 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhitespaces Don't Lie: Feature-Driven and Embedding-Based Approaches for Detecting Machine-Generated Code
Jan 27, 2026Large language models (LLMs) have made it remarkably easy to synthesize plausible source code from natural language prompts. While this accelerates software development and supports learning, it also raises new risks for academic integrity, authorship attribution, and responsible AI use. This paper investigates the problem of distinguishing human-written from machine-generated code by comparing two complementary approaches: feature-based detectors built from lightweight, interpretable stylometric and structural properties of code, and embedding-based detectors leveraging pretrained code encoders. Using a recent large-scale benchmark dataset of 600k human-written and AI-generated code samples, we find that feature-based models achieve strong performance (ROC-AUC 0.995, PR-AUC 0.995, F1 0.971), while embedding-based models with CodeBERT embeddings are also very competitive (ROC-AUC 0.994, PR-AUC 0.994, F1 0.965). Analysis shows that features tied to indentation and whitespace provide particularly discriminative cues, whereas embeddings capture deeper semantic patterns and yield slightly higher precision. These findings underscore the trade-offs between interpretability and generalization, offering practical guidance for deploying robust code-origin detection in academic and industrial contexts.
Handcrafted Feature Fusion for Reliable Detection of AI-Generated Images
Jan 27, 2026The rapid progress of generative models has enabled the creation of highly realistic synthetic images, raising concerns about authenticity and trust in digital media. Detecting such fake content reliably is an urgent challenge. While deep learning approaches dominate current literature, handcrafted features remain attractive for their interpretability, efficiency, and generalizability. In this paper, we conduct a systematic evaluation of handcrafted descriptors, including raw pixels, color histograms, Discrete Cosine Transform (DCT), Histogram of Oriented Gradients (HOG), Local Binary Patterns (LBP), Gray-Level Co-occurrence Matrix (GLCM), and wavelet features, on the CIFAKE dataset of real versus synthetic images. Using 50,000 training and 10,000 test samples, we benchmark seven classifiers ranging from Logistic Regression to advanced gradient-boosted ensembles (LightGBM, XGBoost, CatBoost). Results demonstrate that LightGBM consistently outperforms alternatives, achieving PR-AUC 0.9879, ROC-AUC 0.9878, F1 0.9447, and a Brier score of 0.0414 with mixed features, representing strong gains in calibration and discrimination over simpler descriptors. Across three configurations (baseline, advanced, mixed), performance improves monotonically, confirming that combining diverse handcrafted features yields substantial benefit. These findings highlight the continued relevance of carefully engineered features and ensemble learning for detecting synthetic images, particularly in contexts where interpretability and computational efficiency are critical.
Statistical Analysis on Bangla Newspaper Data to Extract Trending Topic and Visualize Its Change Over Time
Jan 27, 2017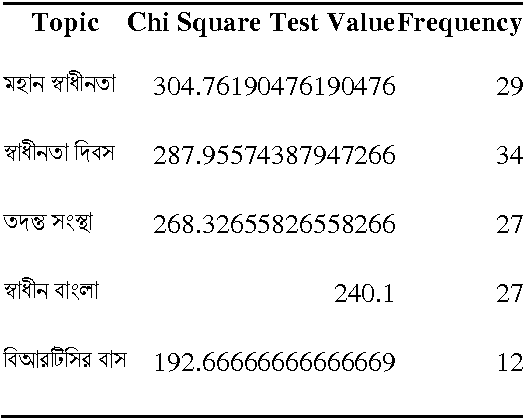
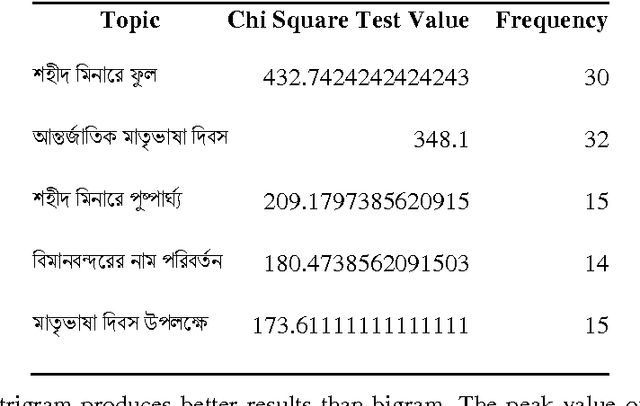

Trending topic of newspapers is an indicator to understand the situation of a country and also a way to evaluate the particular newspaper. This paper represents a model describing few techniques to select trending topics from Bangla Newspaper. Topics that are discussed more frequently than other in Bangla newspaper will be marked and how a very famous topic loses its importance with the change of time and another topic takes its place will be demonstrated. Data from two popular Bangla Newspaper with date and time were collected. Statistical analysis was performed after on these data after preprocessing. Popular and most used keywords were extracted from the stream of Bangla keyword with this analysis. This model can also cluster category wise news trend or a list of news trend in daily or weekly basis with enough data. A pattern can be found on their news trend too. Comparison among past news trend of Bangla newspapers will give a visualization of the situation of Bangladesh. This visualization will be helpful to predict future trending topics of Bangla Newspaper.