 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization with Missing Inputs
Jun 19, 2020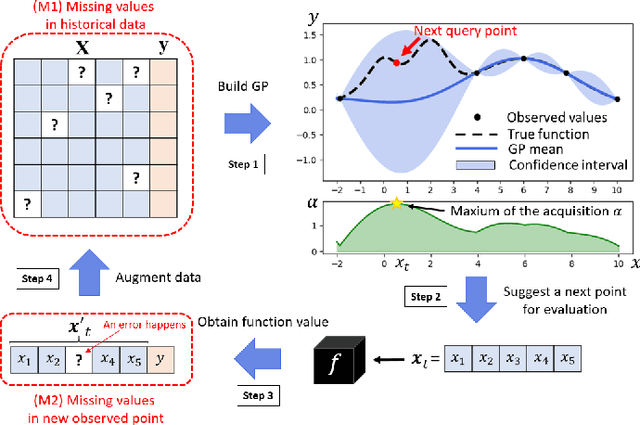
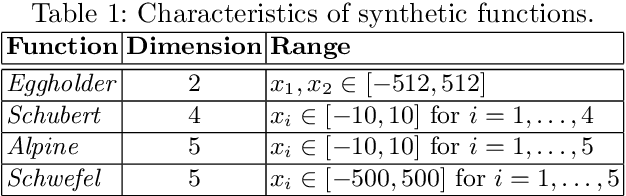
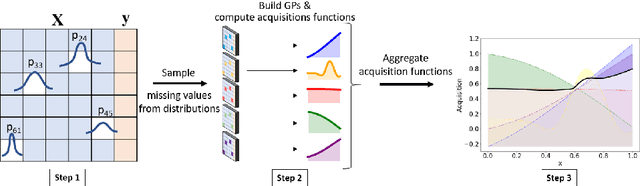
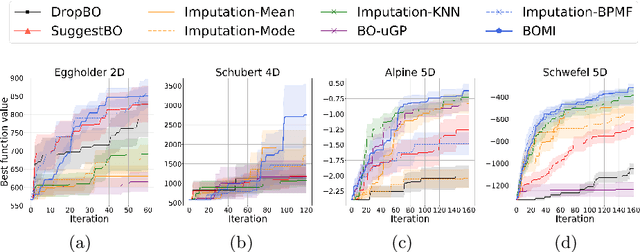
Bayesian optimization (BO) is an efficient method for optimizing expensive black-box functions. In real-world applications, BO often faces a major problem of missing values in inputs. The missing inputs can happen in two cases. First, the historical data for training BO often contain missing values. Second, when performing the function evaluation (e.g. computing alloy strength in a heat treatment process), errors may occur (e.g. a thermostat stops working) leading to an erroneous situation where the function is computed at a random unknown value instead of the suggested value. To deal with this problem, a common approach just simply skips data points where missing values happen. Clearly, this naive method cannot utilize data efficiently and often leads to poor performance. In this paper, we propose a novel BO method to handle missing inputs. We first find a probability distribution of each missing value so that we can impute the missing value by drawing a sample from its distribution. We then develop a new acquisition function based on the well-known Upper Confidence Bound (UCB) acquisition function, which considers the uncertainty of imputed values when suggesting the next point for function evaluation. We conduct comprehensive experiments on both synthetic and real-world applications to show the usefulness of our method.
