 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Temporally Dynamic Data Augmentation for Video Recognition
Jun 30, 2022
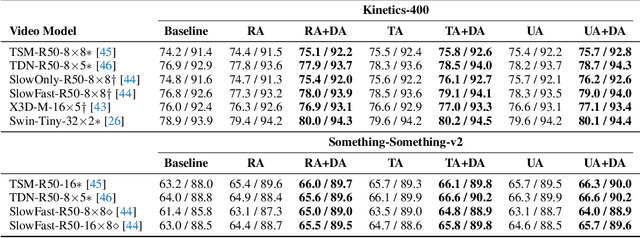
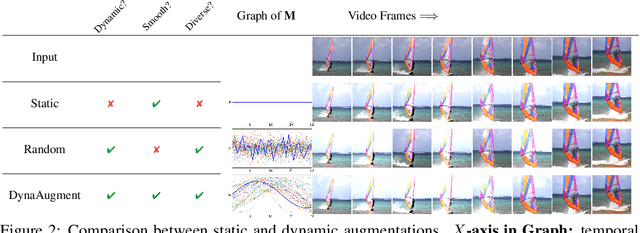

Data augmentation has recently emerged as an essential component of modern training recipes for visual recognition tasks. However, data augmentation for video recognition has been rarely explored despite its effectiveness. Few existing augmentation recipes for video recognition naively extend the image augmentation methods by applying the same operations to the whole video frames. Our main idea is that the magnitude of augmentation operations for each frame needs to be changed over time to capture the real-world video's temporal variations. These variations should be generated as diverse as possible using fewer additional hyper-parameters during training. Through this motivation, we propose a simple yet effective video data augmentation framework, DynaAugment. The magnitude of augmentation operations on each frame is changed by an effective mechanism, Fourier Sampling that parameterizes diverse, smooth, and realistic temporal variations. DynaAugment also includes an extended search space suitable for video for automatic data augmentation methods. DynaAugment experimentally demonstrates that there are additional performance rooms to be improved from static augmentations on diverse video models. Specifically, we show the effectiveness of DynaAugment on various video datasets and tasks: large-scale video recognition (Kinetics-400 and Something-Something-v2), small-scale video recognition (UCF- 101 and HMDB-51), fine-grained video recognition (Diving-48 and FineGym), video action segmentation on Breakfast, video action localization on THUMOS'14, and video object detection on MOT17Det. DynaAugment also enables video models to learn more generalized representation to improve the model robustness on the corrupted videos.
Spatiotemporal Augmentation on Selective Frequencies for Video Representation Learning
Apr 08, 2022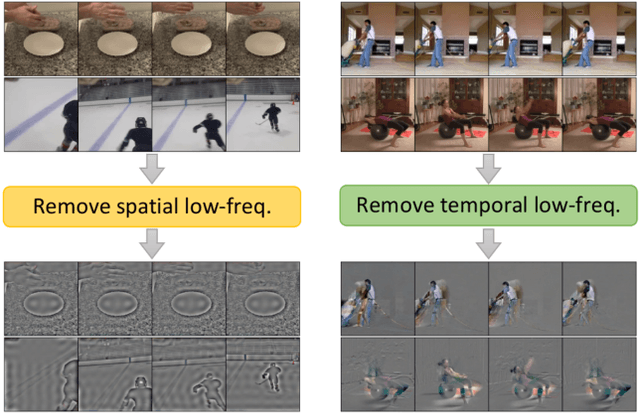
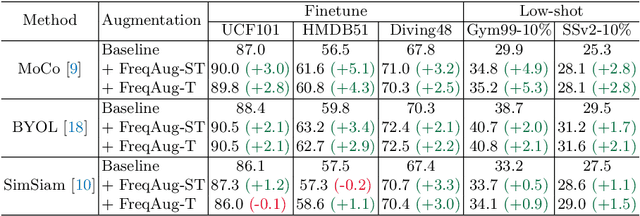
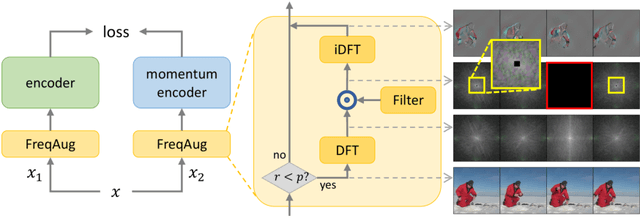
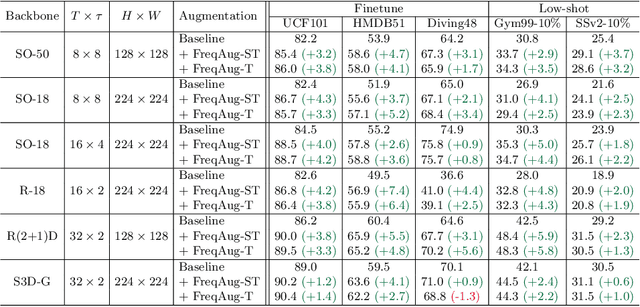
