that circumvent the Aldous-Hoover Theorem and exhibit sparsity, i.e., sub-quadratic growth of the number of edges with the number of nodes. We show how edge-exchangeability of graphs relates naturally to existing notions of exchangeability from clustering (a.k.a. partitions) and other familiar combinatorial structures.
Linear Response Methods for Accurate Covariance Estimates from Mean Field Variational Bayes
Dec 23, 2015


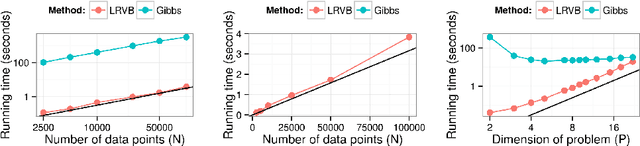
Mean field variational Bayes (MFVB) is a popular posterior approximation method due to its fast runtime on large-scale data sets. However, it is well known that a major failing of MFVB is that it underestimates the uncertainty of model variables (sometimes severely) and provides no information about model variable covariance. We generalize linear response methods from statistical physics to deliver accurate uncertainty estimates for model variables---both for individual variables and coherently across variables. We call our method linear response variational Bayes (LRVB). When the MFVB posterior approximation is in the exponential family, LRVB has a simple, analytic form, even for non-conjugate models. Indeed, we make no assumptions about the form of the true posterior. We demonstrate the accuracy and scalability of our method on a range of models for both simulated and real data.
Covariance Matrices and Influence Scores for Mean Field Variational Bayes
Feb 26, 2015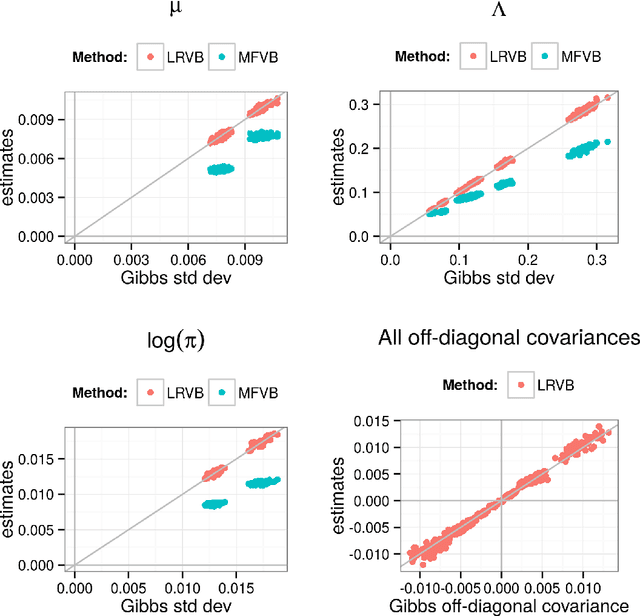
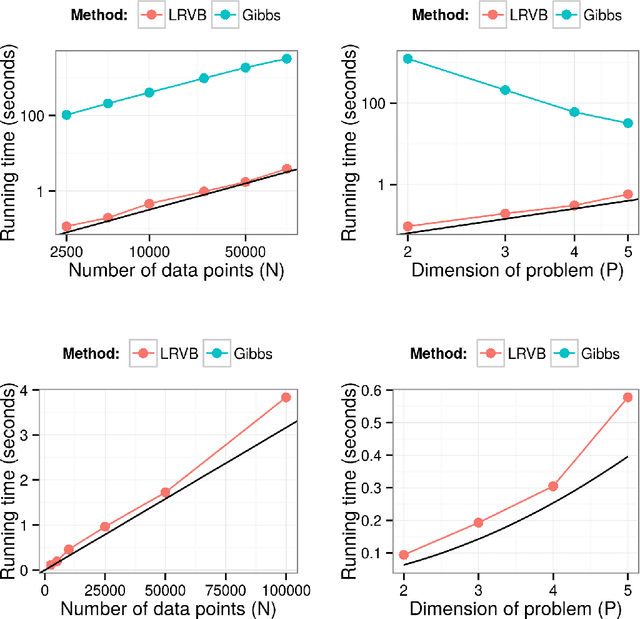
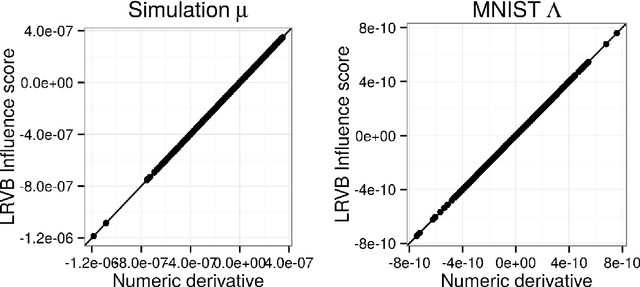
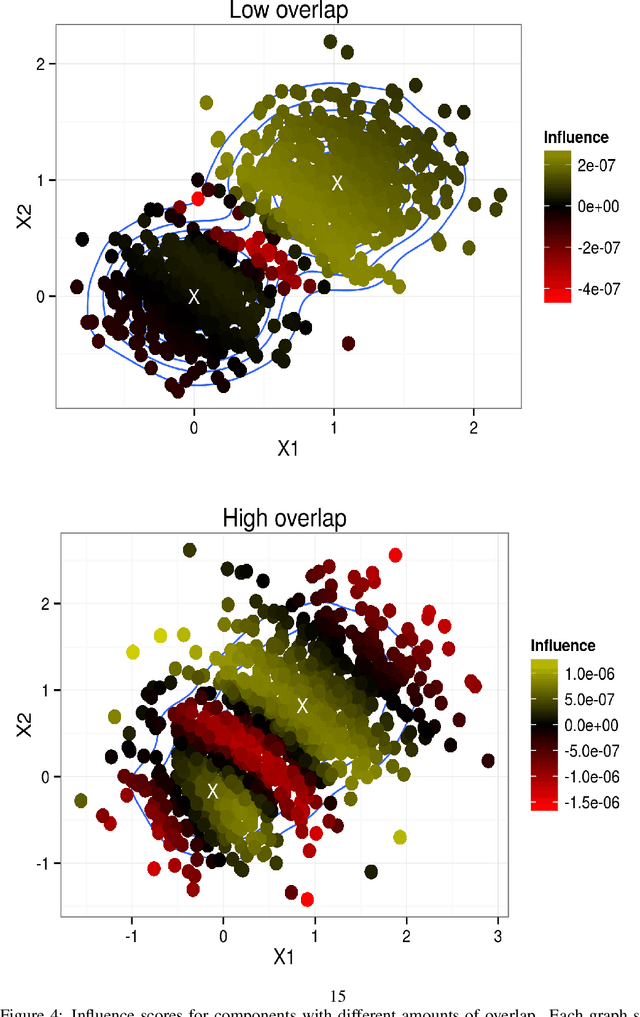
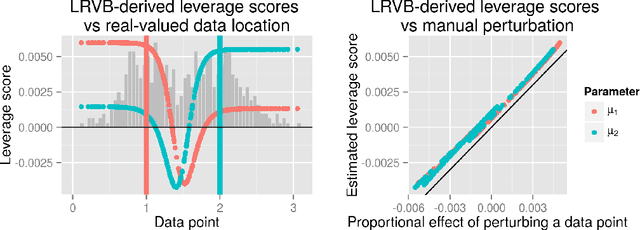
