 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quantitative Evaluation Framework for Missing Value Imputation Algorithms
Nov 10, 2013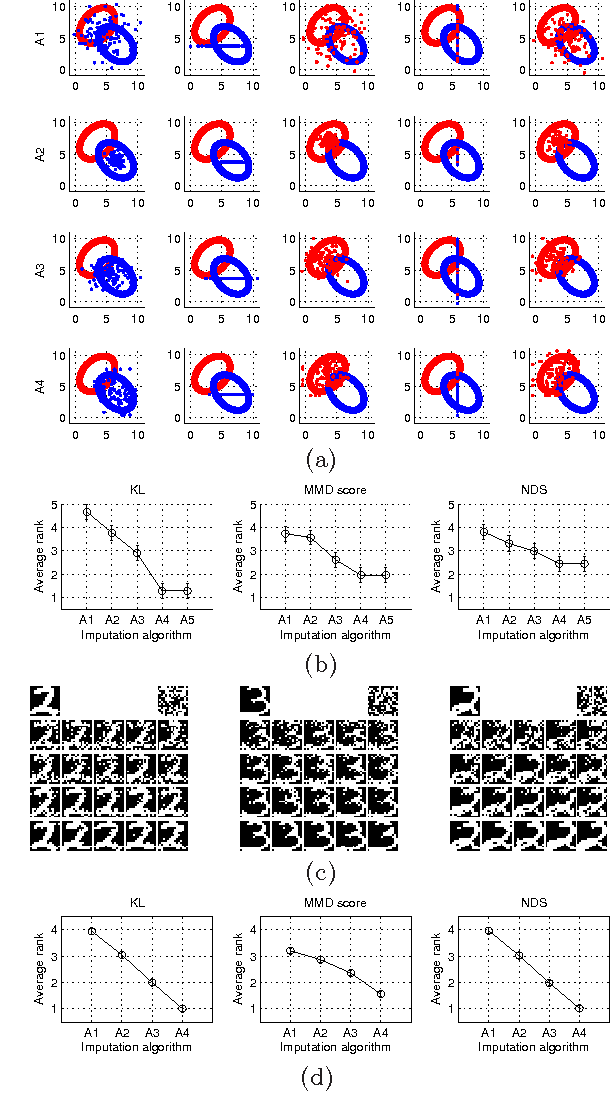
We consider the problem of quantitatively evaluating missing value imputation algorithms. Given a dataset with missing values and a choice of several imputation algorithms to fill them in, there is currently no principled way to rank the algorithms using a quantitative metric. We develop a framework based on treating imputation evaluation as a problem of comparing two distributions and show how it can be used to compute quantitative metrics. We present an efficient procedure for applying this framework to practical datasets, demonstrate several metrics derived from the existing literature on comparing distributions, and propose a new metric called Neighborhood-based Dissimilarity Score which is fast to compute and provides similar results. Results are shown on several datasets, metrics, and imputations algorithms.
