 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Dimensional Level Set Estimation with Bayesian Neural Network
Dec 17, 2020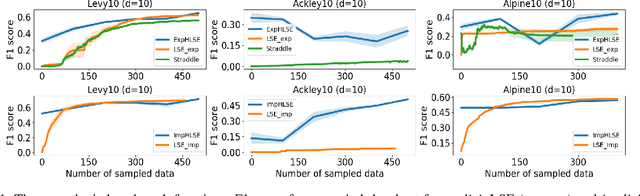
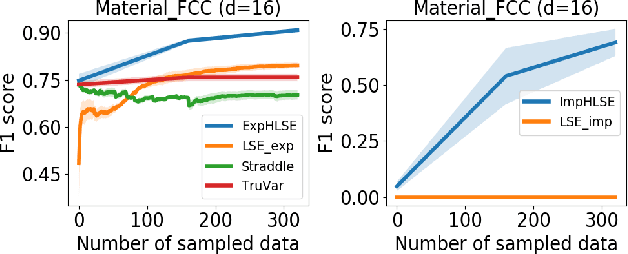
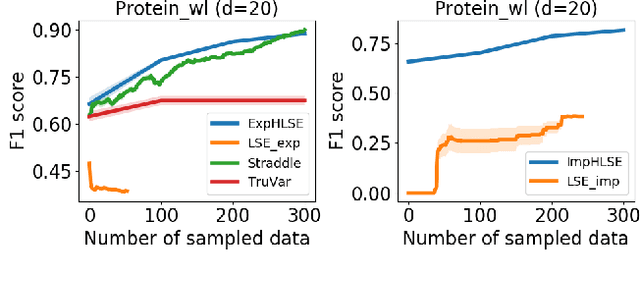
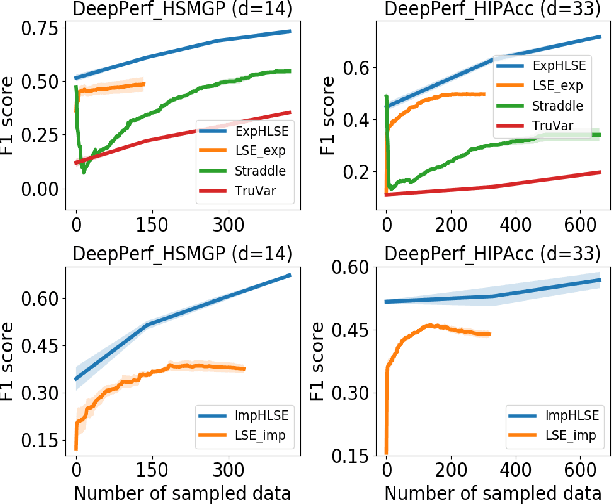
Level Set Estimation (LSE) is an important problem with applications in various fields such as material design, biotechnology, machine operational testing, etc. Existing techniques suffer from the scalability issue, that is, these methods do not work well with high dimensional inputs. This paper proposes novel methods to solve the high dimensional LSE problems using Bayesian Neural Networks. In particular, we consider two types of LSE problems: (1) \textit{explicit} LSE problem where the threshold level is a fixed user-specified value, and, (2) \textit{implicit} LSE problem where the threshold level is defined as a percentage of the (unknown) maximum of the objective function. For each problem, we derive the corresponding theoretic information based acquisition function to sample the data points so as to maximally increase the level set accuracy. Furthermore, we also analyse the theoretical time complexity of our proposed acquisition functions, and suggest a practical methodology to efficiently tune the network hyper-parameters to achieve high model accuracy. Numerical experiments on both synthetic and real-world datasets show that our proposed method can achieve better results compared to existing state-of-the-art approaches.