DeepCoDA: personalized interpretability for compositional health data
Jun 16, 2020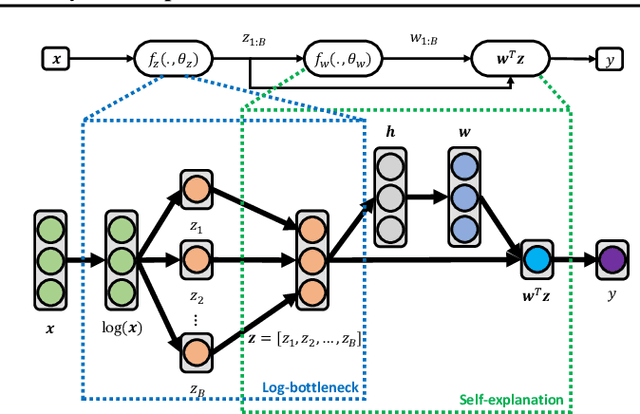
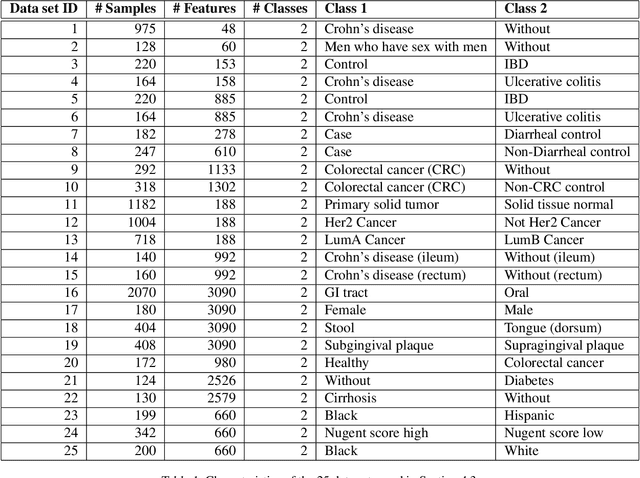
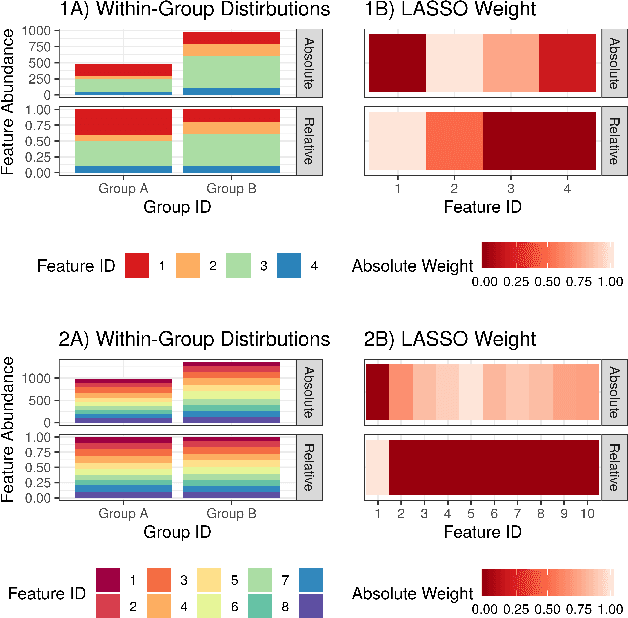
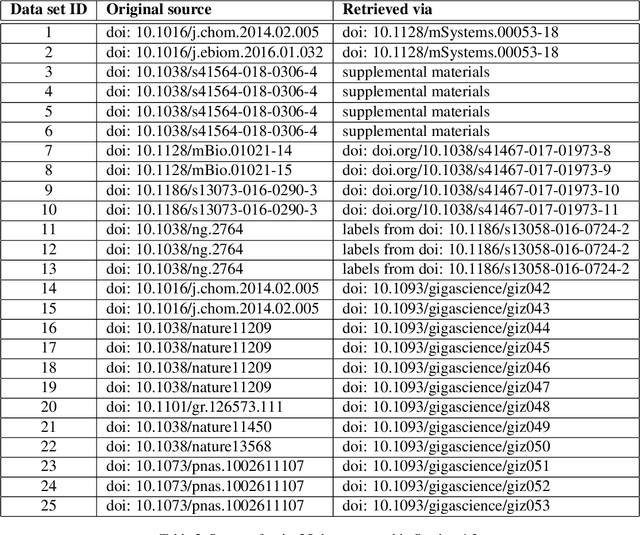
Interpretability allows the domain-expert to directly evaluate the model's relevance and reliability, a practice that offers assurance and builds trust. In the healthcare setting, interpretable models should implicate relevant biological mechanisms independent of technical factors like data pre-processing. We define personalized interpretability as a measure of sample-specific feature attribution, and view it as a minimum requirement for a precision health model to justify its conclusions. Some health data, especially those generated by high-throughput sequencing experiments, have nuances that compromise precision health models and their interpretation. These data are compositional, meaning that each feature is conditionally dependent on all other features. We propose the Deep Compositional Data Analysis (DeepCoDA) framework to extend precision health modelling to high-dimensional compositional data, and to provide personalized interpretability through patient-specific weights. Our architecture maintains state-of-the-art performance across 25 real-world data sets, all while producing interpretations that are both personalized and fully coherent for compositional data.
