 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping a Thailand solar irradiance map using Himawari-8 satellite imageries and deep learning models
Sep 21, 2024



This paper presents an online platform that shows Thailand's solar irradiance map every 30 minutes. It is available at https://www.cusolarforecast.com. The methodology for estimating global horizontal irradiance (GHI) across Thailand relies on cloud index extracted from Himawari-8 satellite imagery, Ineichen clear-sky model with locally-tuned Linke turbidity, and machine learning models. The methods take clear-sky irradiance, cloud index, re-analyzed GHI and temperature data from the MERRA-2 database, and date-time as inputs for GHI estimation models, including LightGBM, LSTM, Informer, and Transformer. These are benchmarked with the estimate from the SolCast service by evaluation of 15-minute ground GHI data from 53 ground stations over 1.5 years during 2022-2023. The results show that the four models have competitive performances and outperform the SolCast service. The best model is LightGBM, with an MAE of 78.58 W/sqm and RMSE of 118.97 W/sqm. Obtaining re-analyzed MERRA-2 data for Thailand is not economically feasible for deployment. When removing these features, the Informer model has a winning performance of 78.67 W/sqm in MAE. The obtained performance aligns with existing literature by taking the climate zone and time granularity of data into consideration. As the map shows an estimate of GHI over 93,000 grids with a frequent update, the paper also describes a computational framework for displaying the entire map. It tests the runtime performance of deep learning models in the GHI estimation process.
SalNAS: Efficient Saliency-prediction Neural Architecture Search with self-knowledge distillation
Jul 29, 2024



Recent advancements in deep convolutional neural networks have significantly improved the performance of saliency prediction. However, the manual configuration of the neural network architectures requires domain knowledge expertise and can still be time-consuming and error-prone. To solve this, we propose a new Neural Architecture Search (NAS) framework for saliency prediction with two contributions. Firstly, a supernet for saliency prediction is built with a weight-sharing network containing all candidate architectures, by integrating a dynamic convolution into the encoder-decoder in the supernet, termed SalNAS. Secondly, despite the fact that SalNAS is highly efficient (20.98 million parameters), it can suffer from the lack of generalization. To solve this, we propose a self-knowledge distillation approach, termed Self-KD, that trains the student SalNAS with the weighted average information between the ground truth and the prediction from the teacher model. The teacher model, while sharing the same architecture, contains the best-performing weights chosen by cross-validation. Self-KD can generalize well without the need to compute the gradient in the teacher model, enabling an efficient training system. By utilizing Self-KD, SalNAS outperforms other state-of-the-art saliency prediction models in most evaluation rubrics across seven benchmark datasets while being a lightweight model. The code will be available at https://github.com/chakkritte/SalNAS
* Published in Engineering Applications of Artificial Intelligence
Explainable Knowledge Distillation for On-device Chest X-Ray Classification
May 10, 2023



Automated multi-label chest X-rays (CXR) image classification has achieved substantial progress in clinical diagnosis via utilizing sophisticated deep learning approaches. However, most deep models have high computational demands, which makes them less feasible for compact devices with low computational requirements. To overcome this problem, we propose a knowledge distillation (KD) strategy to create the compact deep learning model for the real-time multi-label CXR image classification. We study different alternatives of CNNs and Transforms as the teacher to distill the knowledge to a smaller student. Then, we employed explainable artificial intelligence (XAI) to provide the visual explanation for the model decision improved by the KD. Our results on three benchmark CXR datasets show that our KD strategy provides the improved performance on the compact student model, thus being the feasible choice for many limited hardware platforms. For instance, when using DenseNet161 as the teacher network, EEEA-Net-C2 achieved an AUC of 83.7%, 87.1%, and 88.7% on the ChestX-ray14, CheXpert, and PadChest datasets, respectively, with fewer parameters of 4.7 million and computational cost of 0.3 billion FLOPS.
Efficient Linear Attention for Fast and Accurate Keypoint Matching
Apr 22, 2022
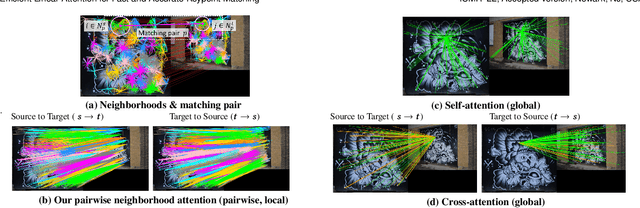
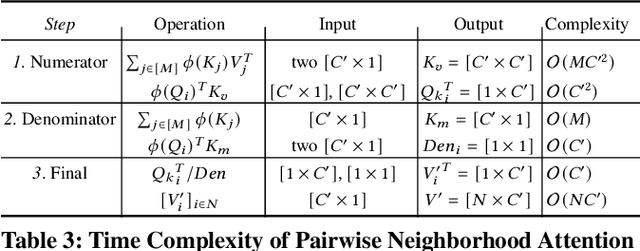
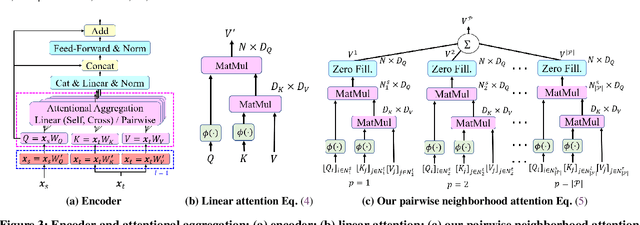
Recently Transformers have provided state-of-the-art performance in sparse matching, crucial to realize high-performance 3D vision applications. Yet, these Transformers lack efficiency due to the quadratic computational complexity of their attention mechanism. To solve this problem, we employ an efficient linear attention for the linear computational complexity. Then, we propose a new attentional aggregation that achieves high accuracy by aggregating both the global and local information from sparse keypoints. To further improve the efficiency, we propose the joint learning of feature matching and description. Our learning enables simpler and faster matching than Sinkhorn, often used in matching the learned descriptors from Transformers. Our method achieves competitive performance with only 0.84M learnable parameters against the bigger SOTAs, SuperGlue (12M parameters) and SGMNet (30M parameters), on three benchmarks, HPatch, ETH, and Aachen Day-Night.