Recent self-supervised video representation learning methods focus on maximizing the similarity between multiple augmented views from the same video and largely rely on the quality of generated views. In this paper, we propose frequency augmentation (FreqAug), a spatio-temporal data augmentation method in the frequency domain for video representation learning. FreqAug stochastically removes undesirable information from the video by filtering out specific frequency components so that learned representation captures essential features of the video for various downstream tasks. Specifically, FreqAug pushes the model to focus more on dynamic features rather than static features in the video via dropping spatial or temporal low-frequency components. In other words, learning invariance between remaining frequency components results in high-frequency enhanced representation with less static bias. To verify the generality of the proposed method, we experiment with FreqAug on multiple self-supervised learning frameworks along with standard augmentations. Transferring the improved representation to five video action recognition and two temporal action localization downstream tasks shows consistent improvements over baselines.
Test-Time Adaptation for Out-of-distributed Image Inpainting
Feb 02, 2021
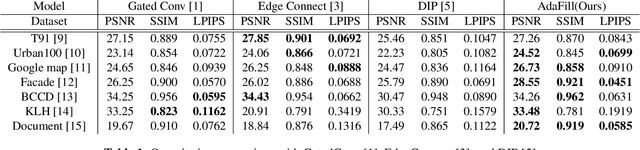
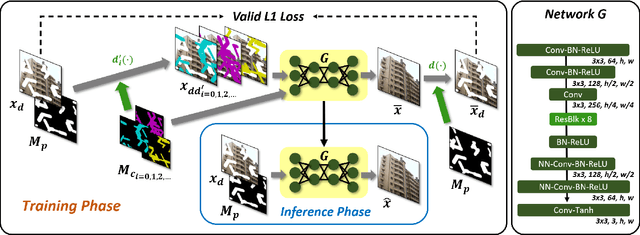
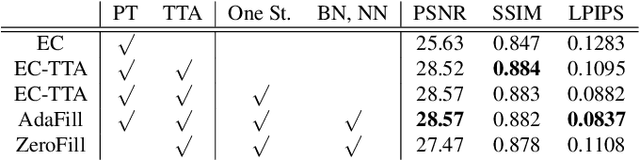
Deep learning-based image inpainting algorithms have shown great performance via powerful learned prior from the numerous external natural images. However, they show unpleasant results on the test image whose distribution is far from the that of training images because their models are biased toward the training images. In this paper, we propose a simple image inpainting algorithm with test-time adaptation named AdaFill. Given a single out-of-distributed test image, our goal is to complete hole region more naturally than the pre-trained inpainting models. To achieve this goal, we treat remained valid regions of the test image as another training cues because natural images have strong internal similarities. From this test-time adaptation, our network can exploit externally learned image priors from the pre-trained features as well as the internal prior of the test image explicitly. Experimental results show that AdaFill outperforms other models on the various out-of-distribution test images. Furthermore, the model named ZeroFill, that are not pre-trained also sometimes outperforms the pre-trained models.