Scalable Backdoor Detection in Neural Networks
Jun 10, 2020
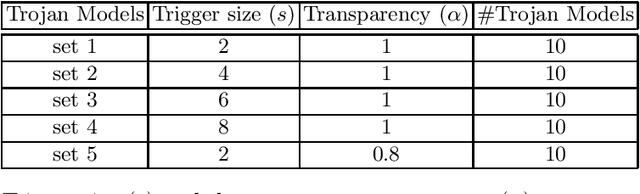
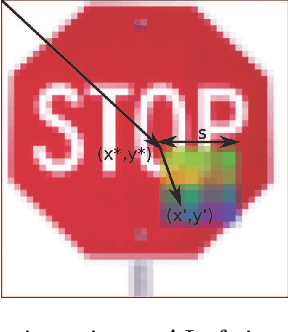

Recently, it has been shown that deep learning models are vulnerable to Trojan attacks, where an attacker can install a backdoor during training time to make the resultant model misidentify samples contaminated with a small trigger patch. Current backdoor detection methods fail to achieve good detection performance and are computationally expensive. In this paper, we propose a novel trigger reverse-engineering based approach whose computational complexity does not scale with the number of labels, and is based on a measure that is both interpretable and universal across different network and patch types. In experiments, we observe that our method achieves a perfect score in separating Trojaned models from pure models, which is an improvement over the current state-of-the art method.
Randomised Gaussian Process Upper Confidence Bound for Bayesian Optimisation
Jun 08, 2020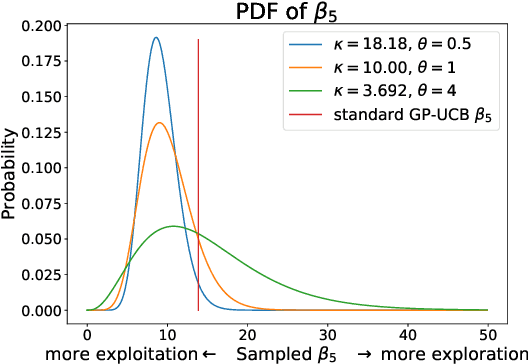
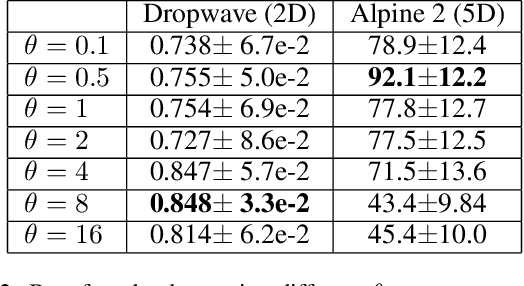
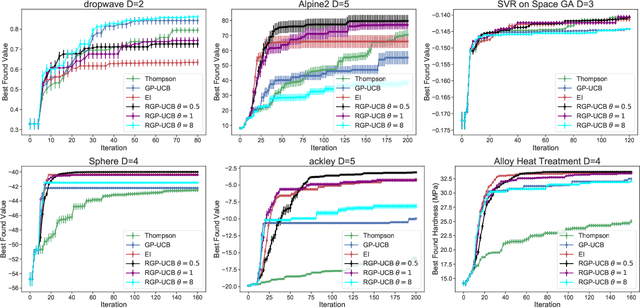
In order to improve the performance of Bayesian optimisation, we develop a modified Gaussian process upper confidence bound (GP-UCB) acquisition function. This is done by sampling the exploration-exploitation trade-off parameter from a distribution. We prove that this allows the expected trade-off parameter to be altered to better suit the problem without compromising a bound on the function's Bayesian regret. We also provide results showing that our method achieves better performance than GP-UCB in a range of real-world and synthetic problems.
