 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality of Gaussian-Mixture Reverse Kernels in Conditional Diffusion
Apr 15, 2026We prove that conditional diffusion models whose reverse kernels are finite Gaussian mixtures with ReLU-network logits can approximate suitably regular target distributions arbitrarily well in context-averaged conditional KL divergence, up to an irreducible terminal mismatch that typically vanishes with increasing diffusion horizon. A path-space decomposition reduces the output error to this mismatch plus per-step reverse-kernel errors; assuming each reverse kernel factors through a finite-dimensional feature map, each step becomes a static conditional density approximation problem, solved by composing Norets' Gaussian-mixture theory with quantitative ReLU bounds. Under exact terminal matching the resulting neural reverse-kernel class is dense in conditional KL.
CAM-Seg: A Continuous-valued Embedding Approach for Semantic Image Generation
Mar 19, 2025



Traditional transformer-based semantic segmentation relies on quantized embeddings. However, our analysis reveals that autoencoder accuracy on segmentation mask using quantized embeddings (e.g. VQ-VAE) is 8% lower than continuous-valued embeddings (e.g. KL-VAE). Motivated by this, we propose a continuous-valued embedding framework for semantic segmentation. By reformulating semantic mask generation as a continuous image-to-embedding diffusion process, our approach eliminates the need for discrete latent representations while preserving fine-grained spatial and semantic details. Our key contribution includes a diffusion-guided autoregressive transformer that learns a continuous semantic embedding space by modeling long-range dependencies in image features. Our framework contains a unified architecture combining a VAE encoder for continuous feature extraction, a diffusion-guided transformer for conditioned embedding generation, and a VAE decoder for semantic mask reconstruction. Our setting facilitates zero-shot domain adaptation capabilities enabled by the continuity of the embedding space. Experiments across diverse datasets (e.g., Cityscapes and domain-shifted variants) demonstrate state-of-the-art robustness to distribution shifts, including adverse weather (e.g., fog, snow) and viewpoint variations. Our model also exhibits strong noise resilience, achieving robust performance ($\approx$ 95% AP compared to baseline) under gaussian noise, moderate motion blur, and moderate brightness/contrast variations, while experiencing only a moderate impact ($\approx$ 90% AP compared to baseline) from 50% salt and pepper noise, saturation and hue shifts. Code available: https://github.com/mahmed10/CAMSS.git
Classical Music Clustering Based on Acoustic Features
Jun 27, 2017
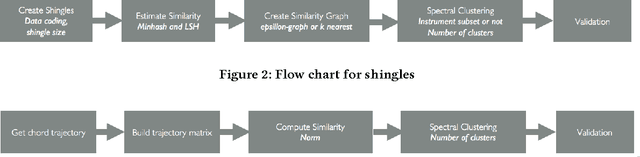
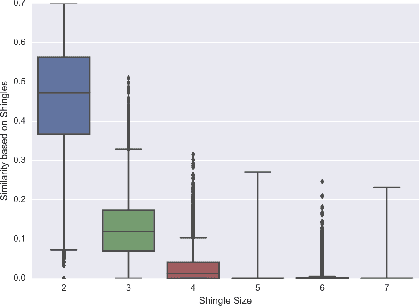
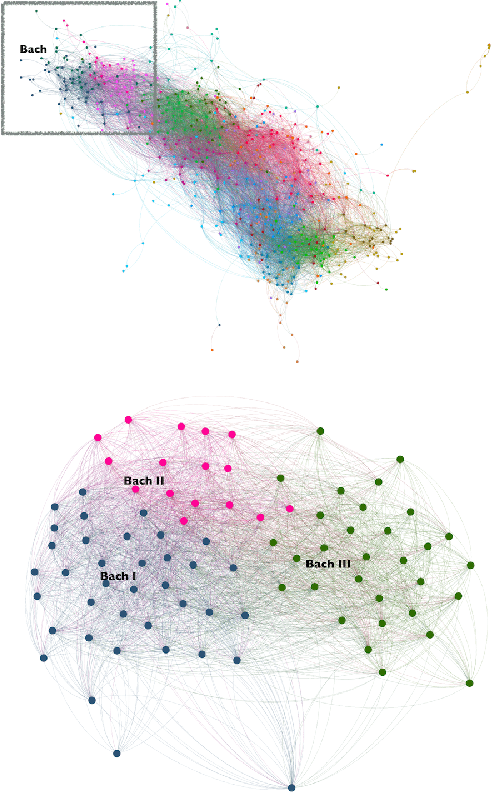
In this paper we cluster 330 classical music pieces collected from MusicNet database based on their musical note sequence. We use shingling and chord trajectory matrices to create signature for each music piece and performed spectral clustering to find the clusters. Based on different resolution, the output clusters distinctively indicate composition from different classical music era and different composing style of the musicians.