Large Margin Semi-supervised Structured Output Learning
Nov 09, 2013
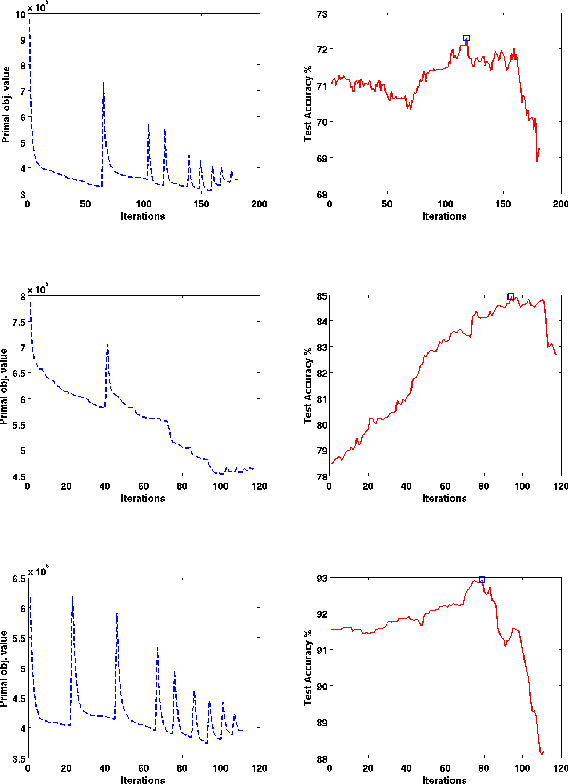

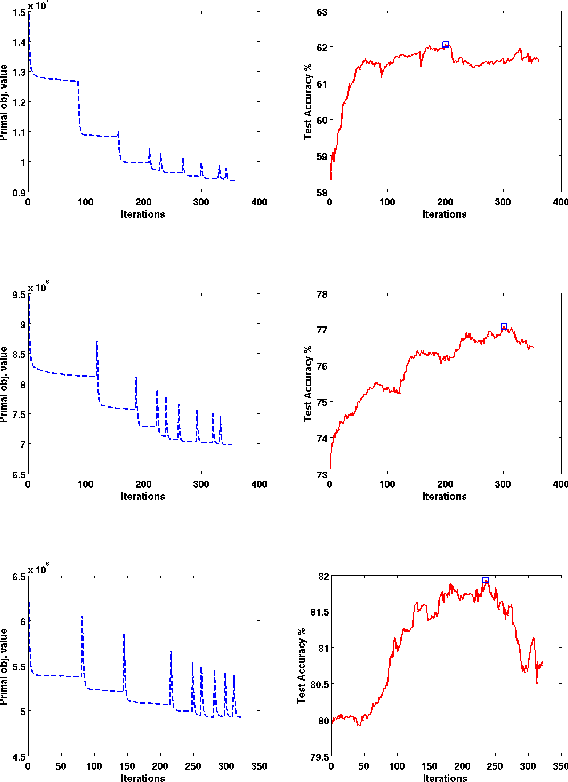
In structured output learning, obtaining labelled data for real-world applications is usually costly, while unlabelled examples are available in abundance. Semi-supervised structured classification has been developed to handle large amounts of unlabelled structured data. In this work, we consider semi-supervised structural SVMs with domain constraints. The optimization problem, which in general is not convex, contains the loss terms associated with the labelled and unlabelled examples along with the domain constraints. We propose a simple optimization approach, which alternates between solving a supervised learning problem and a constraint matching problem. Solving the constraint matching problem is difficult for structured prediction, and we propose an efficient and effective hill-climbing method to solve it. The alternating optimization is carried out within a deterministic annealing framework, which helps in effective constraint matching, and avoiding local minima which are not very useful. The algorithm is simple to implement and achieves comparable generalization performance on benchmark datasets.
A Structured Prediction Approach for Missing Value Imputation
Nov 09, 2013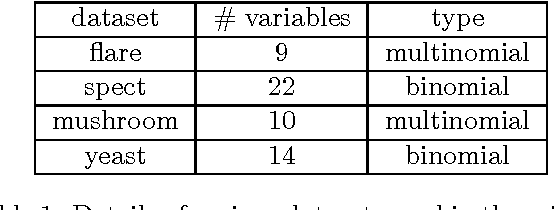
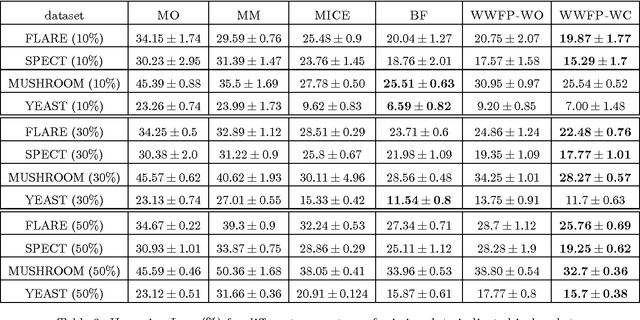
Missing value imputation is an important practical problem. There is a large body of work on it, but there does not exist any work that formulates the problem in a structured output setting. Also, most applications have constraints on the imputed data, for example on the distribution associated with each variable. None of the existing imputation methods use these constraints. In this paper we propose a structured output approach for missing value imputation that also incorporates domain constraints. We focus on large margin models, but it is easy to extend the ideas to probabilistic models. We deal with the intractable inference step in learning via a piecewise training technique that is simple, efficient, and effective. Comparison with existing state-of-the-art and baseline imputation methods shows that our method gives significantly improved performance on the Hamming loss measure.