HyperVAE: A Minimum Description Length Variational Hyper-Encoding Network
May 18, 2020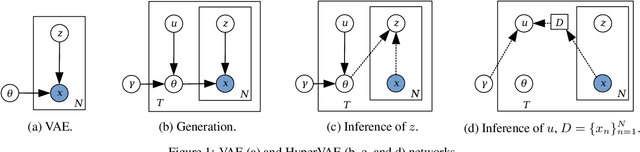
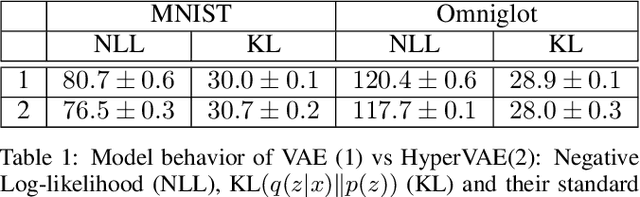

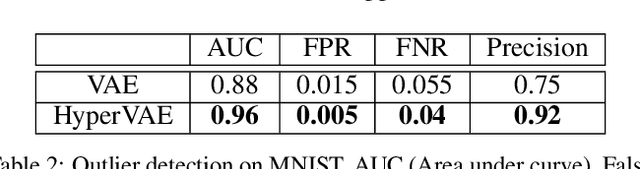
We propose a framework called HyperVAE for encoding distributions of distributions. When a target distribution is modeled by a VAE, its neural network parameters \theta is drawn from a distribution p(\theta) which is modeled by a hyper-level VAE. We propose a variational inference using Gaussian mixture models to implicitly encode the parameters \theta into a low dimensional Gaussian distribution. Given a target distribution, we predict the posterior distribution of the latent code, then use a matrix-network decoder to generate a posterior distribution q(\theta). HyperVAE can encode the parameters \theta in full in contrast to common hyper-networks practices, which generate only the scale and bias vectors as target-network parameters. Thus HyperVAE preserves much more information about the model for each task in the latent space. We discuss HyperVAE using the minimum description length (MDL) principle and show that it helps HyperVAE to generalize. We evaluate HyperVAE in density estimation tasks, outlier detection and discovery of novel design classes, demonstrating its efficacy.