Mean field variational Bayes (MFVB) is a popular posterior approximation method due to its fast runtime on large-scale data sets. However, it is well known that a major failing of MFVB is that it underestimates the uncertainty of model variables (sometimes severely) and provides no information about model variable covariance. We develop a fast, general methodology for exponential families that augments MFVB to deliver accurate uncertainty estimates for model variables -- both for individual variables and coherently across variables. MFVB for exponential families defines a fixed-point equation in the means of the approximating posterior, and our approach yields a covariance estimate by perturbing this fixed point. Inspired by linear response theory, we call our method linear response variational Bayes (LRVB). We also show how LRVB can be used to quickly calculate a measure of the influence of individual data points on parameter point estimates. We demonstrate the accuracy and scalability of our method by learning Gaussian mixture models for both simulated and real data.
Covariance Matrices for Mean Field Variational Bayes
Dec 08, 2014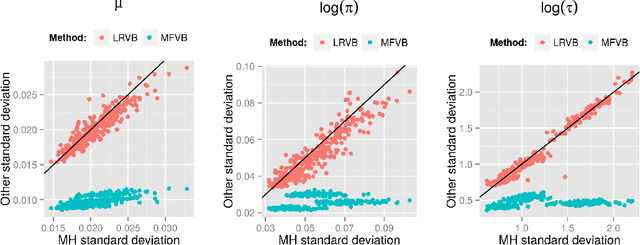
Mean Field Variational Bayes (MFVB) is a popular posterior approximation method due to its fast runtime on large-scale data sets. However, it is well known that a major failing of MFVB is its (sometimes severe) underestimates of the uncertainty of model variables and lack of information about model variable covariance. We develop a fast, general methodology for exponential families that augments MFVB to deliver accurate uncertainty estimates for model variables -- both for individual variables and coherently across variables. MFVB for exponential families defines a fixed-point equation in the means of the approximating posterior, and our approach yields a covariance estimate by perturbing this fixed point. Inspired by linear response theory, we call our method linear response variational Bayes (LRVB). We demonstrate the accuracy of our method on simulated data sets.
