 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Image Set Hashing
Oct 01, 2016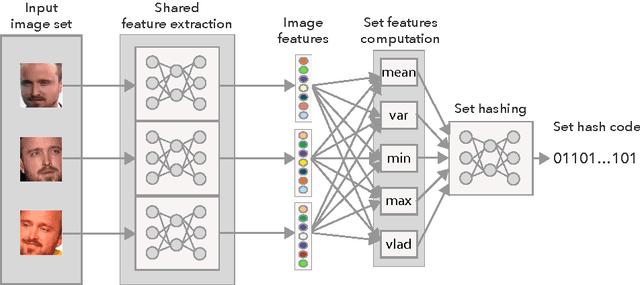
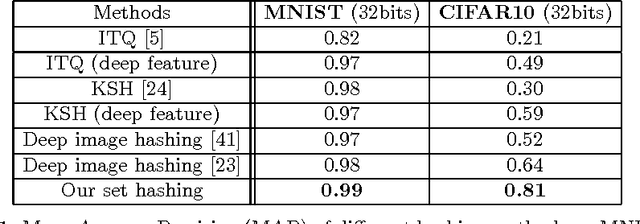

In applications involving matching of image sets, the information from multiple images must be effectively exploited to represent each set. State-of-the-art methods use probabilistic distribution or subspace to model a set and use specific distance measure to compare two sets. These methods are slow to compute and not compact to use in a large scale scenario. Learning-based hashing is often used in large scale image retrieval as they provide a compact representation of each sample and the Hamming distance can be used to efficiently compare two samples. However, most hashing methods encode each image separately and discard knowledge that multiple images in the same set represent the same object or person. We investigate the set hashing problem by combining both set representation and hashing in a single deep neural network. An image set is first passed to a CNN module to extract image features, then these features are aggregated using two types of set feature to capture both set specific and database-wide distribution information. The computed set feature is then fed into a multilayer perceptron to learn a compact binary embedding. Triplet loss is used to train the network by forming set similarity relations using class labels. We extensively evaluate our approach on datasets used for image matching and show highly competitive performance compared to state-of-the-art methods.
A Multi-Camera Image Processing and Visualization System for Train Safety Assessment
Jul 28, 2015

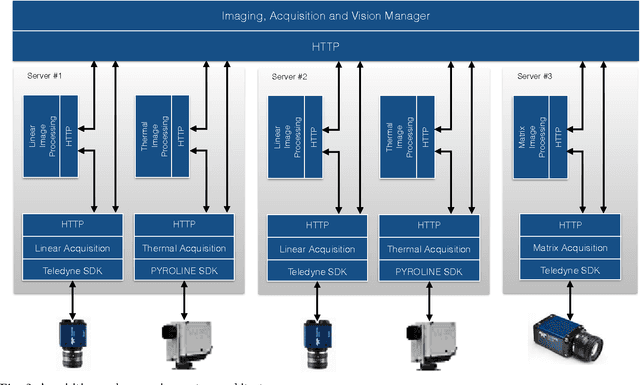
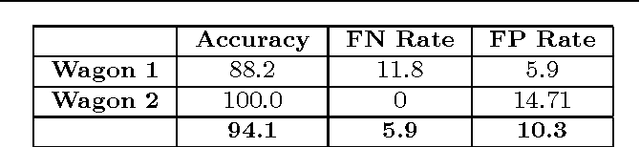
In this paper we present a machine vision system to efficiently monitor, analyze and present visual data acquired with a railway overhead gantry equipped with multiple cameras. This solution aims to improve the safety of daily life railway transportation in a two- fold manner: (1) by providing automatic algorithms that can process large imagery of trains (2) by helping train operators to keep attention on any possible malfunction. The system is designed with the latest cutting edge, high-rate visible and thermal cameras that ob- serve a train passing under an railway overhead gantry. The machine vision system is composed of three principal modules: (1) an automatic wagon identification system, recognizing the wagon ID according to the UIC classification of railway coaches; (2) a temperature monitoring system; (3) a system for the detection, localization and visualization of the pantograph of the train. These three machine vision modules process batch trains sequences and their resulting analysis are presented to an operator using a multitouch user interface. We detail all technical aspects of our multi-camera portal: the hardware requirements, the software developed to deal with the high-frame rate cameras and ensure reliable acquisition, the algorithms proposed to solve each computer vision task, and the multitouch interaction and visualization interface. We evaluate each component of our system on a dataset recorded in an ad-hoc railway test-bed, showing the potential of our proposed portal for train safety assessment.
Nested Graph Words for Object Recognition
Apr 23, 2014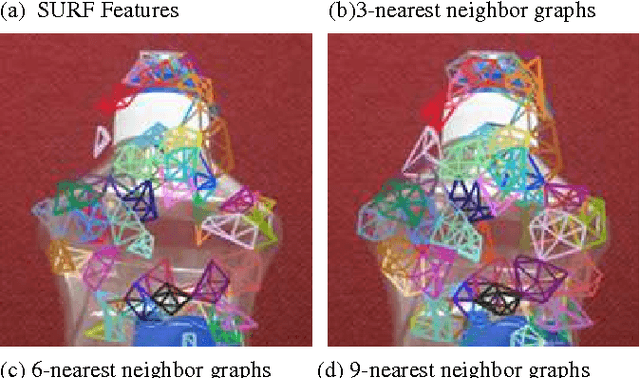