Unsupervised Video Anomaly Detection via Flow-based Generative Modeling on Appearance and Motion Latent Features
Oct 15, 2020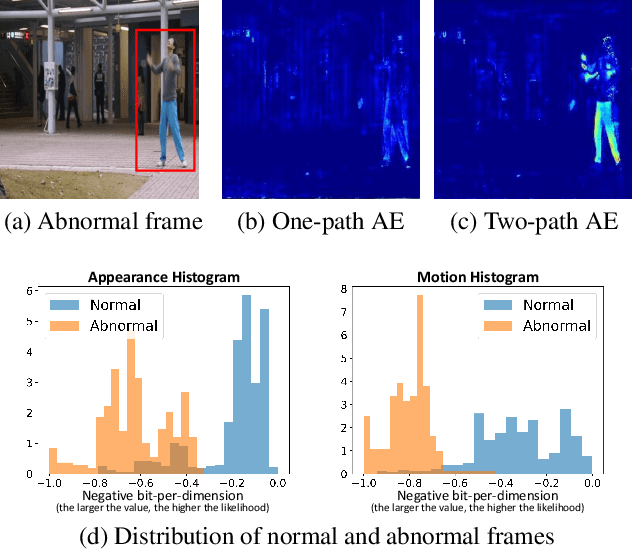
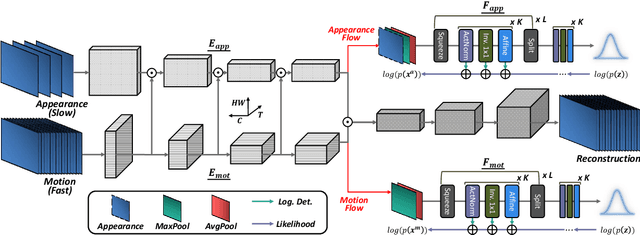
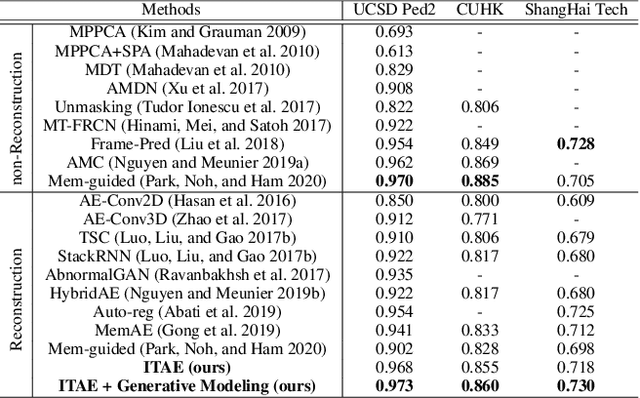
Surveillance video anomaly detection searches for anomalous events such as crimes or accidents among normal scenes. Since anomalous events occur rarely, there is a class imbalance problem between normal and abnormal data and it is impossible to collect all potential anomalous events, which makes the task challenging. Therefore, performing anomaly detection requires learning the patterns of normal scenes to detect unseen and undefined anomalies. Since abnormal scenes are distinguished from normal scenes by appearance or motion, lots of previous approaches have used an explicit pre-trained model such as optical flow for motion information, which makes the network complex and dependent on the pre-training. We propose an implicit two-path AutoEncoder (ITAE) that exploits the structure of a SlowFast network and focuses on spatial and temporal information through appearance (slow) and motion (fast) encoders, respectively. The two encoders and a single decoder learn normal appearance and behavior by reconstructing normal videos of the training set. Furthermore, with features from the two encoders, we suggest density estimation through flow-based generative models to learn the tractable likelihoods of appearance and motion features. Finally, we show the effectiveness of appearance and motion encoders and their distribution modeling through experiments in three benchmarks which result outperforms the state-of-the-art methods.