Semi-Supervised Learning with Variational Bayesian Inference and Maximum Uncertainty Regularization
Dec 03, 2020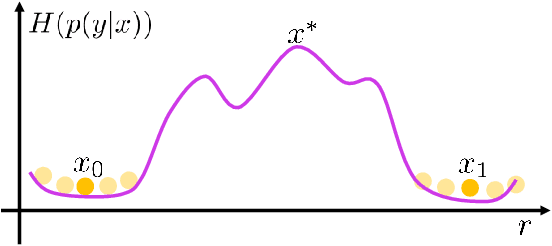
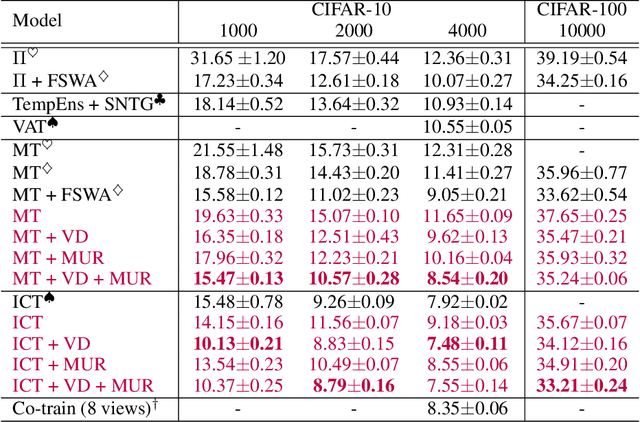
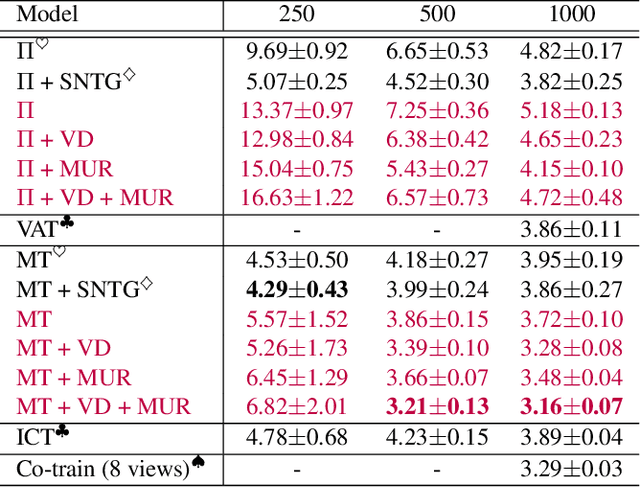
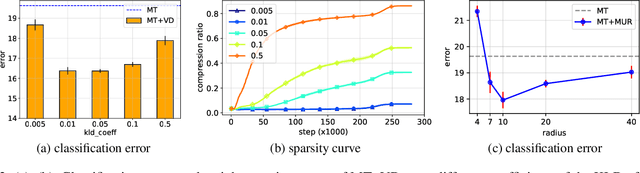
We propose two generic methods for improving semi-supervised learning (SSL). The first integrates weight perturbation (WP) into existing "consistency regularization" (CR) based methods. We implement WP by leveraging variational Bayesian inference (VBI). The second method proposes a novel consistency loss called "maximum uncertainty regularization" (MUR). While most consistency losses act on perturbations in the vicinity of each data point, MUR actively searches for "virtual" points situated beyond this region that cause the most uncertain class predictions. This allows MUR to impose smoothness on a wider area in the input-output manifold. Our experiments show clear improvements in classification errors of various CR based methods when they are combined with VBI or MUR or both.
Logically Consistent Loss for Visual Question Answering
Nov 19, 2020
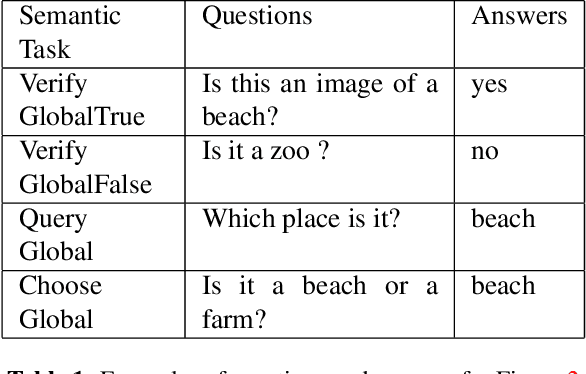
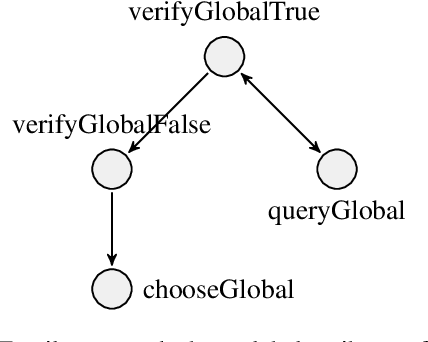
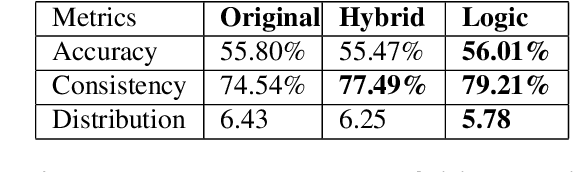
Given an image, a back-ground knowledge, and a set of questions about an object, human learners answer the questions very consistently regardless of question forms and semantic tasks. The current advancement in neural-network based Visual Question Answering (VQA), despite their impressive performance, cannot ensure such consistency due to identically distribution (i.i.d.) assumption. We propose a new model-agnostic logic constraint to tackle this issue by formulating a logically consistent loss in the multi-task learning framework as well as a data organisation called family-batch and hybrid-batch. To demonstrate usefulness of this proposal, we train and evaluate MAC-net based VQA machines with and without the proposed logically consistent loss and the proposed data organization. The experiments confirm that the proposed loss formulae and introduction of hybrid-batch leads to more consistency as well as better performance. Though the proposed approach is tested with MAC-net, it can be utilised in any other QA methods whenever the logical consistency between answers exist.