Extension of TSVM to Multi-Class and Hierarchical Text Classification Problems With General Losses
Nov 01, 2012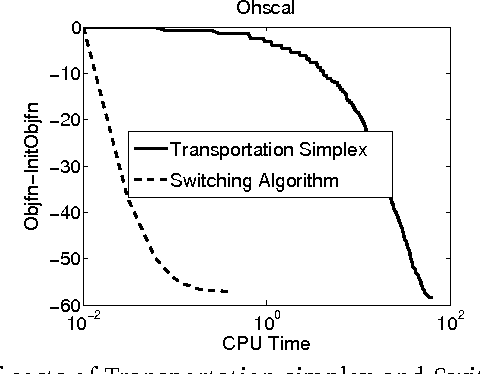

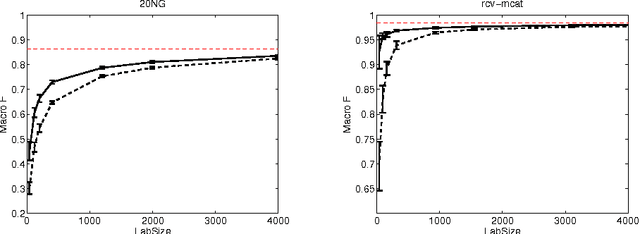
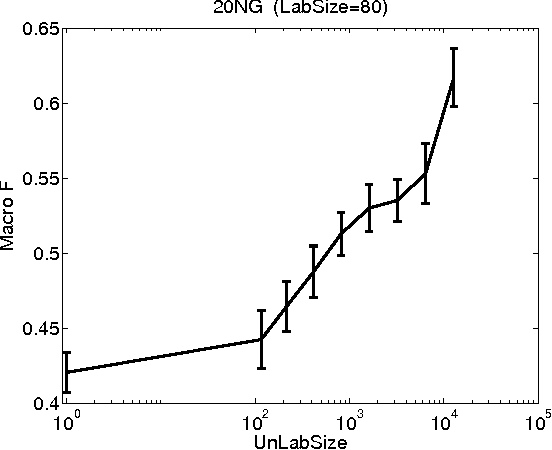
Transductive SVM (TSVM) is a well known semi-supervised large margin learning method for binary text classification. In this paper we extend this method to multi-class and hierarchical classification problems. We point out that the determination of labels of unlabeled examples with fixed classifier weights is a linear programming problem. We devise an efficient technique for solving it. The method is applicable to general loss functions. We demonstrate the value of the new method using large margin loss on a number of multi-class and hierarchical classification datasets. For maxent loss we show empirically that our method is better than expectation regularization/constraint and posterior regularization methods, and competitive with the version of entropy regularization method which uses label constraints.