Smoother Network Tuning and Interpolation for Continuous-level Image Processing
Oct 05, 2020
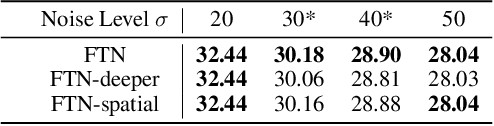
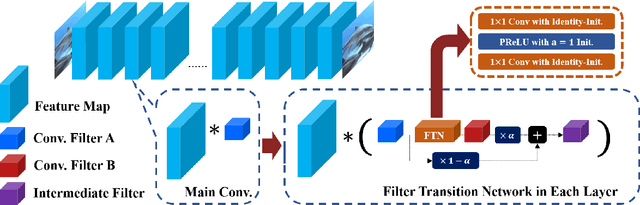
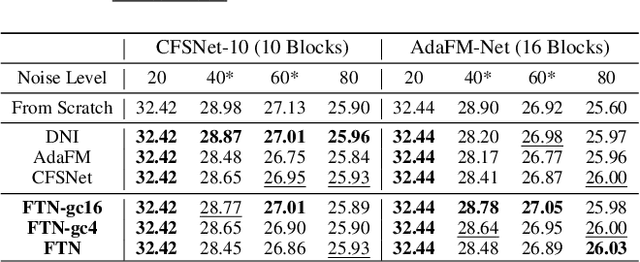
In Convolutional Neural Network (CNN) based image processing, most studies propose networks that are optimized to single-level (or single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train networks on two different levels and propose their own interpolation methods to enable arbitrary intermediate levels. However, many of them fail to generalize or have certain side effects in practical usage. In this paper, we define these frameworks as network tuning and interpolation and propose a novel module for continuous-level learning, called Filter Transition Network (FTN). This module is a structurally smoother module than existing ones. Therefore, the frameworks with FTN generalize well across various tasks and networks and cause fewer undesirable side effects. For stable learning of FTN, we additionally propose a method to initialize non-linear neural network layers with identity mappings. Extensive results for various image processing tasks indicate that the performance of FTN is comparable in multiple continuous levels, and is significantly smoother and lighter than that of other frameworks.
Enhanced Standard Compatible Image Compression Framework based on Auxiliary Codec Networks
Sep 30, 2020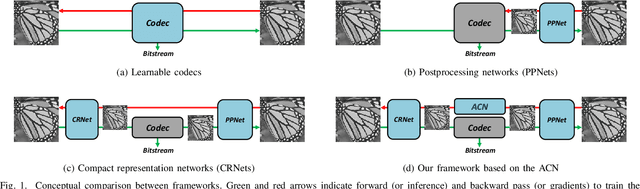
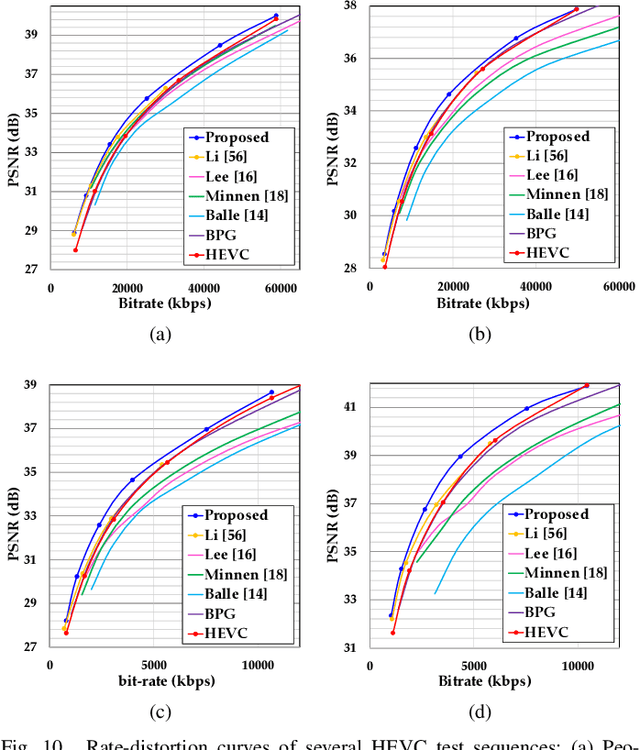
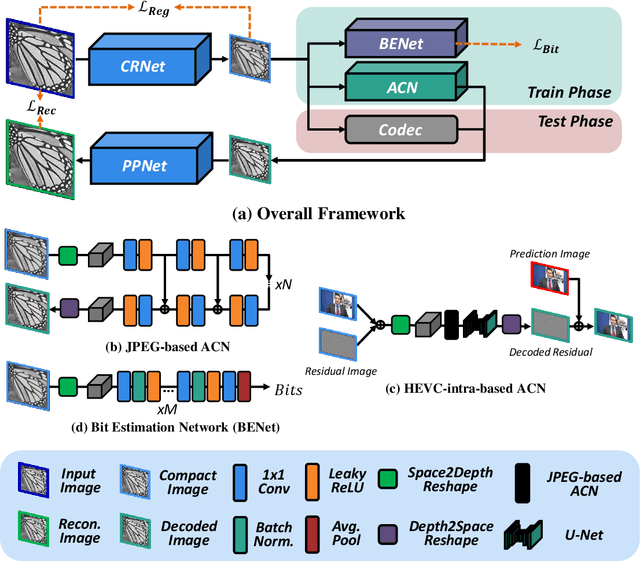
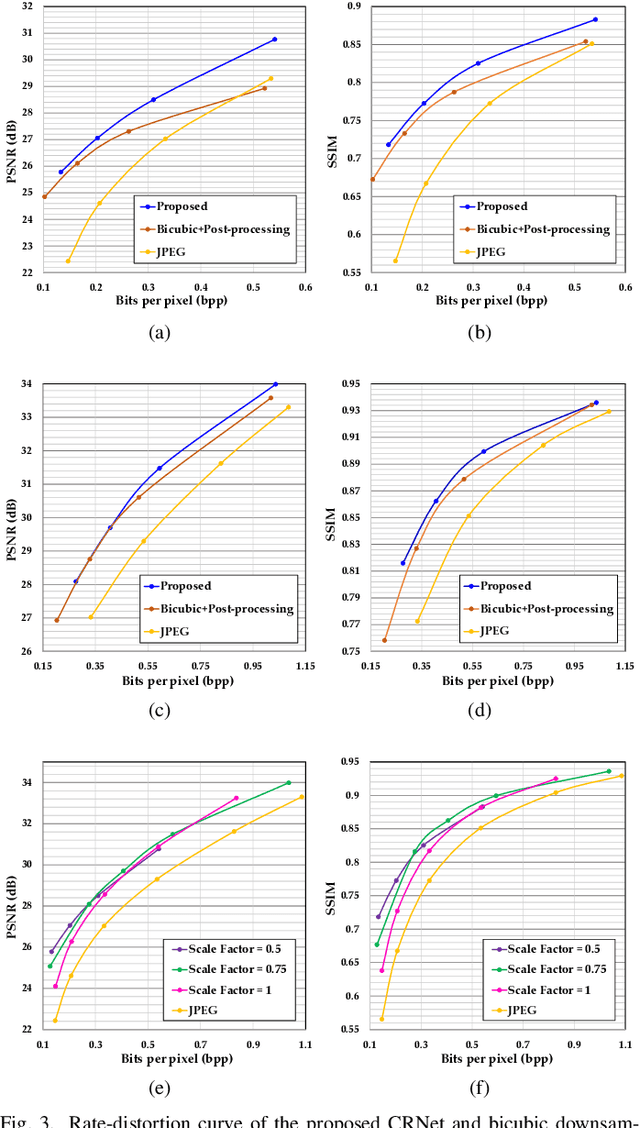
To enhance image compression performance, recent deep neural network-based research can be divided into three categories: a learnable codec, a postprocessing network, and a compact representation network. The learnable codec has been designed for an end-to-end learning beyond the conventional compression modules. The postprocessing network increases the quality of decoded images using an example-based learning. The compact representation network is learned to reduce the capacity of an input image to reduce the bitrate while keeping the quality of the decoded image. However, these approaches are not compatible with the existing codecs or not optimal to