Hierarchical Conditional Relation Networks for Multimodal Video Question Answering
Oct 18, 2020

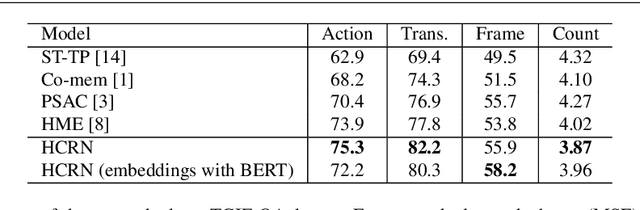
Video QA challenges modelers in multiple fronts. Modeling video necessitates building not only spatio-temporal models for the dynamic visual channel but also multimodal structures for associated information channels such as subtitles or audio. Video QA adds at least two more layers of complexity - selecting relevant content for each channel in the context of the linguistic query, and composing spatio-temporal concepts and relations in response to the query. To address these requirements, we start with two insights: (a) content selection and relation construction can be jointly encapsulated into a conditional computational structure, and (b) video-length structures can be composed hierarchically. For (a) this paper introduces a general-reusable neural unit dubbed Conditional Relation Network (CRN) taking as input a set of tensorial objects and translating into a new set of objects that encode relations of the inputs. The generic design of CRN helps ease the common complex model building process of Video QA by simple block stacking with flexibility in accommodating input modalities and conditioning features across both different domains. As a result, we realize insight (b) by introducing Hierarchical Conditional Relation Networks (HCRN) for Video QA. The HCRN primarily aims at exploiting intrinsic properties of the visual content of a video and its accompanying channels in terms of compositionality, hierarchy, and near and far-term relation. HCRN is then applied for Video QA in two forms, short-form where answers are reasoned solely from the visual content, and long-form where associated information, such as subtitles, presented. Our rigorous evaluations show consistent improvements over SOTAs on well-studied benchmarks including large-scale real-world datasets such as TGIF-QA and TVQA, demonstrating the strong capabilities of our CRN unit and the HCRN for complex domains such as Video QA.
Neurocoder: Learning General-Purpose Computation Using Stored Neural Programs
Sep 24, 2020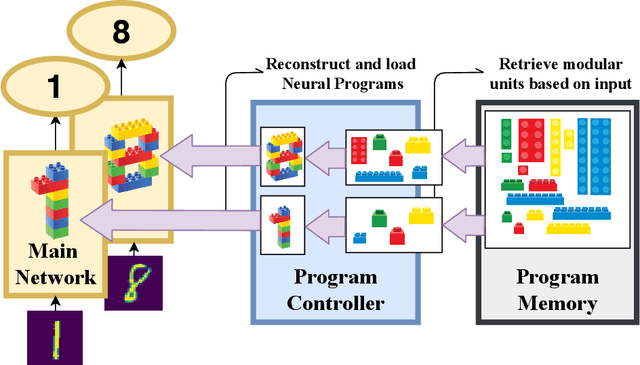
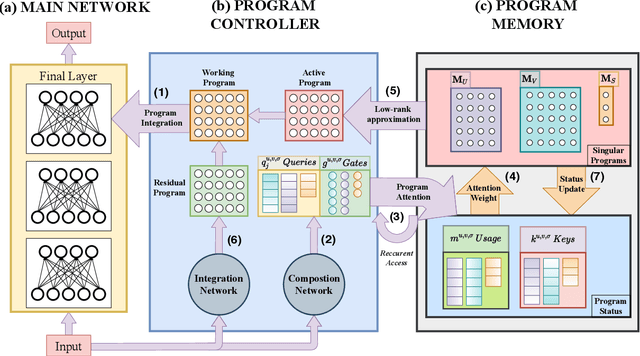
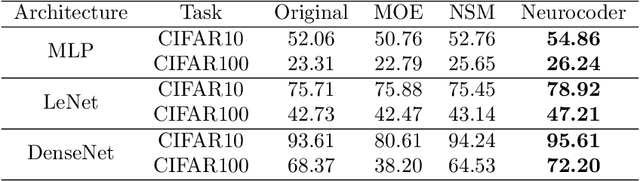