Predictive Approaches For Gaussian Process Classifier Model Selection
Jun 26, 2012
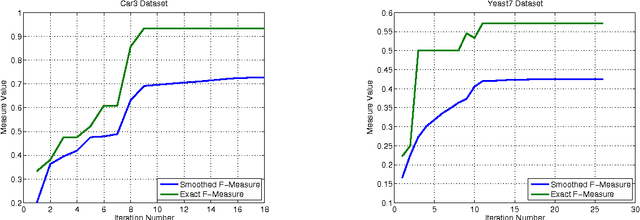

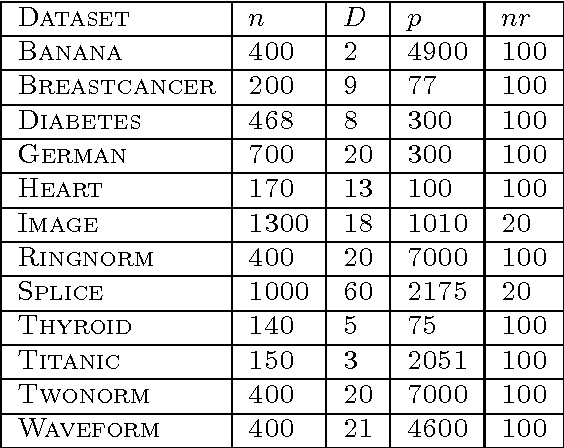
In this paper we consider the problem of Gaussian process classifier (GPC) model selection with different Leave-One-Out (LOO) Cross Validation (CV) based optimization criteria and provide a practical algorithm using LOO predictive distributions with such criteria to select hyperparameters. Apart from the standard average negative logarithm of predictive probability (NLP), we also consider smoothed versions of criteria such as F-measure and Weighted Error Rate (WER), which are useful for handling imbalanced data. Unlike the regression case, LOO predictive distributions for the classifier case are intractable. We use approximate LOO predictive distributions arrived from Expectation Propagation (EP) approximation. We conduct experiments on several real world benchmark datasets. When the NLP criterion is used for optimizing the hyperparameters, the predictive approaches show better or comparable NLP generalization performance with existing GPC approaches. On the other hand, when the F-measure criterion is used, the F-measure generalization performance improves significantly on several datasets. Overall, the EP-based predictive algorithm comes out as an excellent choice for GP classifier model selection with different optimization criteria.
An Additive Model View to Sparse Gaussian Process Classifier Design
Jun 26, 2012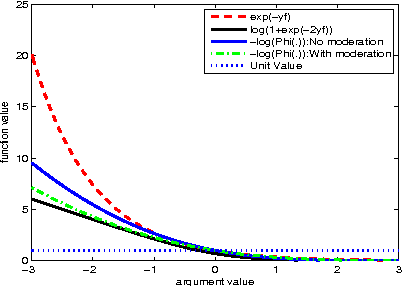
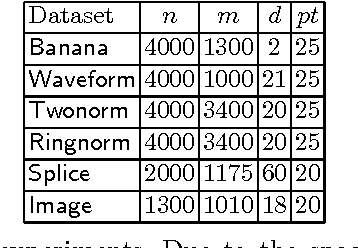
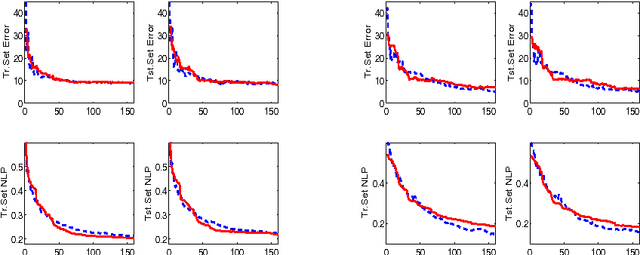
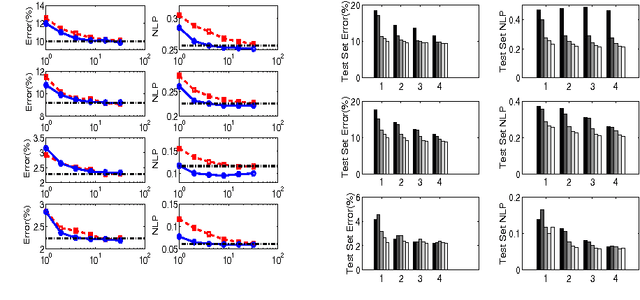
We consider the problem of designing a sparse Gaussian process classifier (SGPC) that generalizes well. Viewing SGPC design as constructing an additive model like in boosting, we present an efficient and effective SGPC design method to perform a stage-wise optimization of a predictive loss function. We introduce new methods for two key components viz., site parameter estimation and basis vector selection in any SGPC design. The proposed adaptive sampling based basis vector selection method aids in achieving improved generalization performance at a reduced computational cost. This method can also be used in conjunction with any other site parameter estimation methods. It has similar computational and storage complexities as the well-known information vector machine and is suitable for large datasets. The hyperparameters can be determined by optimizing a predictive loss function. The experimental results show better generalization performance of the proposed basis vector selection method on several benchmark datasets, particularly for relatively smaller basis vector set sizes or on difficult datasets.