increase the coding efficiency. Specifically, it is difficult to achieve optimal learning in the previous studies using the compact representation network, due to the inaccurate consideration of the codecs. In this paper, we propose a novel standard compatible image compression framework based on Auxiliary Codec Networks (ACNs). ACNs are designed to imitate image degradation operations of the existing codec, which delivers more accurate gradients to the compact representation network. Therefore, the compact representation and the postprocessing networks can be learned effectively and optimally. We demonstrate that our proposed framework based on JPEG and High Efficiency Video Coding (HEVC) standard substantially outperforms existing image compression algorithms in a standard compatible manner.
Learning Temporally Invariant and Localizable Features via Data Augmentation for Video Recognition
Aug 13, 2020



Deep-Learning-based video recognition has shown promising improvements along with the development of large-scale datasets and spatiotemporal network architectures. In image recognition, learning spatially invariant features is a key factor in improving recognition performance and robustness. Data augmentation based on visual inductive priors, such as cropping, flipping, rotating, or photometric jittering, is a representative approach to achieve these features. Recent state-of-the-art recognition solutions have relied on modern data augmentation strategies that exploit a mixture of augmentation operations. In this study, we extend these strategies to the temporal dimension for videos to learn temporally invariant or temporally localizable features to cover temporal perturbations or complex actions in videos. Based on our novel temporal data augmentation algorithms, video recognition performances are improved using only a limited amount of training data compared to the spatial-only data augmentation algorithms, including the 1st Visual Inductive Priors (VIPriors) for data-efficient action recognition challenge. Furthermore, learned features are temporally localizable that cannot be achieved using spatial augmentation algorithms. Our source code is available at https://github.com/taeoh-kim/temporal_data_augmentation.