Artificial Neural Networks are uniquely adroit at machine learning by processing data through a network of artificial neurons. The inter-neuronal connection weights represent the learnt Neural Program that instructs the network on how to compute the data. However, without an external memory to store Neural Programs, they are restricted to only one, overwriting learnt programs when trained on new data. This is functionally equivalent to a special-purpose computer. Here we design Neurocoder, an entirely new class of general-purpose conditional computational machines in which the neural network "codes" itself in a data-responsive way by composing relevant programs from a set of shareable, modular programs. This can be considered analogous to building Lego structures from simple Lego bricks. Notably, our bricks change their shape through learning. External memory is used to create, store and retrieve modular programs. Like today's stored-program computers, Neurocoder can now access diverse programs to process different data. Unlike manually crafted computer programs, Neurocoder creates programs through training. Integrating Neurocoder into current neural architectures, we demonstrate new capacity to learn modular programs, handle severe pattern shifts and remember old programs as new ones are learnt, and show substantial performance improvement in solving object recognition, playing video games and continual learning tasks. Such integration with Neurocoder increases the computation capability of any current neural network and endows it with entirely new capacity to reuse simple programs to build complex ones. For the first time a Neural Program is treated as a datum in memory, paving the ways for modular, recursive and procedural neural programming.
Theory of Mind with Guilt Aversion Facilitates Cooperative Reinforcement Learning
Sep 16, 2020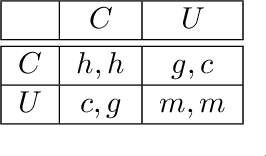
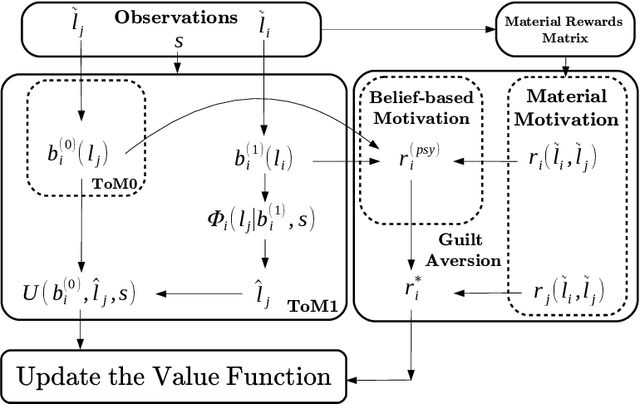
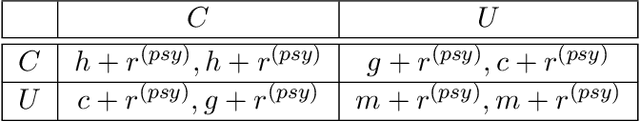
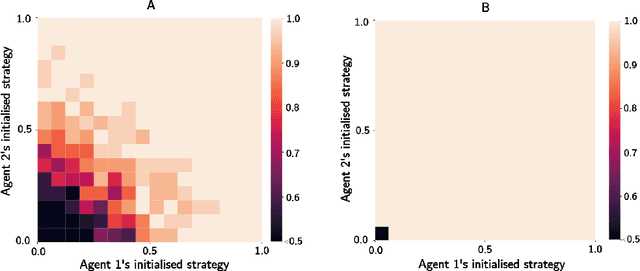
Guilt aversion induces experience of a utility loss in people if they believe they have disappointed others, and this promotes cooperative behaviour in human. In psychological game theory, guilt aversion necessitates modelling of agents that have theory about what other agents think, also known as Theory of Mind (ToM). We aim to build a new kind of affective reinforcement learning agents, called Theory of Mind Agents with Guilt Aversion (ToMAGA), which are equipped with an ability to think about the wellbeing of others instead of just self-interest. To validate the agent design, we use a general-sum game known as Stag Hunt as a test bed. As standard reinforcement learning agents could learn suboptimal policies in social dilemmas like Stag Hunt, we propose to use belief-based guilt aversion as a reward shaping mechanism. We show that our belief-based guilt averse agents can efficiently learn cooperative behaviours in Stag Hunt Games.