Transductive Classification Methods for Mixed Graphs
Jun 26, 2012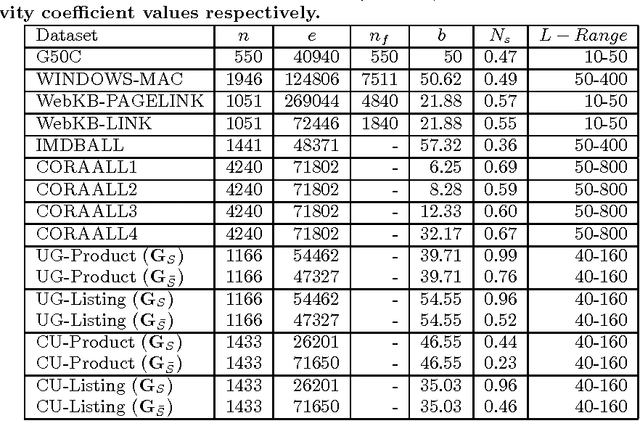
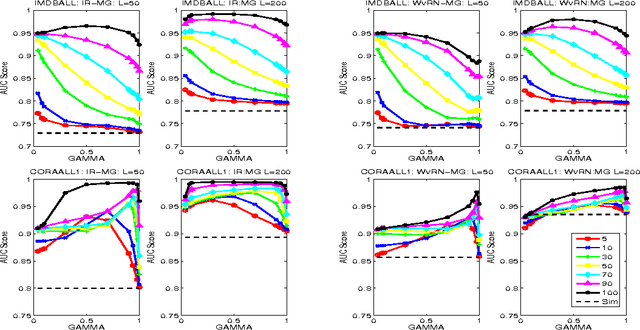
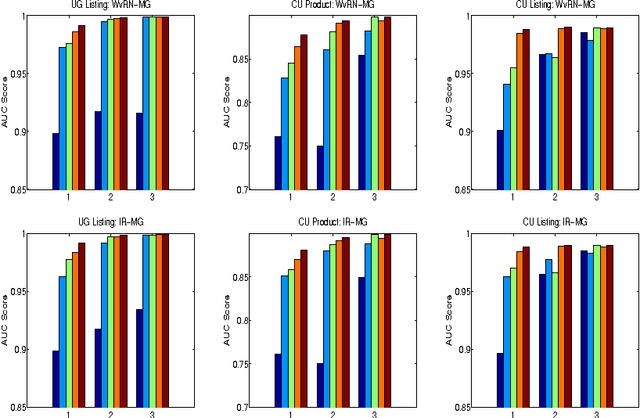
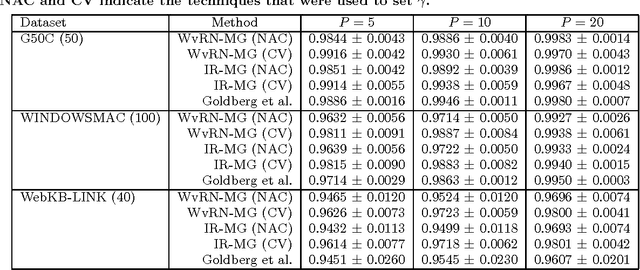
In this paper we provide a principled approach to solve a transductive classification problem involving a similar graph (edges tend to connect nodes with same labels) and a dissimilar graph (edges tend to connect nodes with opposing labels). Most of the existing methods, e.g., Information Regularization (IR), Weighted vote Relational Neighbor classifier (WvRN) etc, assume that the given graph is only a similar graph. We extend the IR and WvRN methods to deal with mixed graphs. We evaluate the proposed extensions on several benchmark datasets as well as two real world datasets and demonstrate the usefulness of our ideas.