Extrapolative-Interpolative Cycle-Consistency Learning for Video Frame Extrapolation
May 27, 2020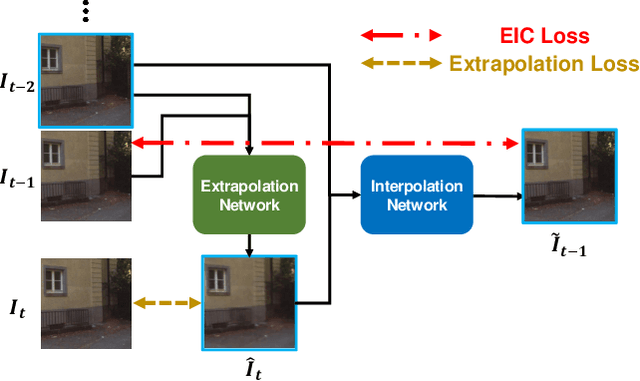

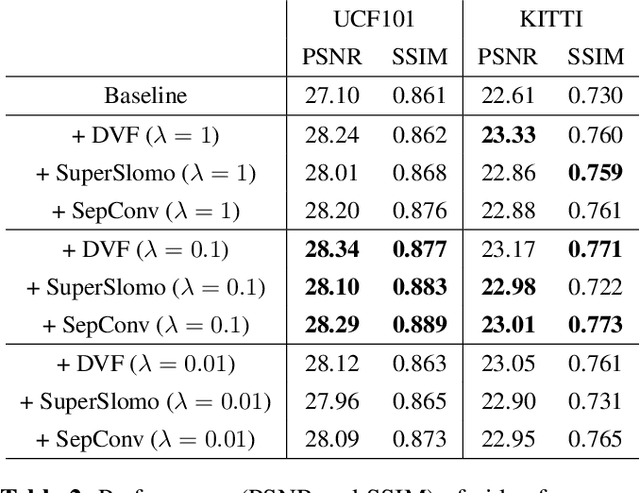

Video frame extrapolation is a task to predict future frames when the past frames are given. Unlike previous studies that usually have been focused on the design of modules or construction of networks, we propose a novel Extrapolative-Interpolative Cycle (EIC) loss using pre-trained frame interpolation module to improve extrapolation performance. Cycle-consistency loss has been used for stable prediction between two function spaces in many visual tasks. We formulate this cycle-consistency using two mapping functions; frame extrapolation and interpolation. Since it is easier to predict intermediate frames than to predict future frames in terms of the object occlusion and motion uncertainty, interpolation module can give guidance signal effectively for training the extrapolation function. EIC loss can be applied to any existing extrapolation algorithms and guarantee consistent prediction in the short future as well as long future frames. Experimental results show that simply adding EIC loss to the existing baseline increases extrapolation performance on both UCF101 and KITTI datasets.