Variational Bayes for Merging Noisy Databases
Oct 17, 2014Bayesian entity resolution merges together multiple, noisy databases and returns the minimal collection of unique individuals represented, together with their true, latent record values. Bayesian methods allow flexible generative models that share power across databases as well as principled quantification of uncertainty for queries of the final, resolved database. However, existing Bayesian methods for entity resolution use Markov monte Carlo method (MCMC) approximations and are too slow to run on modern databases containing millions or billions of records. Instead, we propose applying variational approximations to allow scalable Bayesian inference in these models. We derive a coordinate-ascent approximation for mean-field variational Bayes, qualitatively compare our algorithm to existing methods, note unique challenges for inference that arise from the expected distribution of cluster sizes in entity resolution, and discuss directions for future work in this domain.
Streaming Variational Bayes
Nov 20, 2013

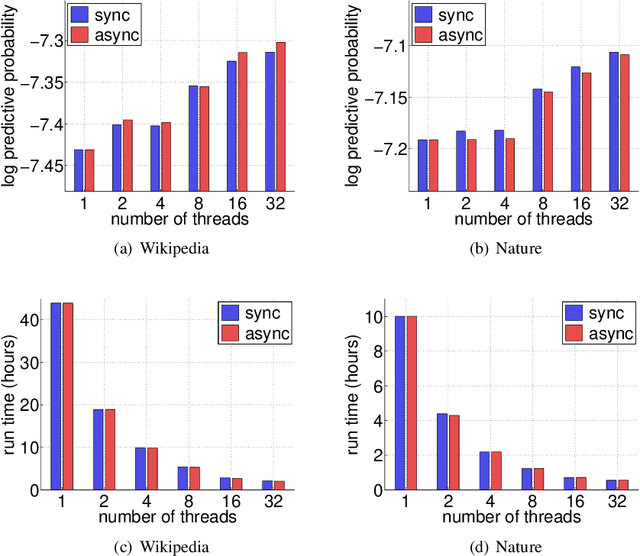
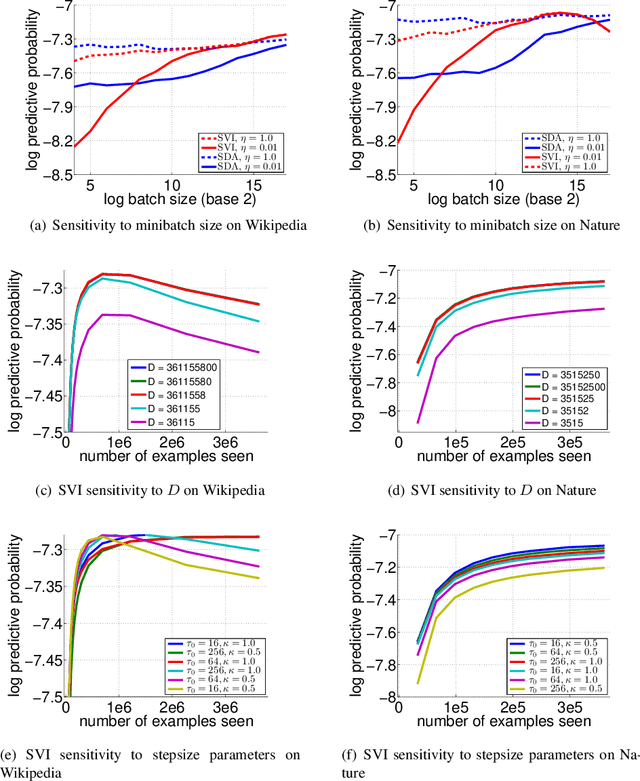
We present SDA-Bayes, a framework for (S)treaming, (D)istributed, (A)synchronous computation of a Bayesian posterior. The framework makes streaming updates to the estimated posterior according to a user-specified approximation batch primitive. We demonstrate the usefulness of our framework, with variational Bayes (VB) as the primitive, by fitting the latent Dirichlet allocation model to two large-scale document collections. We demonstrate the advantages of our algorithm over stochastic variational inference (SVI) by comparing the two after a single pass through a known amount of data---a case where SVI may be applied---and in the streaming setting, where SVI does not apply.