Dynamic Language Binding in Relational Visual Reasoning
Apr 30, 2020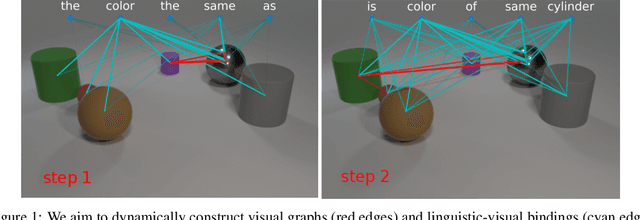
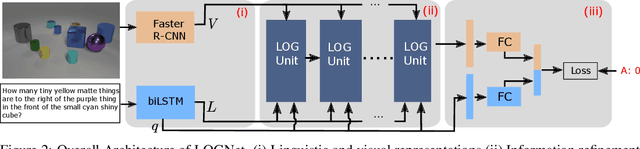
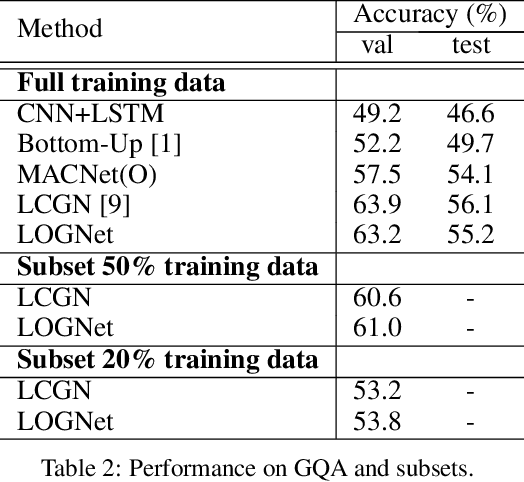
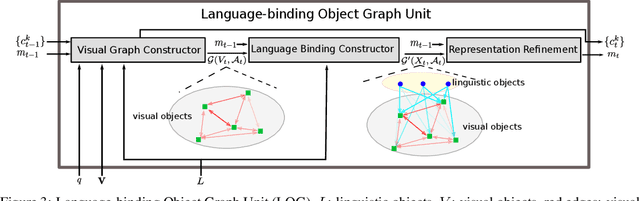
We present Language-binding Object Graph Network, the first neural reasoning method with dynamic relational structures across both visual and textual domains with applications in visual question answering. Relaxing the common assumption made by current models that the object predicates pre-exist and stay static, passive to the reasoning process, we propose that these dynamic predicates expand across the domain borders to include pair-wise visual-linguistic object binding. In our method, these contextualized object links are actively found within each recurrent reasoning step without relying on external predicative priors. These dynamic structures reflect the conditional dual-domain object dependency given the evolving context of the reasoning through co-attention. Such discovered dynamic graphs facilitate multi-step knowledge combination and refinements that iteratively deduce the compact representation of the final answer. The effectiveness of this model is demonstrated on image question answering demonstrating favorable performance on major VQA datasets. Our method outperforms other methods in sophisticated question-answering tasks wherein multiple object relations are involved. The graph structure effectively assists the progress of training, and therefore the network learns efficiently compared to other reasoning models.
Incorporating Expert Prior in Bayesian Optimisation via Space Warping
Mar 27, 2020
Bayesian optimisation is a well-known sample-efficient method for the optimisation of expensive black-box functions. However when dealing with big search spaces the algorithm goes through several low function value regions before reaching the optimum of the function. Since the function evaluations are expensive in terms of both money and time, it may be desirable to alleviate this problem. One approach to subside this cold start phase is to use prior knowledge that can accelerate the optimisation. In its standard form, Bayesian optimisation assumes the likelihood of any point in the search space being the optimum is equal. Therefore any prior knowledge that can provide information about the optimum of the function would elevate the optimisation performance. In this paper, we represent the prior knowledge about the function optimum through a prior distribution. The prior distribution is then used to warp the search space in such a way that space gets expanded around the high probability region of function optimum and shrinks around low probability region of optimum. We incorporate this prior directly in function model (Gaussian process), by redefining the kernel matrix, which allows this method to work with any acquisition function, i.e. acquisition agnostic approach. We show the superiority of our method over standard Bayesian optimisation method through optimisation of several benchmark functions and hyperparameter tuning of two algorithms: Support Vector Machine (SVM) and Random forest.