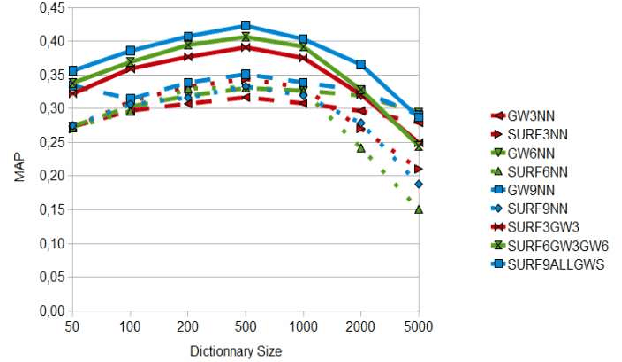
In this paper, we propose a new, scalable approach for the task of object based image search or object recognition. Despite the very large literature existing on the scalability issues in CBIR in the sense of retrieval approaches, the scalability of media and scalability of features remain an issue. In our work we tackle the problem of scalability and structural organization of features. The proposed features are nested local graphs built upon sets of SURF feature points with Delaunay triangulation. A Bag-of-Visual-Words (BoVW) framework is applied on these graphs, giving birth to a Bag-of-Graph-Words representation. The nested nature of the descriptors consists in scaling from trivial Delaunay graphs - isolated feature points - by increasing the number of nodes layer by layer up to graphs with maximal number of nodes. For each layer of graphs its proper visual dictionary is built. The experiments conducted on the SIVAL data set reveal that the graph features at different layers exhibit complementary performances on the same content. The nested approach, the combination of all existing layers, yields significant improvement of the object recognition performance compared to single level approaches.
Human Daily Activities Indexing in Videos from Wearable Cameras for Monitoring of Patients with Dementia Diseases
Jul 23, 2010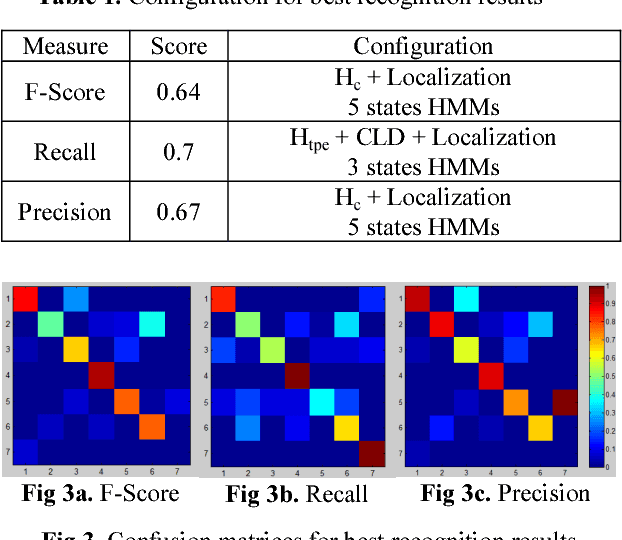

Our research focuses on analysing human activities according to a known behaviorist scenario, in case of noisy and high dimensional collected data. The data come from the monitoring of patients with dementia diseases by wearable cameras. We define a structural model of video recordings based on a Hidden Markov Model. New spatio-temporal features, color features and localization features are proposed as observations. First results in recognition of activities are promising.