Graph Based Classification Methods Using Inaccurate External Classifier Information
Jun 26, 2012
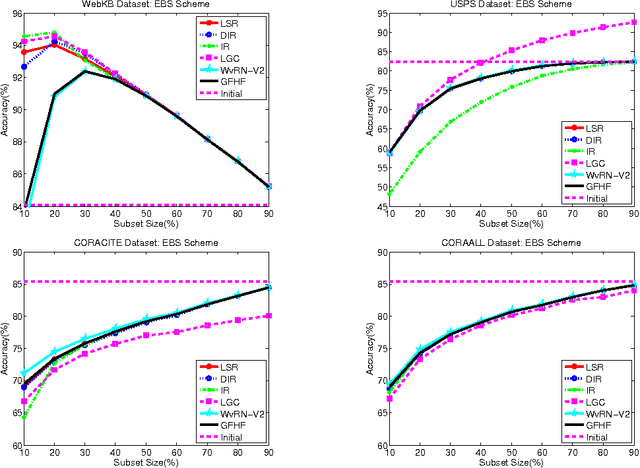
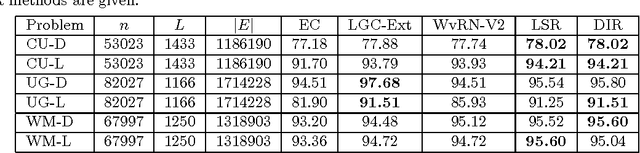
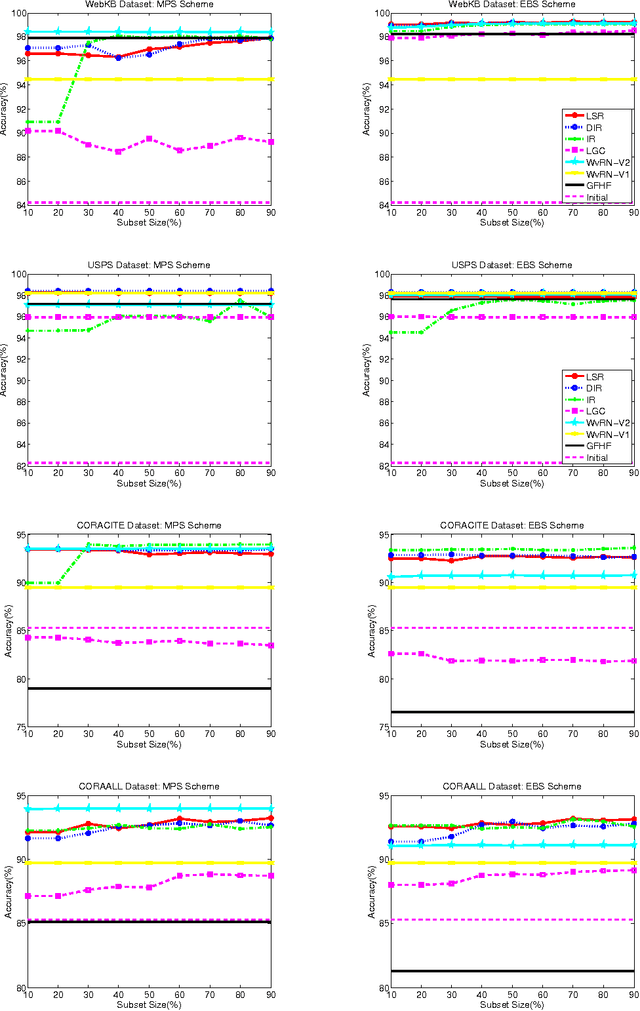
In this paper we consider the problem of collectively classifying entities where relational information is available across the entities. In practice inaccurate class distribution for each entity is often available from another (external) classifier. For example this distribution could come from a classifier built using content features or a simple dictionary. Given the relational and inaccurate external classifier information, we consider two graph based settings in which the problem of collective classification can be solved. In the first setting the class distribution is used to fix labels to a subset of nodes and the labels for the remaining nodes are obtained like in a transductive setting. In the other setting the class distributions of all nodes are used to define the fitting function part of a graph regularized objective function. We define a generalized objective function that handles both the settings. Methods like harmonic Gaussian field and local-global consistency (LGC) reported in the literature can be seen as special cases. We extend the LGC and weighted vote relational neighbor classification (WvRN) methods to support usage of external classifier information. We also propose an efficient least squares regularization (LSR) based method and relate it to information regularization methods. All the methods are evaluated on several benchmark and real world datasets. Considering together speed, robustness and accuracy, experimental results indicate that the LSR and WvRN-extension methods perform better than other methods.