* 21 Pages, 8 figures. To be published in Elsevier
Hierarchical Conditional Relation Networks for Video Question Answering
Mar 17, 2020
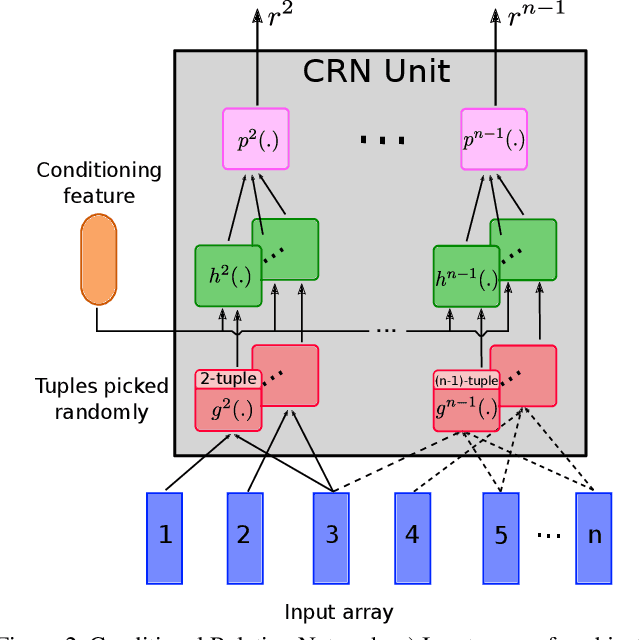
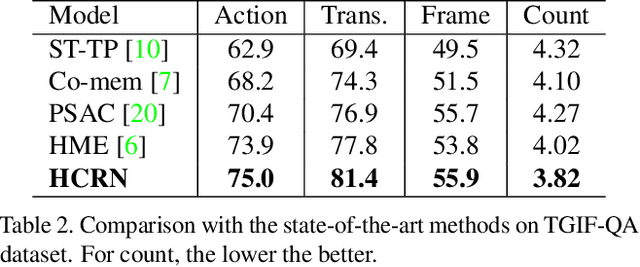
Video question answering (VideoQA) is challenging as it requires modeling capacity to distill dynamic visual artifacts and distant relations and to associate them with linguistic concepts. We introduce a general-purpose reusable neural unit called Conditional Relation Network (CRN) that serves as a building block to construct more sophisticated structures for representation and reasoning over video. CRN takes as input an array of tensorial objects and a conditioning feature, and computes an array of encoded output objects. Model building becomes a simple exercise of replication, rearrangement and stacking of these reusable units for diverse modalities and contextual information. This design thus supports high-order relational and multi-step reasoning. The resulting architecture for VideoQA is a CRN hierarchy whose branches represent sub-videos or clips, all sharing the same question as the contextual condition. Our evaluations on well-known datasets achieved new SoTA results, demonstrating the impact of building a general-purpose reasoning unit on complex domains such as VideoQA.
* Check out our code on GitHub at https://github.com/thaolmk54/hcrn-videoqa
Incorporating Expert Prior Knowledge into Experimental Design via Posterior Sampling
Feb 26, 2020
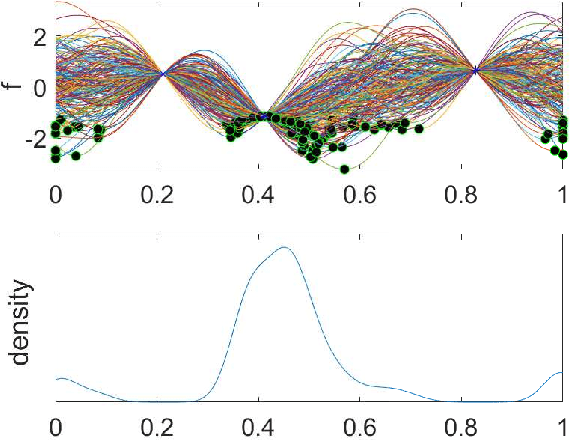
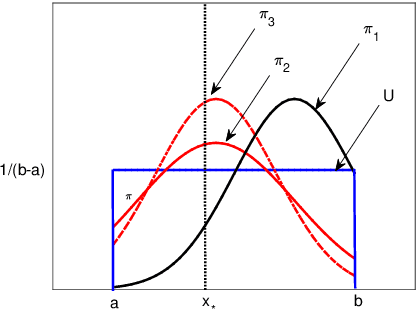
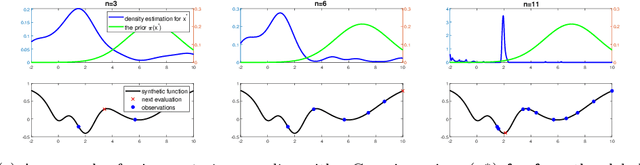
Scientific experiments are usually expensive due to complex experimental preparation and processing. Experimental design is therefore involved with the task of finding the optimal experimental input that results in the desirable output by using as few experiments as possible. Experimenters can often acquire the knowledge about the location of the global optimum. However, they do not know how to exploit this knowledge to accelerate experimental design. In this paper, we adopt the technique of Bayesian optimization for experimental design since