 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Retrieval for Product Search in E-Commerce
May 31, 2026Semantic retrieval in e-commerce must handle short, noisy, and colloquial queries over large product catalogs with fine-grained attribute distinctions. We present a Siamese LLM dual-encoder trained through a two-stage pipeline: contrastive learning with a false-negative margin mask to prevent penalization of near-duplicate products, followed by Relative Odds Alignment for Retrieval (ROAR), a preference optimization objective that extends Bradley-Terry to variable-sized graded relevance groups via consecutive odds-ratio margins. The training corpus mirrors this progression - substitute query-product pairs provide coarse semantic supervision in Stage 1 and graded relevance annotations drive fine-grained ranking in Stage 2. The resulting system accurately retrieves exact matches while correctly ordering substitutes and complementary products, with gains confirmed across query-frequency strata and business verticals, and statistical significance validated through live A/B deployment at scale.
Using Large Pretrained Language Models for Answering User Queries from Product Specifications
May 29, 2020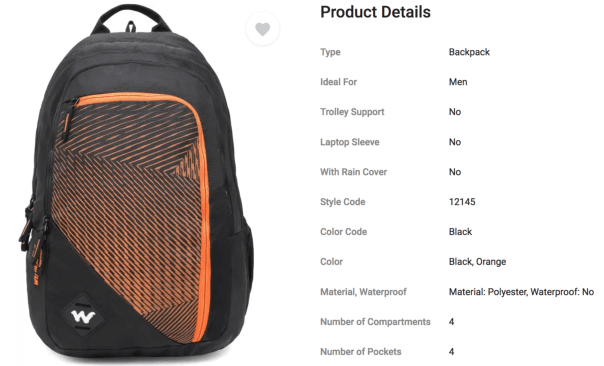
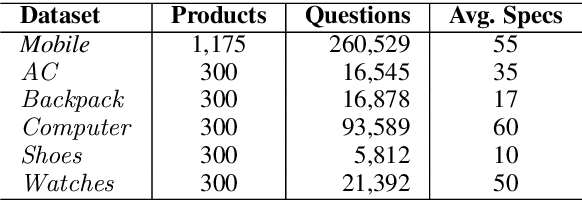
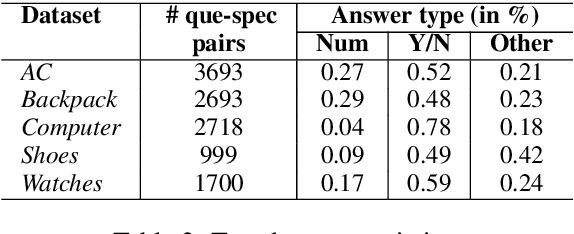
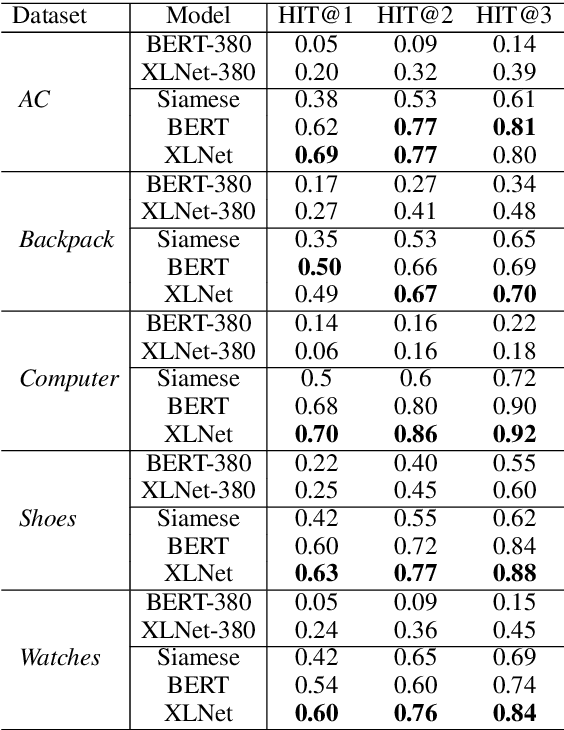
While buying a product from the e-commerce websites, customers generally have a plethora of questions. From the perspective of both the e-commerce service provider as well as the customers, there must be an effective question answering system to provide immediate answers to the user queries. While certain questions can only be answered after using the product, there are many questions which can be answered from the product specification itself. Our work takes a first step in this direction by finding out the relevant product specifications, that can help answering the user questions. We propose an approach to automatically create a training dataset for this problem. We utilize recently proposed XLNet and BERT architectures for this problem and find that they provide much better performance than the Siamese model, previously applied for this problem. Our model gives a good performance even when trained on one vertical and tested across different verticals.