 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVA: Context-aware Video-text Alignment for Video Temporal Grounding
Mar 26, 2026We propose Context-aware Video-text Alignment (CVA), a novel framework to address a significant challenge in video temporal grounding: achieving temporally sensitive video-text alignment that remains robust to irrelevant background context. Our framework is built on three key components. First, we propose Query-aware Context Diversification (QCD), a new data augmentation strategy that ensures only semantically unrelated content is mixed in. It builds a video-text similarity-based pool of replacement clips to simulate diverse contexts while preventing the ``false negative" caused by query-agnostic mixing. Second, we introduce the Context-invariant Boundary Discrimination (CBD) loss, a contrastive loss that enforces semantic consistency at challenging temporal boundaries, making their representations robust to contextual shifts and hard negatives. Third, we introduce the Context-enhanced Transformer Encoder (CTE), a hierarchical architecture that combines windowed self-attention and bidirectional cross-attention with learnable queries to capture multi-scale temporal context. Through the synergy of these data-centric and architectural enhancements, CVA achieves state-of-the-art performance on major VTG benchmarks, including QVHighlights and Charades-STA. Notably, our method achieves a significant improvement of approximately 5 points in Recall@1 (R1) scores over state-of-the-art methods, highlighting its effectiveness in mitigating false negatives.
MonoFormer: Towards Generalization of self-supervised monocular depth estimation with Transformers
May 23, 2022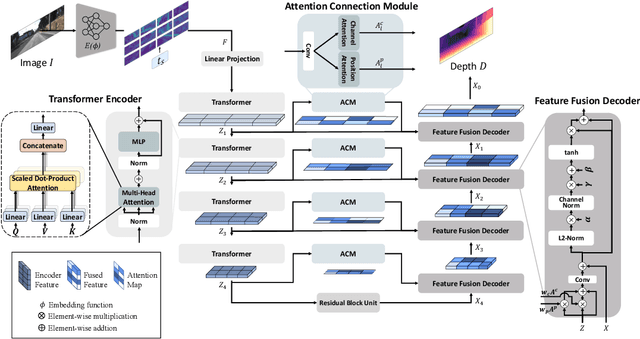
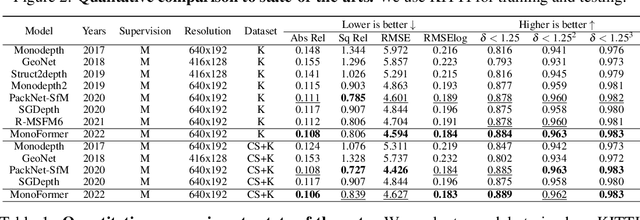

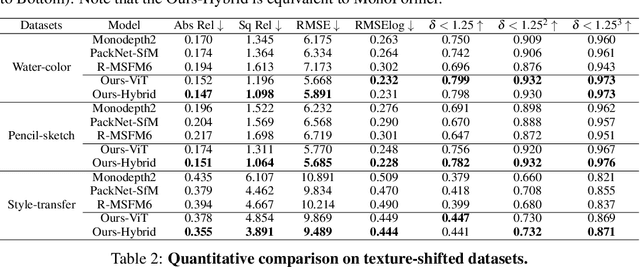
Self-supervised monocular depth estimation has been widely studied recently. Most of the work has focused on improving performance on benchmark datasets, such as KITTI, but has offered a few experiments on generalization performance. In this paper, we investigate the backbone networks (e.g. CNNs, Transformers, and CNN-Transformer hybrid models) toward the generalization of monocular depth estimation. We first evaluate state-of-the-art models on diverse public datasets, which have never been seen during the network training. Next, we investigate the effects of texture-biased and shape-biased representations using the various texture-shifted datasets that we generated. We observe that Transformers exhibit a strong shape bias and CNNs do a strong texture-bias. We also find that shape-biased models show better generalization performance for monocular depth estimation compared to texture-biased models. Based on these observations, we newly design a CNN-Transformer hybrid network with a multi-level adaptive feature fusion module, called MonoFormer. The design intuition behind MonoFormer is to increase shape bias by employing Transformers while compensating for the weak locality bias of Transformers by adaptively fusing multi-level representations. Extensive experiments show that the proposed method achieves state-of-the-art performance with various public datasets. Our method also shows the best generalization ability among the competitive methods.