Bayesian optimization has established itself as an efficient tool for optimizing expensive black-box functions. Again, it is unknown how to incorporate the expert prior knowledge about the global optimum into Bayesian optimization process. To address it, we represent the expert knowledge about the global optimum via placing a prior distribution on it and we then derive its posterior distribution. An efficient Bayesian optimization approach has been proposed via posterior sampling on the posterior distribution of the global optimum. We theoretically analyze the convergence of the proposed algorithm and discuss the robustness of incorporating expert prior. We evaluate the efficiency of our algorithm by optimizing synthetic functions and tuning hyperparameters of classifiers along with a real-world experiment on the synthesis of short polymer fiber. The results clearly demonstrate the advantages of our proposed method.
Self-Attentive Associative Memory
Feb 11, 2020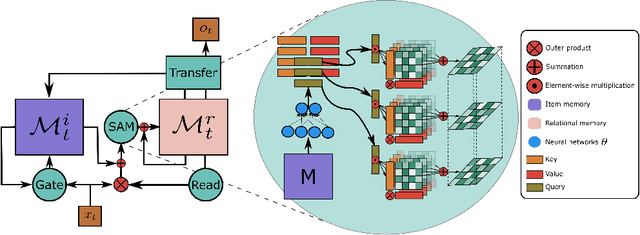
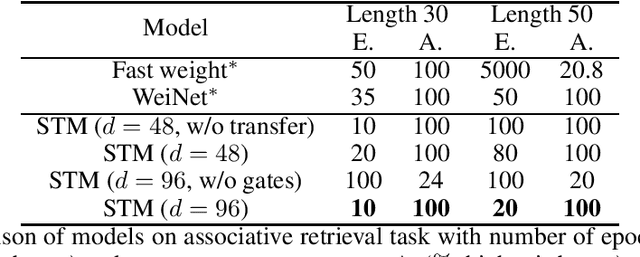

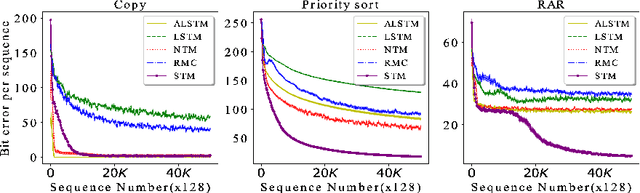
Heretofore, neural networks with external memory are restricted to single memory with lossy representations of memory interactions. A rich representation of relationships between memory pieces urges a high-order and segregated relational memory. In this paper, we propose to separate the storage of individual experiences (item memory) and their occurring relationships (relational memory). The idea is implemented through a novel Self-attentive Associative Memory (SAM) operator. Found upon outer product, SAM forms a set of associative memories that represent the hypothetical high-order relationships between arbitrary pairs of memory elements, through which a relational memory is constructed from an item memory. The two memories are wired into a single sequential model capable of both memorization and relational reasoning. We achieve competitive results with our proposed two-memory model in a diversity of machine learning tasks, from challenging synthetic problems to practical testbeds such as geometry, graph, reinforcement learning, and question answering.