Optimistic Concurrency Control for Distributed Unsupervised Learning
Jul 30, 2013

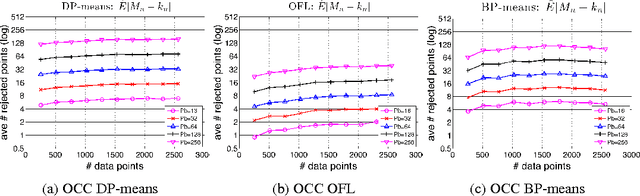
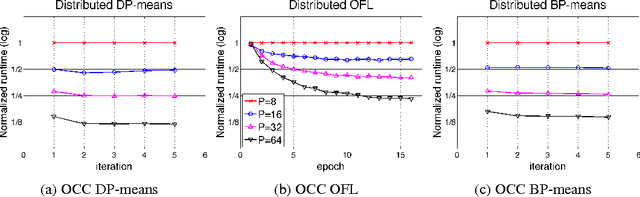
Research on distributed machine learning algorithms has focused primarily on one of two extremes - algorithms that obey strict concurrency constraints or algorithms that obey few or no such constraints. We consider an intermediate alternative in which algorithms optimistically assume that conflicts are unlikely and if conflicts do arise a conflict-resolution protocol is invoked. We view this "optimistic concurrency control" paradigm as particularly appropriate for large-scale machine learning algorithms, particularly in the unsupervised setting. We demonstrate our approach in three problem areas: clustering, feature learning and online facility location. We evaluate our methods via large-scale experiments in a cluster computing environment.
Combinatorial clustering and the beta negative binomial process
Jun 10, 2013
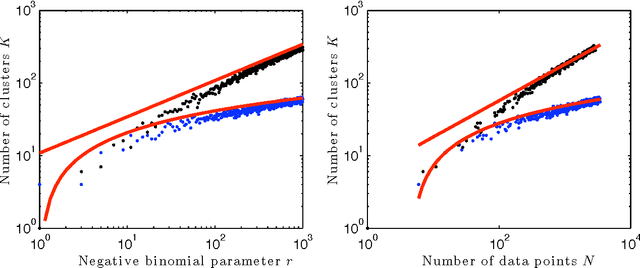
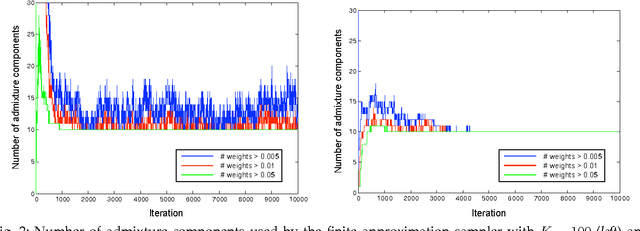

We develop a Bayesian nonparametric approach to a general family of latent class problems in which individuals can belong simultaneously to multiple classes and where each class can be exhibited multiple times by an individual. We introduce a combinatorial stochastic process known as the negative binomial process (NBP) as an infinite-dimensional prior appropriate for such problems. We show that the NBP is conjugate to the beta process, and we characterize the posterior distribution under the beta-negative binomial process (BNBP) and hierarchical models based on the BNBP (the HBNBP). We study the asymptotic properties of the BNBP and develop a three-parameter extension of the BNBP that exhibits power-law behavior. We derive MCMC algorithms for posterior inference under the HBNBP, and we present experiments using these algorithms in the domains of image segmentation, object recognition, and document analysis.
MAD-Bayes: MAP-based Asymptotic Derivations from Bayes
Feb 15, 2013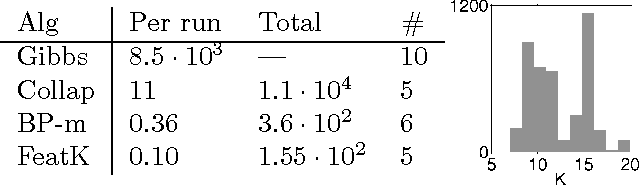


The classical mixture of Gaussians model is related to K-means via small-variance asymptotics: as the covariances of the Gaussians tend to zero, the negative log-likelihood of the mixture of Gaussians model approaches the K-means objective, and the EM algorithm approaches the K-means algorithm. Kulis & Jordan (2012) used this observation to obtain a novel K-means-like algorithm from a Gibbs sampler for the Dirichlet process (DP) mixture. We instead consider applying small-variance asymptotics directly to the posterior in Bayesian nonparametric models. This framework is independent of any specific Bayesian inference algorithm, and it has the major advantage that it generalizes immediately to a range of models beyond the DP mixture. To illustrate, we apply our framework to the feature learning setting, where the beta process and Indian buffet process provide an appropriate Bayesian nonparametric prior. We obtain a novel objective function that goes beyond clustering to learn (and penalize new) groupings for which we relax the mutual exclusivity and exhaustivity assumptions of clustering. We demonstrate several other algorithms, all of which are scalable and simple to implement. Empirical results demonstrate the benefits of the new framework.