 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneGlue: Scene-Aware Transformer for Feature Matching without Scene-Level Annotation
Apr 15, 2026Local feature matching plays a critical role in understanding the correspondence between cross-view images. However, traditional methods are constrained by the inherent local nature of feature descriptors, limiting their ability to capture non-local scene information that is essential for accurate cross-view correspondence. In this paper, we introduce SceneGlue, a scene-aware feature matching framework designed to overcome these limitations. SceneGlue leverages a hybridizable matching paradigm that integrates implicit parallel attention and explicit cross-view visibility estimation. The parallel attention mechanism simultaneously exchanges information among local descriptors within and across images, enhancing the scene's global context. To further enrich the scene awareness, we propose the Visibility Transformer, which explicitly categorizes features into visible and invisible regions, providing an understanding of cross-view scene visibility. By combining explicit and implicit scene-level awareness, SceneGlue effectively compensates for the local descriptor constraints. Notably, SceneGlue is trained using only local feature matches, without requiring scene-level groundtruth annotations. This scene-aware approach not only improves accuracy and robustness but also enhances interpretability compared to traditional methods. Extensive experiments on applications such as homography estimation, pose estimation, image matching, and visual localization validate SceneGlue's superior performance. The source code is available at https://github.com/songlin-du/SceneGlue.
Self-Supervision and Spatial-Sequential Attention Based Loss for Multi-Person Pose Estimation
Oct 20, 2021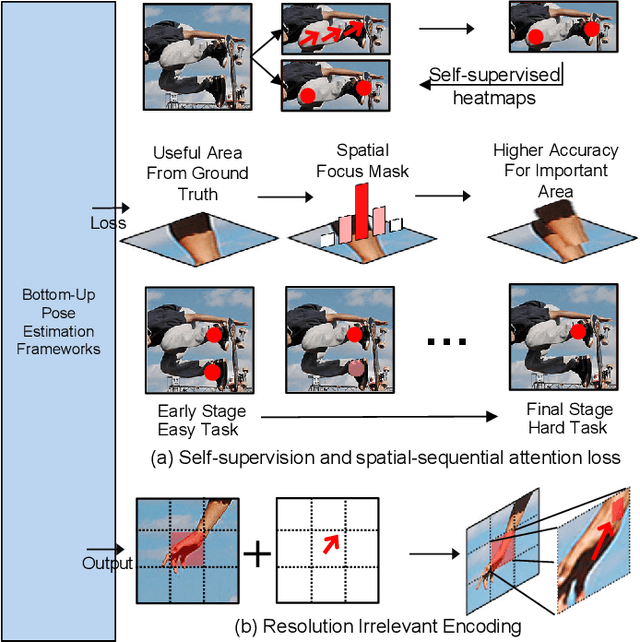
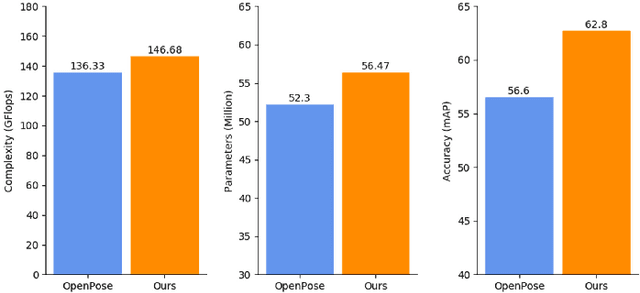


Bottom-up based multi-person pose estimation approaches use heatmaps with auxiliary predictions to estimate joint positions and belonging at one time. Recently, various combinations between auxiliary predictions and heatmaps have been proposed for higher performance, these predictions are supervised by the corresponding L2 loss function directly. However, the lack of more explicit supervision results in low features utilization and contradictions between predictions in one model. To solve these problems, this paper proposes (i) a new loss organization method which uses self-supervised heatmaps to reduce prediction contradictions and spatial-sequential attention to enhance networks' features extraction; (ii) a new combination of predictions composed by heatmaps, Part Affinity Fields (PAFs) and our block-inside offsets to fix pixel-level joints positions and further demonstrates the effectiveness of proposed loss function. Experiments are conducted on the MS COCO keypoint dataset and adopting OpenPose as the baseline model. Our method outperforms the baseline overall. On the COCO verification dataset, the mAP of OpenPose trained with our proposals outperforms the OpenPose baseline by over 5.5%.