Sub-linear Regret Bounds for Bayesian Optimisation in Unknown Search Spaces
Sep 09, 2020
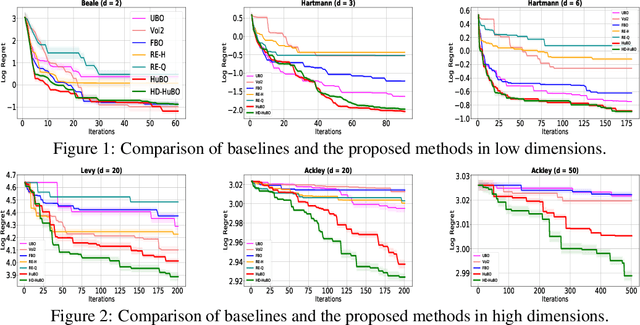
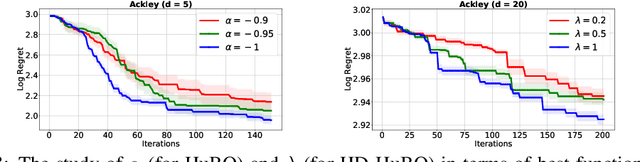
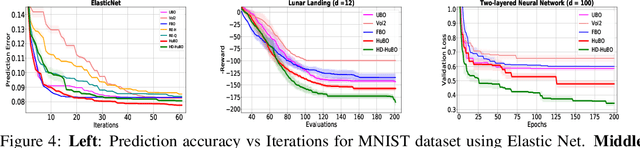
Bayesian optimisation is a popular method for efficient optimisation of expensive black-box functions. Traditionally, BO assumes that the search space is known. However, in many problems, this assumption does not hold. To this end, we propose a novel BO algorithm which expands (and shifts) the search space over iterations based on controlling the expansion rate thought a hyperharmonic series. Further, we propose another variant of our algorithm that scales to high dimensions. We show theoretically that for both our algorithms, the cumulative regret grows at sub-linear rates. Our experiments with synthetic and real-world optimisation tasks demonstrate the superiority of our algorithms over the current state-of-the-art methods for Bayesian optimisation in unknown search space.
Sequential Subspace Search for Functional Bayesian Optimization Incorporating Experimenter Intuition
Sep 08, 2020
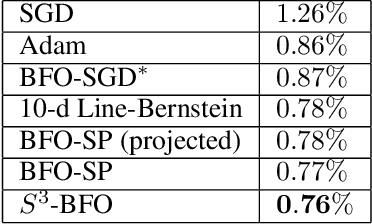

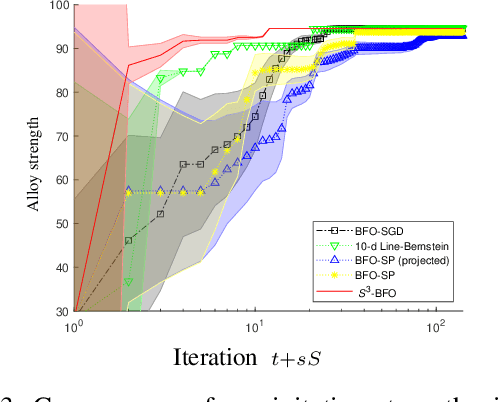
We propose an algorithm for Bayesian functional optimisation - that is, finding the function to optimise a process - guided by experimenter beliefs and intuitions regarding the expected characteristics (length-scale, smoothness, cyclicity etc.) of the optimal solution encoded into the covariance function of a Gaussian Process. Our algorithm generates a sequence of finite-dimensional random subspaces of functional space spanned by a set of draws from the experimenter's Gaussian Process. Standard Bayesian optimisation is applied on each subspace, and the best solution found used as a starting point (origin) for the next subspace. Using the concept of effective dimensionality, we analyse the convergence of our algorithm and provide a regret bound to show that our algorithm converges in sub-linear time provided a finite effective dimension exists. We test our algorithm in simulated and real-world experiments, namely blind function matching, finding the optimal precipitation-strengthening function for an aluminium alloy, and learning rate schedule optimisation for deep networks.