Regularized Adaptation for Stable and Efficient Continuous-Level Learning on Image Processing Networks
Mar 12, 2020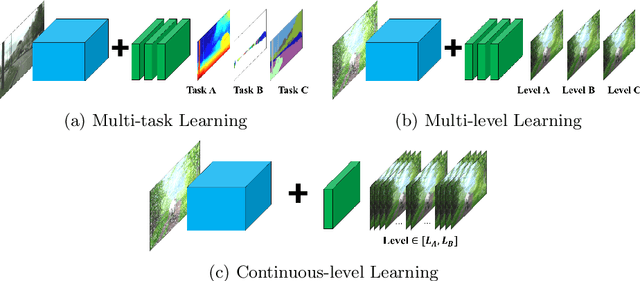

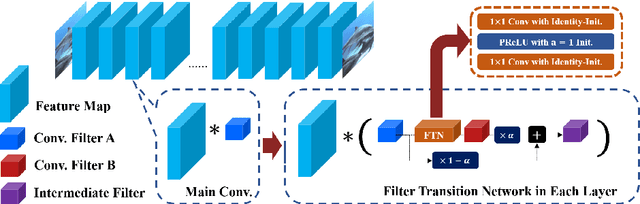

In Convolutional Neural Network (CNN) based image processing, most of the studies propose networks that are optimized for a single-level (or a single-objective); thus, they underperform on other levels and must be retrained for delivery of optimal performance. Using multiple models to cover multiple levels involves very high computational costs. To solve these problems, recent approaches train the networks on two different levels and propose their own interpolation methods to enable the arbitrary intermediate levels. However, many of them fail to adapt hard tasks or interpolate smoothly, or the others still require large memory and computational cost. In this paper, we propose a novel continuous-level learning framework using a Filter Transition Network (FTN) which is a non-linear module that easily adapt to new levels, and is regularized to prevent undesirable side-effects. Additionally, for stable learning of FTN, we newly propose a method to initialize non-linear CNNs with identity mappings. Furthermore, FTN is extremely lightweight module since it is a data-independent module, which means it is not affected by the spatial resolution of the inputs. Extensive results for various image processing tasks indicate that the performance of FTN is stable in terms of adaptation and interpolation, and comparable to that of the other heavy frameworks.
Relational Deep Feature Learning for Heterogeneous Face Recognition
Mar 02, 2020
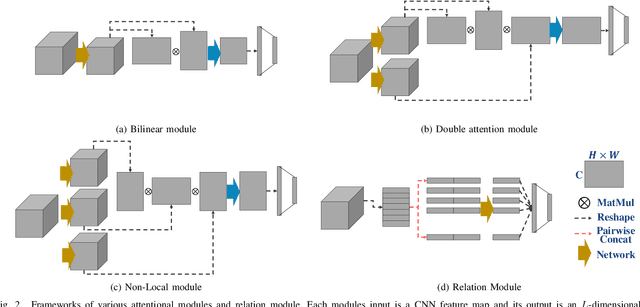
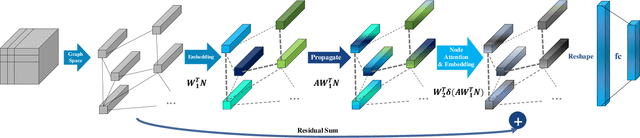
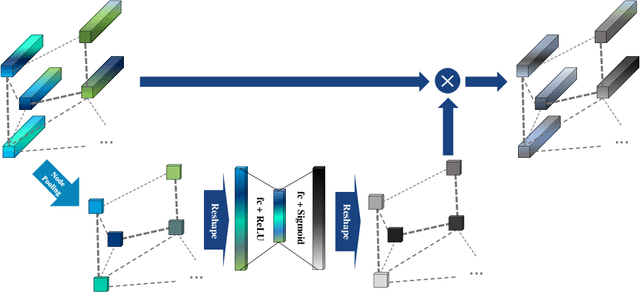
Heterogeneous Face Recognition (HFR) is a task that matches faces across two different domains such as VIS (visible light), NIR (near-infrared), or the sketch domain. In contrast to face recognition in visual spectrum, because of the domain discrepancy, this task requires to extract domain-invariant feature or common space projection learning. To bridge this domain gap, we propose a graph-structured module that focuses on facial relational information to reduce the fundamental differences in domain characteristics. Since relational information is domain independent, our Relational Graph Module (RGM) performs relation modeling from node vectors that represent facial components such as lips, nose, and chin. Propagation of the generated relational graph then reduces the domain difference by transitioning from spatially correlated CNN (convolutional neural network) features to inter-dependent relational features. In addition, we propose a Node Attention Unit (NAU) that performs node-wise recalibration to focus on the more informative nodes arising from the relation-based propagation. Furthermore, we suggest a novel conditional-margin loss function (C-Softmax) for efficient projection learning on the common latent space of the embedding vector. Our module can be plugged into any pre-trained face recognition network to help overcome the limitations of a small HFR database. The proposed method shows superior performance on three different HFR databases CAISA NIR-VIS 2.0, IIIT-D Sketch, and BUAA-VisNir in various pre-trained networks. Furthermore, we explore our C-Softmax loss boosts HFR performance and also apply our loss to the large-scale visual face database LFW(Labeled Faces in Wild) by learning inter-class margins adaptively.