Learning to Abstract and Predict Human Actions
Aug 20, 2020
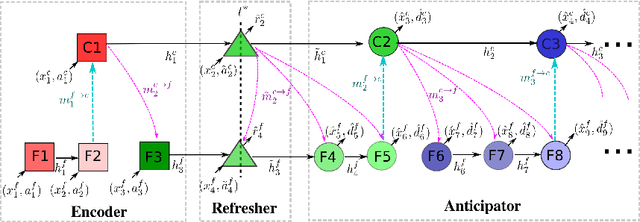
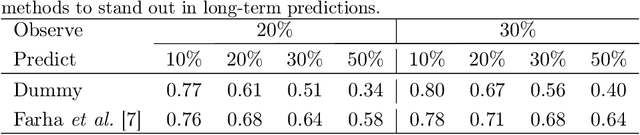
Human activities are naturally structured as hierarchies unrolled over time. For action prediction, temporal relations in event sequences are widely exploited by current methods while their semantic coherence across different levels of abstraction has not been well explored. In this work we model the hierarchical structure of human activities in videos and demonstrate the power of such structure in action prediction. We propose Hierarchical Encoder-Refresher-Anticipator, a multi-level neural machine that can learn the structure of human activities by observing a partial hierarchy of events and roll-out such structure into a future prediction in multiple levels of abstraction. We also introduce a new coarse-to-fine action annotation on the Breakfast Actions videos to create a comprehensive, consistent, and cleanly structured video hierarchical activity dataset. Through our experiments, we examine and rethink the settings and metrics of activity prediction tasks toward unbiased evaluation of prediction systems, and demonstrate the role of hierarchical modeling toward reliable and detailed long-term action forecasting.
Distributional Reinforcement Learning with Maximum Mean Discrepancy
Jul 24, 2020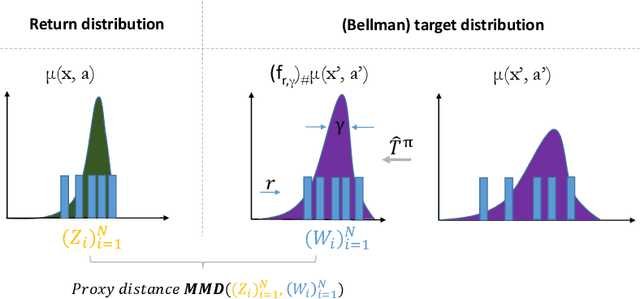
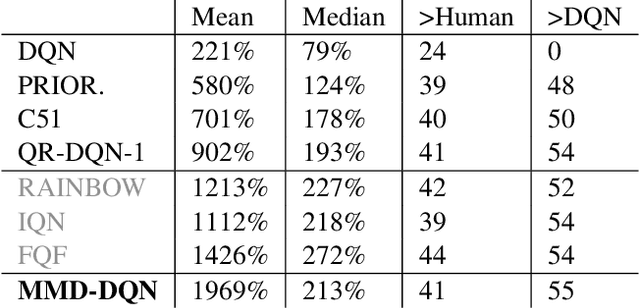
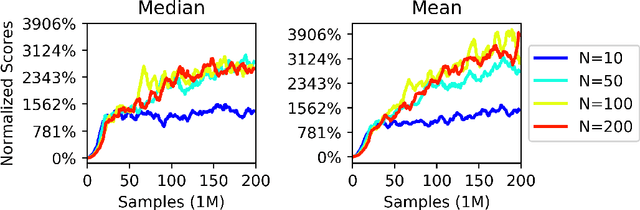

Distributional reinforcement learning (RL) has achieved state-of-the-art performance in Atari games by recasting the traditional RL into a distribution estimation problem, explicitly estimating the probability distribution instead of the expectation of a total return. The bottleneck in distributional RL lies in the estimation of this distribution where one must resort to an approximate representation of the return distributions which are infinite-dimensional. Most existing methods focus on learning a set of predefined statistic functionals of the return distributions requiring involved projections to maintain the order statistics. We take a different perspective using deterministic sampling wherein we approximate the return distributions with a set of deterministic particles that are not attached to any predefined statistic functional, allowing us to freely approximate the return distributions. The learning is then interpreted as evolution of these particles so that a distance between the return distribution and its target distribution is minimized. This learning aim is realized via maximum mean discrepancy (MMD) distance which in turn leads to a simpler loss amenable to backpropagation. Experiments on the suite of Atari 2600 games show that our algorithm outperforms the standard distributional RL baselines and sets a new record in the Atari games for non-distributed agents.